1. 概述
1.1. ELK简介
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
通过上面对ELK简单的介绍,我们知道了ELK字面意义包含的每个开源框架的功能。市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。我们本教程主要也是围绕通过ELK如何搭建一个生产级的日志分析平台来讲解ELK的使用。
1.2. ELK架构
ELK的搭建有多种架构方式,我们系统采用的架构方式如下:
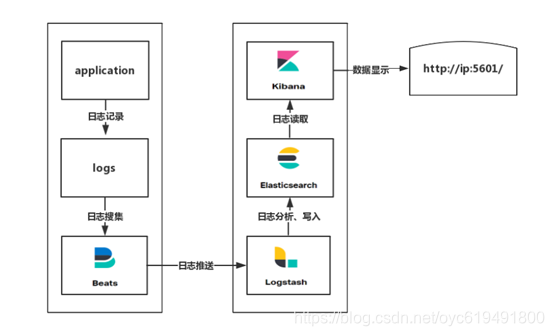
1.3. ELK运行环境
- 操作系统:CentOS/RHEL 6.x/7.x、Ubuntu16.04等系统,具体参考:https://www.elastic.co/cn/support/matrix
- JDK版本:建议JDK8或JDK11,需要配置好环境变量,具体参考: https://www.elastic.co/cn/support/matrix#matrix_jvm
- 主机运行内存8G及以上为佳,最理想是64G,CPU常用2-8核,具体参考: https://www.elastic.co/guide/en/elasticsearch/guide/master/hardware.html#_cpus
- 本示例基于 CentOS7.5-64Bit + JDK 1.8.0_221 + 4C8G 主机搭建
2. Elasticsearch(ES)
2.1. ES安装
参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.1/getting-started-install.html (注:页面右边菜单栏Release notes 可看到各版本信息,目前最新版本7.5)
- root用户登录到主机
- 进入目录: cd /usr/local
- 下载:curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.1-linux-x86_64.tar.gz
- 解压: tar -xvf elasticsearch-7.1.1-linux-x86_64.tar.gz
- 重命名: mv elasticsearch-7.1.1-linux-x86_64 elasticsearch
- 创建用户,并将ES安装权限归新用户所有:
useradd francis
passwd 123456
chown -R francis:francis /usr/local/elasticsearch/
2.2. ES配置及启停
参考文档: https://www.elastic.co/guide/en/elasticsearch/reference/7.1/settings.html
2.2.1. 配置
- 进入配置文件目录 cd /usr/local/elasticsearch/config
- 编辑文件 vim elasticsearch.yml
- 编辑以下配置:
单节点模式:
cluster.name: francis-es # es集群名字,可用默认值
node.name: node01 # 当前es节点名字,可用默认值
network.host: 192.168.2.101 # ip地址,可配为0.0.0.0
http.port: 9200 # es服务的端口号,可用默认值
集群模式:
分别配置每个节点的elasticsearch.yml
cluster.name: francis-es # es集群名字
node.name: node01 # es节点名字,node01/node02/node03
node.master: true # 指定该节点是否有资格被选举成为master,默认是true
node.data: true # 指定该节点是否存储索引数据,默认为true
network.host: 192.168.2.101 # ip地址,192.168.2.101/192.168.2.102/192.168.2.103
http.port: 9200 # es服务的端口号
discovery.zen.ping.unicast.hosts: [“192.168.2.101”, “192.168.2.102”, “192.168.2.103”] # 配置自动发现
discovery.zen.minimum_master_nodes: 2 # 最少N个有master资格的节点,默认为1
可选配置:
index.number_of_shards: 5
设置默认索引分片个数,默认为5片。
index.number_of_replicas: 1
设置默认索引副本个数,默认为1个副本。
path.conf: /path/to/conf
设置配置文件的存储路径,默认是es根目录下的config文件夹。
path.data: /path/to/data
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:
path.data: /path/to/data1,/path/to/data2
path.work: /path/to/work
设置临时文件的存储路径,默认是es根目录下的work文件夹。
path.logs: /path/to/logs
设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins: /path/to/plugins
设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.mlockall: true
设置为true来锁住内存。因为当jvm开始swapping时es的效率 会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。 同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过ulimit -l unlimited命令。
network.bind_host: 192.168.2.101
设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
network.publish_host: 192.168.2.101
设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.host: 192.168.2.101
这个参数是用来同时设置bind_host和publish_host上面两个参数。
transport.tcp.port: 9300
设置节点间交互的tcp端口,默认是9300。
transport.tcp.compress: true
设置是否压缩tcp传输时的数据,默认为false,不压缩。
http.port: 9200
设置对外服务的http端口,默认为9200。
http.max_content_length: 100mb
设置内容的最大容量,默认100mb
http.enabled: false
是否使用http协议对外提供服务,默认为true,开启。
gateway.type: local
gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。
gateway.recover_after_nodes: 1
设置集群中N个节点启动时进行数据恢复,默认为1。
gateway.recover_after_time: 5m
设置初始化数据恢复进程的超时时间,默认是5分钟。
gateway.expected_nodes: 2
设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
cluster.routing.allocation.node_initial_primaries_recoveries: 4
初始化数据恢复时,并发恢复线程的个数,默认为4。
cluster.routing.allocation.node_concurrent_recoveries: 2
添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
indices.recovery.max_size_per_sec: 0
设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
indices.recovery.concurrent_streams: 5
设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
discovery.zen.minimum_master_nodes: 1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.ping.timeout: 3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.ping.multicast.enabled: false
设置是否打开多播发现节点,默认是true。
discovery.zen.ping.unicast.hosts: [“host1”, “host2:port”, “host3[portX-portY]”]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
4. 可在安装目录的config/目录下编辑jvm.options设置es所需的堆内存,默认1G
5. 官方建议不要随意动这些配置,具体参考: https://www.elastic.co/guide/en/elasticsearch/guide/master/_don_8217_t_touch_these_settings.html
6. 如果安装elasticsearch-head插件,需要在config/elasticsearch.yml中配置如下内容:
http.cors.enabled: true
http.cors.allow-origin: “*” # 解决跨域问题
2.2.2. ES启停
启动:
- 直接启动: ./bin/elasticsearch
- 后台启动:./bin/elasticsearch -d
- 测试: curl http://192.168.2.101:9200
停止:
- 查看es进程: jps | grep Elasticsearch
- 杀掉进程: kill -9 进程号
2.2.3. 问题及解决
问题1:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决方法:
- vim /etc/security/limits.conf
- 在最后面追加下面内容:
francis hard nofile 65536
francis soft nofile 65536 # francis为es安装目录的所有者
或者:
- soft nofile 65536
- hard nofile 65536 # *表示所有用户,nofile表示最大文件句柄数,表示能够打开的最大文件数目
- 修改后退出重新登录,使用如下命令查看是否修改成功:
ulimit -Hn
ulimit -Sn
问题2:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方法:
- vim /etc/sysctl.conf
- 在最后面追加内容: vm.max_map_count=262144
- 查看修改后的结果:sysctl -p
问题3:
Java HotSpot™ 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error=‘Cannot allocate memory’ (errno=12)
解决方法:
- 编辑文件 vim /usr/local/elasticsearch/config /jvm.options
- 修改以下配置,将1g变为更小的值:
-Xms1g
-Xmx1g
问题4:
max number of threads [3818] for user [es] is too low, increase to at least [4096]
解决办法:
- vim /etc/security/limits.conf
- 增加以下配置:
- soft nproc 4096
- hard nproc 4096
- 修改后退出重新登录,使用如下命令查看是否修改成功:
ulimit -Hu
ulimit -Su
问题5:
the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决方法:
- vim /usr/local/elasticsearch/config/ elasticsearch.yml
- 添加配置:cluster.initial_master_nodes: [“node01”]
问题6:
Exception in thread “main” java.nio.file.AccessDeniedException: /usr/local/elasticsearch /config/jvm.options
解决办法:
这种是权限问题,一般这种权限问题执行: chown -R francis:francis /usr/local/elasticsearch 即可解决
2.3. ES插件安装
elasticsearch-head插件是ES的Web管理端,可通过此插件来管理ES集群等。
2.3.1. 安装nodejs
elasticsearch-head插件要求Node.js环境,官网: https://nodejs.org/en/download/
- 进入目录: cd /usr/local/
- 下载: curl -L -O https://nodejs.org/dist/v12.13.1/node-v12.13.1-linux-x64.tar.xz
- 解压: tar -xvf node-v12.13.1-linux-x64.tar.xz
- 重命名:mv node-v12.13.1-linux-x64 nodejs
- 切换root用户,新增环境变量: vim /etc/profile
- 文件最后面追加:
export NODE_HOME=/usr/local/nodejs
export PATH= NODE_HOME/bin
export NODE_PATH=$NODE_HOME/lib/node_modules - 执行:source /etc/profile
- 查看是否成功: node -v 输出版本号即成功
2.3.2. 安装elasticsearch-head
参考文档: https://github.com/mobz/elasticsearch-head/
- 查看是否安装git: rpm -qa | grep git
- 如果未安装则先安装:yum install git
- 进入目录: cd /usr/local
- 下载插件: git clone https://github.com/mobz/elasticsearch-head.git
- 改变权限:chown -R francis:francis /usr/local/elasticsearch-head/
- 修改es配置,文件最后追加:vim /usr/local/elasticsearch/config/elasticsearch.yml
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: ""
7. 重启es
8. npm install -g grunt-cli
9. npm install [email protected] --ignore-scripts (不执行可能会报错)
10. npm install
11. vim /usr/local/elasticsearch-head/_site/app.js
12. 命令行模式下搜索:this.base_uri,修改为:this.base_uri = this.config.base_uri || this.prefs.get(“app-base_uri”) || “http://192.168.2.101:9200”;
13. vim /usr/local/elasticsearch-head/Gruntfile.js
在port: 9100 上面加一行配置:
hostname: ‘192.168.2.101’, #注意后面有个逗号,后者hostname: ‘’
14. npm run start
15. 浏览器打开: http://192.168.2.101:9100/
3. FileBeat
3.1. FileBeat安装
参考文档:https://www.elastic.co/guide/en/beats/filebeat/7.1/filebeat-installation.html
- 进入安装目录:cd /usr/local
- 下载: curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.1.1-linux-x86_64.tar.gz
- 解压: tar -xvf filebeat-7.1.1-linux-x86_64.tar.gz
- 重命名: mv filebeat-7.1.1-linux-x86_64 filebeat
- 更改权限: chown -R francis:francis /usr/local/ filebeat
3.2. FileBeat配置及启停
3.2.1. 配置
- 打开配置文件: vim /usr/local/filebeat/filebeat.yml
- 编辑以下配置(注意缩进):
filebeat.inputs:
- type: log
enabled: true
paths:
- /log/francis/build/*.json # 采集logbak框架打印的json日志,推荐这种方式
#- /log/francis/*.log # 也可配置采集.log日志,日志路径为项目中所配置的路径
setup.kibana:
host: "192.168.2.101:5601"
output.logstash:
hosts: ["192.168.2.101:5044"]
setup.template.settings:
index.number_of_shards: 3
默认输出到elasticsearch,需要将output.elasticsearch 部分注释掉
3.2.2. 启停
启动:
- 进入目录: cd /usr/local/filebeat
- 执行: ./filebeat -e -c filebeat.yml -d “publish” # -e关闭日志输出,-c指定配置文件,显示所有“publish”相关的消息
- 后台启动方式: nohup ./filebeat -e -c filebeat.yml &
停止:
- ps -ef | grep filebeat
- kill -9 进程号
3.3. FileBeat多日志采集
假设有日志文件/app/logs/francis/francis.json和/app/logs/nginx/access.log,我们需要对两个目录下的文件作出不同处理
- 编辑 filebeat.yml文件,输入以下内容:
filebeat.inputs:
- type: log
enabled: true
paths:
-/app/logs/francis/francis.json
tags: [“francis”] #数组,可以输入多个,后续可以利用tags作出不同处理
fields:
filetype: json # 可以用来区分文件类型,作用和tags相似
fields_under_root: true
- type: log
enabled: true
paths:
- /app/logs/nginx/access.log
tags: [“nginx”]
fields: # 自定义字段
filetype: syslog
fields_under_root: true # 设置为true,意为将自定义字段设为文档中的顶级字段
output.logstash:
enabled: true
hosts: ["192.168.2.101:5044"]
- 编辑logstash.conf (在Logstash的config目录下)文件,输入以下内容:
input {
beats {
host => "0.0.0.0"
port => 5044
}
}
filter {
if [filetype] == "json" {
json {
source => "message"
remove_field => ["beat","offset","tags"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
if [filetype] == "syslog" {
#处理逻辑
}
if “francis”in [tags] {
#处理逻辑
}
}
output {
if [filetype] == "syslog" {
elasticsearch {
hosts => ["192.168.2.101:9200"]
index => "test-nginx-%{+YYYY.MM.dd}"
}
} else if [filetype] == "json" {
elasticsearch {
hosts => ["192.168.2.101:9200"]
index => "test-francis -%{+YYYY.MM.dd}"
}
}
}
注:在后续Kibana上建立Index Pattern时,如果index pattern一栏输入test-*,那么上述两个index都能匹配上,如果所有应用打印日志的格式一致时,可以使用这种方式,避免重复建立index pattern,查看时可以根据应用名来筛选本应用的日志,这个可以根据实际需求而定。
4. Logstash
4.1. Logstash安装
参考文档: https://www.elastic.co/guide/en/logstash/7.1/installing-logstash.html
- 进入安装目录: cd /usr/local
- 下载: curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-7.1.1.tar.gz
- 解压: tar -xvf logstash-7.1.1.tar.gz
- 重命名:mv logstash-7.1.1 logstash
- 修改权限:chown -R francis:francis /usr/local/ logstash
4.2. Logstash配置及启停
4.2.1. 配置
进入配置文件目录: cd /usr/local/logstash/config,两种格式日志解析一种即可,推荐解析json格式日志
4.2.1.1. 解析json日志
- 创建文件:touch logstash.conf
- 打开文件:vim logstash.conf
- 输入以下内容:
input {
#beat插件,监听5044端口
beats {
port => "5044"
}
}
filter {
#我们filebeat采集的是json格式的文件,然后会把日志存于message字段中,我们使用json插件解析message字段
json {
source => "message"
}
#将@timestamp替换为打印日志的时间,默认是采集日志的时间
date{
match => ["logTime ", "YYYY-MM-dd HH:mm:ss.SSS", "ISO8601"]
}
#使用mutate插件,将message的内容替换为rest+ stackTrace,rest等字段跟logbak-spring.xml中配置的保持一致就行了,字段命名可以跟示例不同
mutate {
replace => { "message" => "%{rest}%{stackTrace}" }
}
#使用插件删除你不想要显示在kibana中的字段
mutate {
remove_field => [ “logTime”, "rest", "stackTrace", "@version", "agent", "host", "input", "ecs", "log" ]
}
}
#输出到es
output {
elasticsearch {
# 可以输入多个es地址
hosts => ["http://192.168.2.101:9200"]
#存于es中的索引,在kibana中创建索引的时候,你可以输入test-*、test-francis-*等来匹配这个索引,默认logstash-%{+YYYY.MM.dd}
index => "test-francis-%{+YYYY.MM.dd}"
}
}
- 日志示例:
{"@timestamp":“2019-12-08T16:58:35.703+00:00”,“logTime”:“2019-12-09 00:58:35.703”,“logLevel”:“ERROR”,“appName”:“francis”,“traceId”:“1f1a5a07b41d00ca”,“spanId”:“1f1a5a07b41d00ca”,“parentId”:"",“exportable”:“false”,“pid”:“5604”,“thread”:“http-nio-8081-exec-6”,“class”:“com.example.demo.aspect.LogAspect”,“rest”:“com.example.demo.controller.StudentController.error 请求异常,原因:”,“stackTrace”:“java.lang.NullPointerException: null\r\n\tat com.example.demo.controller.StudentController.error(StudentController.java:32)\r\n\tat com.example.demo.controller.StudentController 7356fabf.invoke()\r\n\tat org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)\r\n\tat org.springframework.aop.framework.CglibAopProxyKaTeX parse error: Can't use function '\r' in math mode at position 62: …Proxy.java:769)\̲r̲\n\tat org.spri…CglibMethodInvocation.proceed(CglibAopProxy.java:747)\r\n\tat org.springframework.aop.framework.adapter.MethodBeforeAdviceInterceptor.invoke(MethodBeforeAdviceInterceptor.java:56)\r\n\tat org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)\r\n\tat org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:747)\r\n\tat org.springframework.aop.framework.adapter.AfterReturningAdviceInterceptor.invoke(AfterReturningAdviceInterceptor.java:55)\r\n”}
标红的字段都是在logback-spring.xml文件中定义的输出到json文件的字段,logstash.conf中可以在filter中使用插件对这些字段做出处理
3.2.1.2. 解析.log日志 - 创建并打开文件:vim logstash-log.conf,输入:
input {
#beat插件,监听5044端口
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
output {
#输出到控制台,这里不再示例输出到es
stdout{codec=>rubydebug}
}
- 打开文件: vim /usr/local/filebeat/filebeat.yml 加入以下配置:
multiline.pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
multiline.negate: false
multiline.match: after
- 重启filebeat
- 日志示例:
2019-12-10 21:42:17.499 ERROR [francis,e3fd0174607db6bb,e3fd0174607db6bb,false] 1364 — [nio-8081-exec-1] com.example.demo.aspect.LogAspect : com.example.demo.controller.StudentController.error 请求异常,原因:
java.lang.NullPointerException: null
at com.example.demo.controller.StudentController.error(StudentController.java:38)
at com.example.demo.controller.StudentController
7356fabf.invoke()
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)
at org.springframework.aop.framework.CglibAopProxy
CglibMethodInvocation.proceed(CglibAopProxy.java:747)
at org.springframework.aop.framework.adapter.MethodBeforeAdviceInterceptor.invoke(MethodBeforeAdviceInterceptor.java:56)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at org.springframework.aop.framework.CglibAopProxy
CglibMethodInvocation.proceed(CglibAopProxy.java:747)
at org.springframework.aop.aspectj.AspectJAfterThrowingAdvice.invoke(AspectJAfterThrowingAdvice.java:62)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at org.springframework.aop.framework.CglibAopProxy
CglibMethodInvocation.proceed(CglibAopProxy.java:747)
at org.springframework.aop.framework.CglibAopProxy
LazyTracingFilter.doFilter(TraceWebServletAutoConfiguration.java:143)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.apache.catalina.core.ApplicationDispatcher.invoke(ApplicationDispatcher.java:712)
at org.apache.catalina.core.ApplicationDispatcher.processRequest(ApplicationDispatcher.java:461)
at org.apache.catalina.core.ApplicationDispatcher.doForward(ApplicationDispatcher.java:384)
at org.apache.catalina.core.ApplicationDispatcher.forward(ApplicationDispatcher.java:312)
at org.apache.catalina.core.StandardHostValve.custom(StandardHostValve.java:394)
at org.apache.catalina.core.StandardHostValve.status(StandardHostValve.java:253)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:175)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:74)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:343)
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:408)
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66)
at org.apache.coyote.AbstractProtocol
SocketProcessor.doRun(NioEndpoint.java:1579)
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor
WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)
4.2.2 启停
启动:
- 进入安装目录:cd /usr/local/logstash
- 执行: ./bin/logstash -f config/logstash.conf -r # -f指定配置文件,-r热加载
停止:
- jps | grep Logstash
- kill -9 进程号
5. Kibana
5.1. Kibana安装
参考文档: https://www.elastic.co/guide/en/kibana/current/introduction.html
- 进入安装目录: cd /usr/local
- 下载:curl -O https://artifacts.elastic.co/downloads/kibana/kibana-7.1.1-linux-x86_64.tar.gz
- 解压: tar -xvf kibana-7.1.1-linux-x86_64.tar.gz
- 重命名: mv kibana-7.1.1-linux-x86_64 kibana
- 更改权限: chown -R francis:francis /usr/local/ kibana
5.2. Kibana配置及启停
5.2.1. 配置
- 打开kibana.yml:vim /usr/local/kibana/config/kibana.yml
- 编辑以下配置并保存:
server.port: 5601 # 端口,可用默认值
server.host: “192.168.2.101” # ip地址
elasticsearch.hosts: [“http://192.168.2.101:9200”] # es集群地址,数组,可配置多个
5.2.2. 启停
参考文档: https://www.elastic.co/guide/en/kibana/current/start-stop.html
启动:
- cd /usr/local/kibana
- ./bin/kibana
停止:
- lsof -i:5601
- kill -9 进程号
6. Spring Boot接入ELK
6.1. 修改pom.xml文件
引入以下配置,日志中出现traceId等需要用到spring-cloud-sleuth
</dependencies>
<!— 如果原来已引用此jar包,项目可能起不来,加上下面标红部分 -–>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.0</version>
<scope>runtime</scope>
<!—最好直接使用5.2版本,不需要加下面这一段,5.2版本依赖里已做了这一步操作 -->
<exclusions>
<exclusion>
<artifactId>logback-core</artifactId>
<groupId>ch.qos.logback</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.1.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.6</version>
</dependency>
</dependencies>
<!— 注意不要重复添加这段 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.SR3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
6.2. 配置logback-spring.xml
- 参考文档:https://cloud.spring.io/spring-cloud-sleuth/reference/html/ 第1.2.5章节
- classpath目录下创建logback-spring.xml,如果命名为logback-spring.xml,不需要再在配置文件中指定路径。此配置文件中需要用到应用名,classpath目录添加bootstrap.yml文件并添加下面配置:
spring:
application:
name: francis
注意:不要将此配置放到application.properties或application.yml中,不会被读取。 - logback-spring.xml配置如下,注意下面加了注释的配置:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!— 参考文档上提供的CONSOLE_LOG_PATTERN可打印彩色日志,某些场景下.log文件会有格式问题,去掉彩色日志即可,也可不打印.log日志,打印json日志即可 -->
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} ${LOG_LEVEL_PATTERN:-%5p} ${PID:- } --- [%15.15t] %-40.40logger{39} : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<property name="LOG_HOME" value="./log/francis"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/francis.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 根据实际情况配置 -->
<fileNamePattern>${LOG_HOME}/francis.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- filebeat采集的就是这里配置的json日志,注意日志路径-->
<file>${LOG_HOME}/${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 根据实际情况配置 -->
<fileNamePattern>${LOG_HOME}/${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<!-- 这里配置的是输出到json文件中的内容,logstash.conf的filter可对这些字段做出处理 -->
<pattern>
{
"logLevel": "%level",
"appName": "${springAppName:-}",
"traceId": "%X{X-B3-TraceId:-}",
"spanId": "%X{X-B3-SpanId:-}",
"parentId": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"className": "%logger{40}",
"rest": "%message",
"stackTrace": "%exception{10}" # 错误日志的堆栈信息,显示10行
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<!—也可添加DEBUG、ERROR级别 -->
<root level="INFO">
<appender-ref ref="console"/>
<appender-ref ref="logstash"/>
<appender-ref ref="flatfile"/>
</root>
</configuration>
