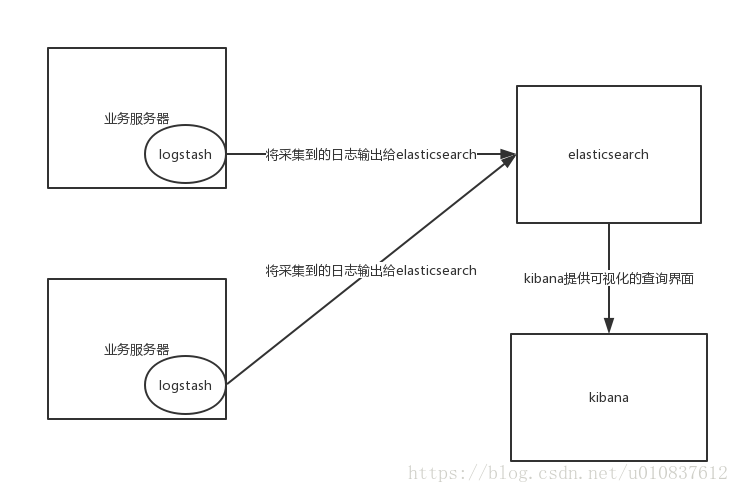
ELK架构介绍
ELK分别是ElasticSearch LogStash Kibana
他们的职责分别是:
- logstash:采集日志,输出给elasticsearch
- elasticsearch:提供搜索查询功能
- kibana:展示数据
结构如下:
本人使用的是Linux环境安装ELK
安装JDK
ELK需要JDK环境,有两种方式安装:
第一种,使用yum安装:
#查看jdk版本 yum search java|grep jdk
[root@vagrant-centos65 vagrant]# yum search java|grep jdk
ldapjdk-javadoc.x86_64 : Javadoc for ldapjdk
java-1.6.0-openjdk.x86_64 : OpenJDK Runtime Environment
java-1.6.0-openjdk-demo.x86_64 : OpenJDK Demos
java-1.6.0-openjdk-devel.x86_64 : OpenJDK Development Environment
java-1.6.0-openjdk-javadoc.x86_64 : OpenJDK API Documentation
java-1.6.0-openjdk-src.x86_64 : OpenJDK Source Bundle
java-1.7.0-openjdk.x86_64 : OpenJDK Runtime Environment
java-1.7.0-openjdk-demo.x86_64 : OpenJDK Demos
java-1.7.0-openjdk-devel.x86_64 : OpenJDK Development Environment
java-1.7.0-openjdk-javadoc.noarch : OpenJDK API Documentation
java-1.7.0-openjdk-src.x86_64 : OpenJDK Source Bundle
java-1.8.0-openjdk.x86_64 : OpenJDK Runtime Environment
java-1.8.0-openjdk-debug.x86_64 : OpenJDK Runtime Environment with full debug on
java-1.8.0-openjdk-demo.x86_64 : OpenJDK Demos
java-1.8.0-openjdk-demo-debug.x86_64 : OpenJDK Demos with full debug on
java-1.8.0-openjdk-devel.x86_64 : OpenJDK Development Environment
java-1.8.0-openjdk-devel-debug.x86_64 : OpenJDK Development Environment with
java-1.8.0-openjdk-headless.x86_64 : OpenJDK Runtime Environment
java-1.8.0-openjdk-headless-debug.x86_64 : OpenJDK Runtime Environment with full
java-1.8.0-openjdk-javadoc.noarch : OpenJDK API Documentation
java-1.8.0-openjdk-javadoc-debug.noarch : OpenJDK API Documentation for packages
java-1.8.0-openjdk-src.x86_64 : OpenJDK Source Bundle
java-1.8.0-openjdk-src-debug.x86_64 : OpenJDK Source Bundle for packages with
ldapjdk.x86_64 : The Mozilla LDAP Java SDK
#选择版本进行安装
[root@vagrant-centos65 vagrant]# yum install java-1.8.0-openjdk第二种,下载jdk源码进行安装,详见:https://blog.csdn.net/u010837612/article/details/50951215
使用java -version 命令查看jdk是否安装成功
ElasticSearch
下载与安装
下载tar包:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz解压安装,由于elasticsearch为了安全不允许我们使用root运行elasticsearch,因此我们要创建一个用户给elasticsearch使用
tar -zxvf elasticsearch-6.2.4.tar.gz
adduser elasticsearch
chown elasticsearch:elasticsearch -R elasticsearch-6.2.4
su elasticsearch
cd elasticsearch-6.2.4
#启动
bin/elasticsearch启动后我们可以访问localhost:9200,如果有打印出信息说明elasticsearch启动成功
[root@vagrant-centos65 vagrant]# curl localhost:9200
{
"name" : "1N6qOms",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "hLz73Ye3QBysYvoL38cM0A",
"version" : {
"number" : "6.2.4",
"build_hash" : "ccec39f",
"build_date" : "2018-04-12T20:37:28.497551Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}如果你用的是虚拟机或者云服务器启动elasticsearch,但是却无法通过ip访问,如ip:9200,那么你可以修改config/elasticsearch.yml
network.host = 0.0.0.0可能遇到的问题
启动过程中你可能遇到以下问题:
问题: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
解决:
编辑 /etc/security/limits.conf
在文件最后添加
* soft nofile 65536
* hard nofile 65536保存
此文件修改后需要重新登录用户,才会生效
问题:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决:
修改/etc/sysctl.conf配置文件,
cat /etc/sysctl.conf | grep vm.max_map_count
vm.max_map_count=262144如果不存在则添加
echo "vm.max_map_count=262144" >>/etc/sysctl.conf问题:max number of threads [1024] for user [elasticsearch] is too low, increase to at least [2048]
解决:
修改/etc/security/limits.d/90-nproc.conf
* soft nproc 4096问题:system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
解决:
修改安装目录下config/elasticsearch.yml
bootstrap.system_call_filter: false如果没有找到这个配置项,就手动添加
有解决不了的问题,也可参考下方链接:
- https://blog.csdn.net/qq942477618/article/details/53414983
- https://blog.csdn.net/odeng888/article/details/76380832
配置
elasticsearch的config目录下主要有三个配置文件:
- elasticsearch.yml:elasticsearch的配置文件
- jvm.options :java虚拟机参数配置
- log4j2.properties:日志配置
java和日志配置这里不细说了,主要关注elasticsearch.yml,它主要有以下配置项:
| 配置 | 说明 |
|---|---|
| cluster.name | 集群名称,同一个集群中的elasticsearch这个名称要配置成一样 |
| node.name | 节点名称 |
| network.host | ip地址,elasticsearch用该地址来判断当前与运行模式是开发模式还是生产模式,localhost,127.0.0.1之类的地址为开发模式,其他则为生产模式 |
| http.port | 端口 |
| path.data | 数据存储路径,不同的实例这个地址不能相同 |
| path.log | 日志存储路径 |
| discovery.zen.ping.unicast.hosts | 集群主机初始列表 |
集群
单机日志系统可以直接跳过这个部分不看
本地集群
我们可以尝试在本地再启动一个elasticsearch实例,是两个实例成为一个集群
有两种方式,一是复制一份刚刚安装的elasticsearch,修改配置文件中http.port和path.data,然后启动即可。
二是在启动的时候增加参数指定port和path.data,如:
bin/elasticsearch -Ehttp.port=8200 -Epath.data=node2启动后我们可以访问localhost:8200也能得到和实例1相同的结果。
访问localhost:8200/_cat/nodes 查看当前集群的节点:
[root@vagrant-centos65 data]# curl localhost:8200/_cat/nodes
127.0.0.1 11 96 0 0.00 0.00 0.00 mdi * 1N6qOms
127.0.0.1 30 96 0 0.00 0.00 0.00 mdi - iBdu9zU多机集群
如果要多台机器集群,步骤也很简单,只要每台机器分别安装elasticsearch,然后配置master初始列表
node.name: node-n
discovery.zen.ping.unicast.hosts: ["host1:port", "host2:port"]然后启动实例即可。
Kibana
下载与安装
kibana的下载与安装和elasticSearch基本一致
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
tar -zxvf kibana-6.2.4不一样的是,在启动之前,我们要修改配置文件config/kibana.yml,配置elasticsearch的地址:
elasticsearch.url: "http://ip:9200"然后启动:
bin/kibana启动后访问http://localhost:5601 就能进入kibana
配置
kibana配置文件在config、kibana.yml,主要关注以下配置项:
| 配置 | 说明 |
|---|---|
| server.host | 配置服务ip,想让外部访问时就必须配置 |
| server.port | 端口 |
| elasticsearch.url | elasticsearch的访问地址 |
logstash
安装
安装和kibana差不多
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz
tar zxvf logstash-6.2.4.tar.gz进入config目录,创建一个logstash.conf 文件:
input{
file{
type => "log"
path => "/root/logs/*.log"
start_position => "beginning"
}
}
output{
elasticsearch{
hosts => "127.0.0.1"
index => "log-%{+YYYY.MM.dd}"
}
}input配置输入源,我们配置成log文件,output配置输出,我们输出到之前安装的elasticsearch中,索引为log-日期
启动:
bin/logstash -f config/logstash.conf然后打开kibana,点击management

创建索引
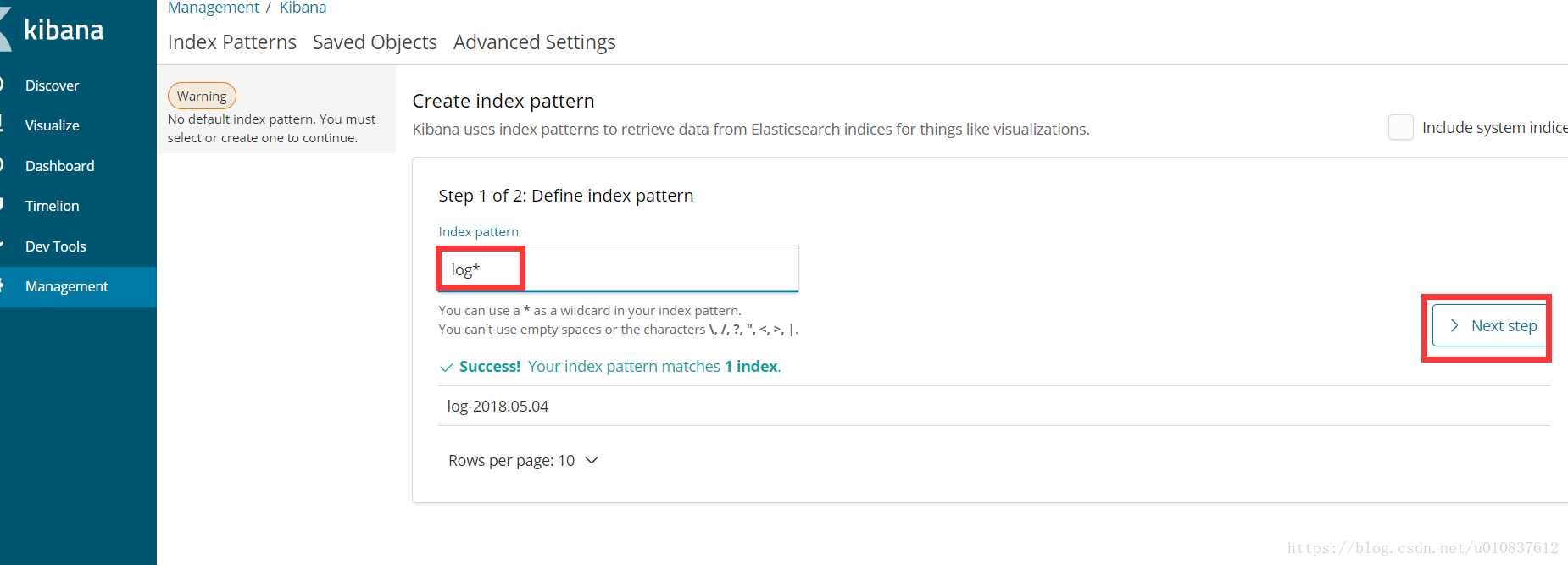
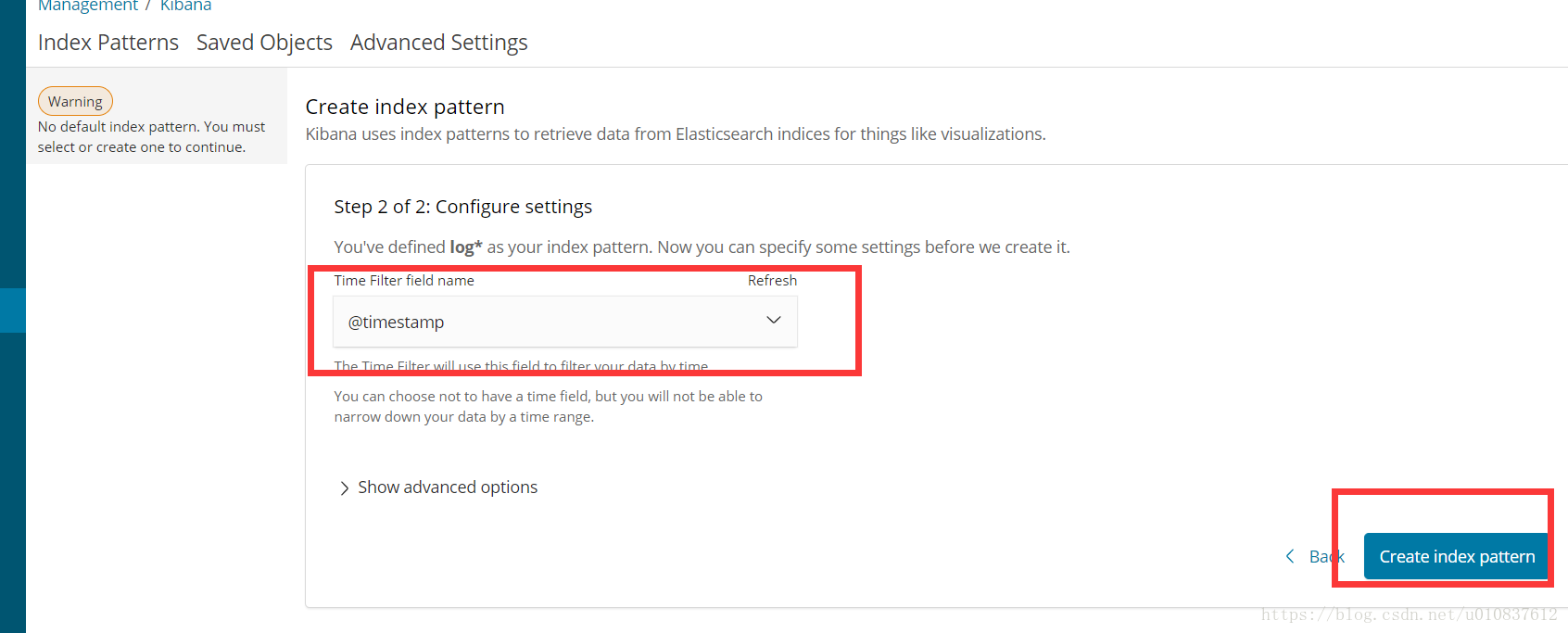
创建成功后,我们来到刚刚配置文件配置的日志路径,创建一个log文件,随意输入一些内容
echo 123 >> /root/logs/test.log然后就可以在kibana中看到我们的日志
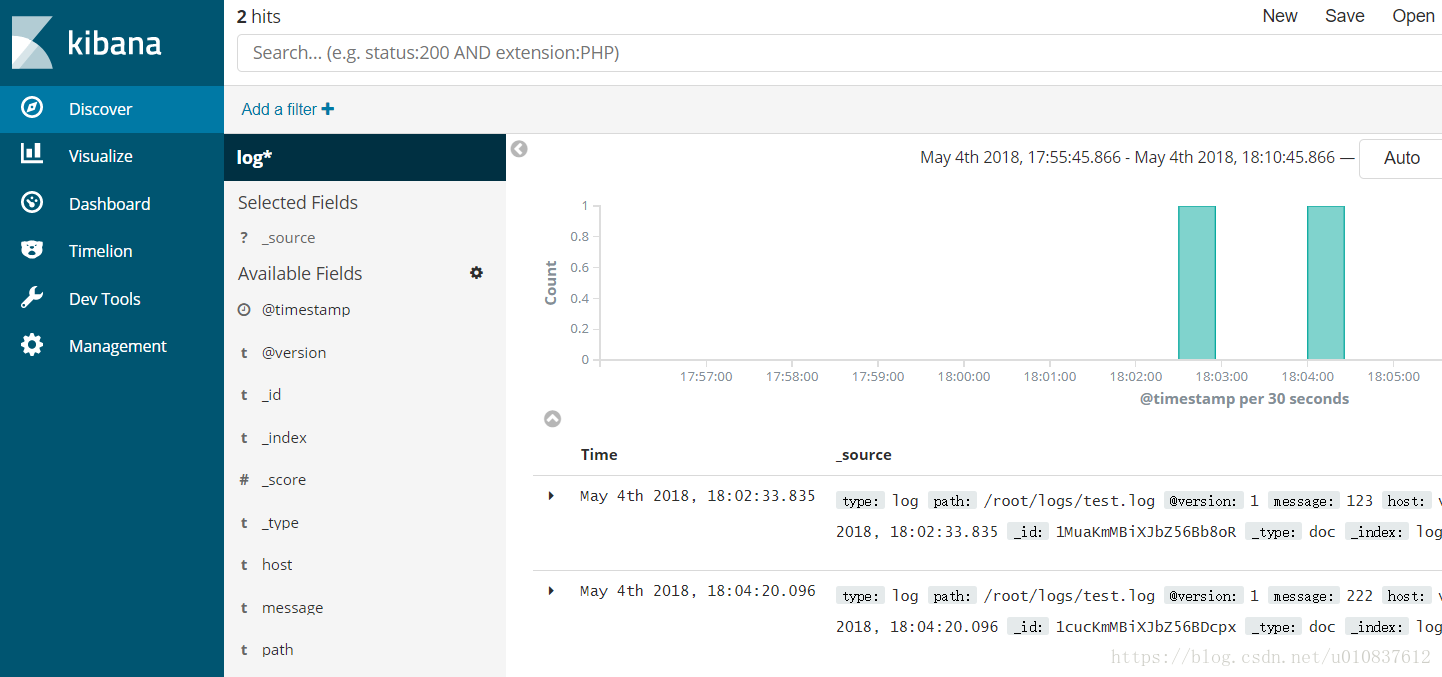
日志格式解析
上面我们只是简单的将日志的内容读取出来,logstash给我们提供了grok,能够格式化解析日志内容,例如有一条日志如下:
[2018-05-05 10:00:00][192.168.3.3][i am log]我们修改配置文件logstash.conf,增加filter
input{
file{
type => "log"
path => "/root/logs/*.log"
start_position => "beginning"
}
}
filter {
#定义数据的格式
grok {
match => { "message" => "\[%{DATA:timestamp}\]\[%{IP:serverIp}\]\[%{DATA:content}\]"}
}
}
output{
elasticsearch{
hosts => "127.0.0.1"
index => "log-%{+YYYY.MM.dd}"
}
}然后重启logstash,查看kibana:
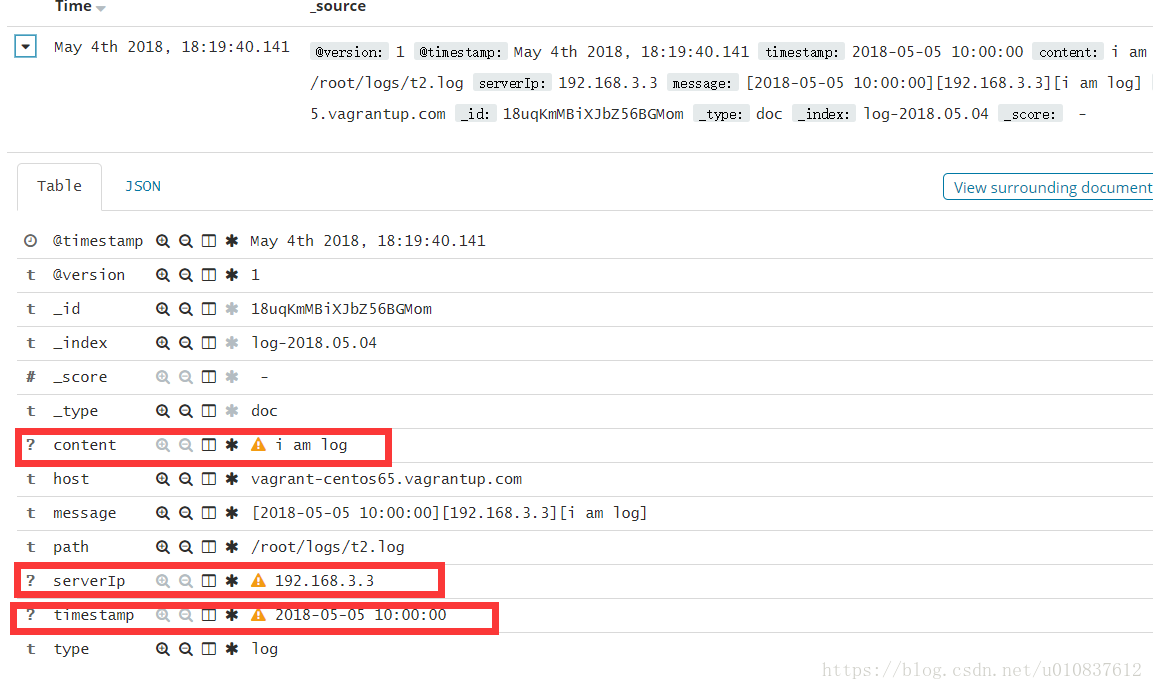
grok具体使用可以查看官方文档:https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
elasticsearch CRUD操作
这部分内容可以不看,与日志系统没有太大关系。
elasticsearch的crud操作可以在kibana的Dev Tools界面,点击get to work操作,如下所示:

然后我们就可以在控制台进行增删改查操作。
首先我们必须了解一下elasticsearch的一些常用术语:
| 术语 | 说明 |
|---|---|
| document | 文档,也可以简单理解为一条数据 |
| index | 索引 |
| type | 索引中的数据类型 |
| feild | 字段名 |
| Query DSL | 查询语句 |
下面给出一些CRUD的示例:
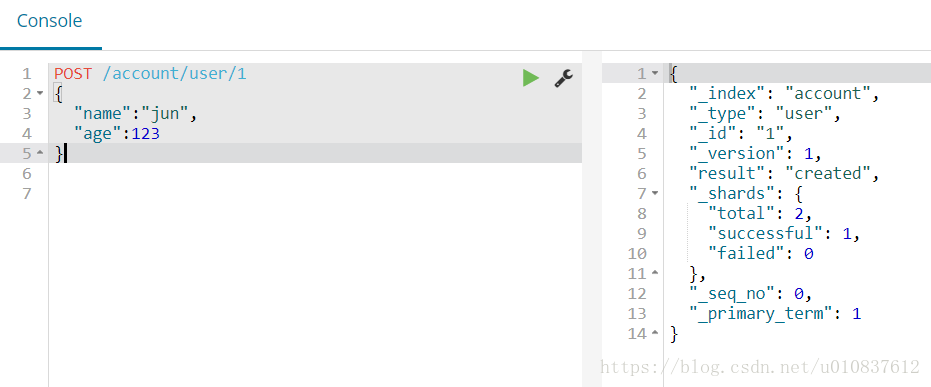
插入文档
插入id为1的文档数据:(点击绿色箭头执行语句)
查询
获取刚刚插入的文档:

更新
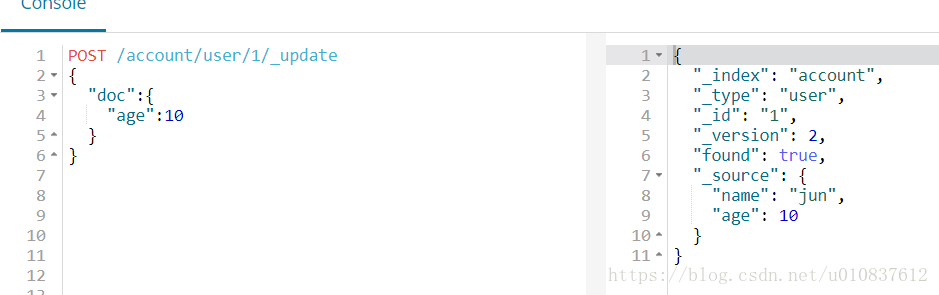
注意:要更新的内容要放在”doc”中
删除文档

查询语句
查询有两种方式:
方式一:
GET /account/user/_search?q=jun这种方式只能进行一些简单的匹配
方式二:
查询name = jun的文档
GET /account/user/_search
{
"query":{
"term": {
"name": {
"value": "jun"
}
}
}
}更多语法请查看官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html