前文已经简单搭建好了elk,现在就入数据这一方面,我们简单分析。
1现状:我司java程序全部使用log4j2经行日志写文件。其基本例子如下:
<?xml version="1.0" encoding="UTF-8"?>
<!-- status:log4j自身日志,monitorInterval:自动检测配置文件是否改变,单位:s -->
<configuration status="info" monitorInterval="5" shutdownHook="disable">
<Properties>
<!-- 配置日志文件输出目录 -->
<Property name="LOG_HOME">/logdata-local/path/to/log/</Property>
</Properties>
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout charset="UTF-8" pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} - %msg%n"/>
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch) -->
<ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/>
</Console>
<!-- 服务端主日志 -->
<RollingFile name="asyncservice" fileName="${LOG_HOME}/service.log"
filePattern="${LOG_HOME}/service_%d{yyyy-MM-dd}_%i.log">
<Filters>
<!-- 打印除error日志所有日志 -->
<ThresholdFilter level="error" onMatch="DENY" onMismatch="NEUTRAL"/>
<ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
<PatternLayout charset="UTF-8"
pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} [%L] - %msg%n"/>
<Policies>
<!-- 更新时间 -->
<TimeBasedTriggeringPolicy modulate="true" interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<!-- 最多8个日志 -->
<DefaultRolloverStrategy max="10"/>
</RollingFile>
<!-- 服务端错误日志 -->
<RollingFile name="asyncerror" fileName="${LOG_HOME}/error.log"
filePattern="${LOG_HOME}/error_%d{yyyy-MM-dd}_%i.log">
<Filters>
<!-- 打印error日志 -->
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<ThresholdFilter level="error" onMatch="DENY" onMismatch="ACCEPT"/>
</Filters>
<PatternLayout charset="UTF-8"
pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} [%L] - %msg%n"/>
<Policies>
<!-- 更新时间 -->
<TimeBasedTriggeringPolicy modulate="true"
interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<!-- 最多8个日志 -->
<DefaultRolloverStrategy max="8"/>
</RollingFile>
<RollingFile name="asyncmonitor" fileName="${LOG_HOME}/monitor.log"
filePattern="${LOG_HOME}/report_%d{yyyy-MM-dd}_%i.log">
<PatternLayout charset="UTF-8" pattern="%d{HH:mm:ss.SSS} - %msg%n"/>
<Policies>
<!-- 更新时间 -->
<TimeBasedTriggeringPolicy modulate="true" interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<!-- 最多8个日志 -->
<DefaultRolloverStrategy max="8"/>
</RollingFile>
<Async name="service" bufferSize="102400">
<AppenderRef ref="asyncservice"/>
</Async>
<Async name="error" bufferSize="102400">
<AppenderRef ref="asyncerror"/>
</Async>
<Async name="monitor" bufferSize="102400">
<AppenderRef ref="asyncmonitor"/>
</Async>
</appenders>
<loggers>
<Logger name="monitor" level="info" additivity="false">
<AppenderRef ref="monitor"/>
</Logger>
<root level="info">
<AppenderRef ref="Console"/>
<AppenderRef ref="service"/>
<AppenderRef ref="error"/>
</root>
</loggers>
</configuration>
其中主要使用了log4j2的异步缓冲池,5秒刷新配置,自动分日期打包文件等特性。
2目标
我们主要关注
pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} [%L] - %msg%n"
打出来的日志基本是这样:
2018-03-27 21:22:19.048 [pool-4-thread-1] INFO com.common.monitor.MonitorService [] - 监控redis连接#执行结果:OK,监控状态:redis状态:true(0,0)我决定使用logstash的grok插件,过滤信息
3成果
input{
file {
path => ["/logdata-local/*/*.log"]
exclude => "*_*.log"
max_open_files => "18600"
codec => multiline {
pattern => "^\s"
what => "previous"
}
}
}
filter{
grok {
match =>{
"message" =>"%{TIMESTAMP_ISO8601:logtime}\s\[%{DATA:logthread}\]\s%{LOGLEVEL:loglevel}\s\s%{DATA:logclass}\s\[\].{4}%{GREEDYDATA:logcontent}"
}
remove_field => ["message"]
}
date {
match => ["logtime", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
}
mutate {
add_field => { "filepath" => "%{path}" }
}
mutate{
split => ["filepath","/"]
add_field => {
"idx" => "%{[filepath][1]}-%{[filepath][2]}-%{[filepath][3]}"
}
add_field => {
"filename" => "%{[filepath][3]}"
}
}
mutate{
lowercase => [ "idx" ]
}
}
output {
elasticsearch {
hosts => ["192.168.193.47:9200","192.168.193.47:9200","192.168.193.47:9200"]
index => "logstash-bank-%{idx}-%{+YYYY.MM.dd}"
user => elastic
password => elastic
}
}过滤器意思将其自动生成的message信息解析,然后移除。将文件路径的“/”转化为“-”建立索引。索引不能有大写,最后都小写化。
解析出的日志时间,覆盖原始的@timestamp字段。
其基本将每条日志的时间、线程、日志级别、类和内容字段分析了出来,以后看运维同事有什么查询需求,将规范化内容再细化解析。
4kibana呈现
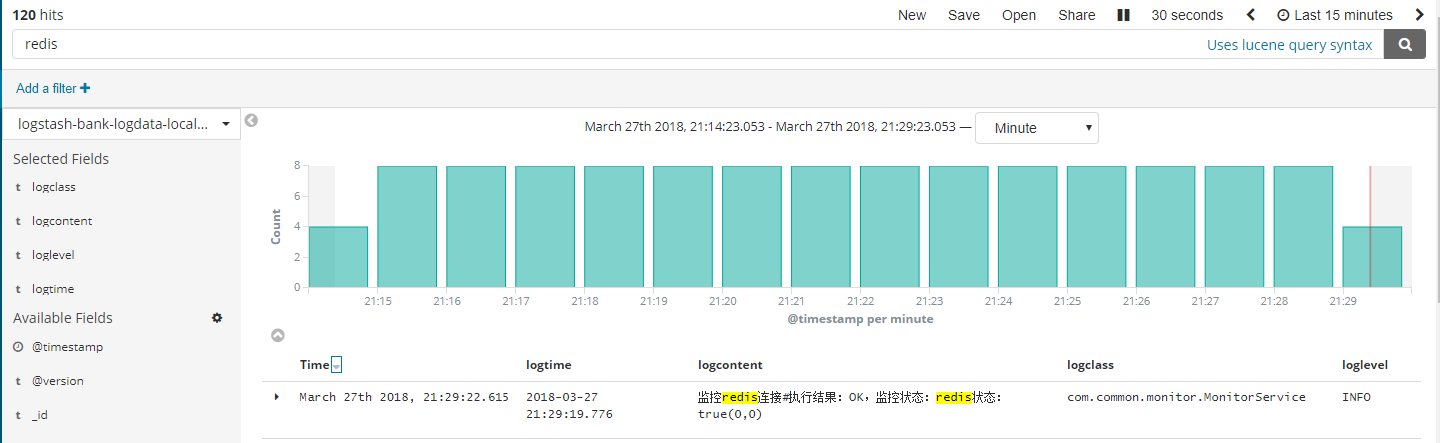
这样日志就像数据库一样,可以按照字段查询了。