论文:https://arxiv.org/abs/2112.02889
Github:GitHub - philip-mueller/lovt: Localized representation learning from Vision and Text (LoVT)
摘要
摘要对比学习已被证明对未标记数据的预训练图像模型是有效的,在医学图像分类等任务中也有很好的结果。在预训练期间使用配对文本(如放射报告)进一步提高了结果。然而,大多数现有方法针对的是图像分类下游任务,对于语义分割或目标检测等局部任务可能不是最优的。因此,我们提出了基于视觉和文本的局部表示学习(LoVT),据我们所知,这是第一个针对局部医学成像任务的文本监督预训练方法。该方法将实例级图像-报告对比学习与图像区域和报告句子表征的局部对比学习相结合。我们对来自5个公共数据集的18个胸片局部任务的评估框架进行了LoVT和常用的预训练方法的评估。LoVT在18个研究任务中的10个中表现最好,使其成为本地化任务的首选方法。
背景
1)医学图像高质量标注数据少
2)CheXpert[37]等基于规则的自然语言处理(NLP)模型从这些报告中提取标签,允许自动创建大型数据集,但它们也有一些明显的局限性,一般只能用于分类。它们为报告生成整体标签(因此成对的图像),但将这些标签与特定图像区域相关联是非常重要的,因此它们不能用于语义分割或对象检测等局部任务。同时,基于规则的NLP模型必须手工创建,不能泛化到不同的分类任务甚至不同的报告写作风格[37]。这些报告除了生成分类标签,也可以直接用于预训练方法,如ConVIRT方法首次提出的[96]。在这里,报告中包含的语义信息被用作弱监督来预训练图像模型,然后对标记的下游任务进行微调,从而可以改善结果或减少标记样本的数量。但是不适用于本地下游任务。
贡献
1)我们提出了一个局部对比损失,允许对齐句子或图像区域的局部表示,同时鼓励空间平滑和灵敏度
2)我们将每个报告分成句子,将每个图像分成区域(即补丁),计算句子和区域的表示,并使用注意机制和我们提出的局部对比损失对它们进行对齐。
3)我们在区域和句子表示上使用注意力池来计算全局(即每个图像和每个报告)表示,然后使用全局对比损失来对齐它们。
4)我们提出了基于视觉和文本的本地化表示学习模型(LoVT),这是一种预训练方法,使用我们提出的想法扩展了ConVIRT[96],并在大多数本地化下游任务上优于它。
5)我们在下游评估框架[58]上评估了使用MIMIC-CXR[42,41,40,26]训练的方法,该框架包含18个胸片局部任务,包括5个公共数据集上的目标检测和语义分割。
我们将其与几种自监督方法和文本监督方法进行了比较,并在1400多个评估运行中与分类转移进行了比较。我们的方法LoVT被证明是最成功的方法,优于所有其他方法18个任务中的10个。
相关工作
contrastive learning 对比学习
大多数对比学习方法只使用实例级对比,即通过单个向量表示图像的每个视图。虽然结果表示非常适合全局下游任务,但它们不是为局部下游任务设计的。
因此,最近出现了许多使用区域水平对比的方法。也就是说,它们作用于图像区域的表示。与我们的方法不同,这些方法不使用配对文本。
self-supervised representation learning 自监督表示学习方法
利用伴随文本为下游任务预训练图像模型:
直接列文献了↓
[67]Learning transferable visual models from natural language supervision
[39] Scaling up visual and vision-language representation learning with noisy text supervision
[96] Contrastive learning of medical visual representations from paired images and text.
[12] Learning visual representations from textual annotations
[73] Learning visual representations with caption annotations
[51] Learning data-efficient visual representations from localized textual supervision
图像字幕任务(生成任务):
VirTex[12] and ICMLM
多视角对比学习:
ConVIRT[96], CLIP[67] and ALIGN,更适合判别性下游任务,关于图像和文本视图损失函数是NT-Xent。这些方法之间的主要区别在于它们所研究的数据集,ConVIRT是在胸部x射线上训练的,而其他方法使用自然图像。此外,CLIP使用注意力池attention pooling从特征映射中计算图像表示,而其他方法使用图像编码器的默认池化方法
我们的方法遵循类似的框架,但增加了局部对比损失,以便在局部任务上获得更好的性能。此外,它对整个报告进行编码,而不是对单个句子进行采样,并在图像和文本编码器中使用注意力集中
local Mutual Information approach 局部互信息法
对报告句子和图像区域进行对比学习,但目标是分类而不是局部任务,因此既不鼓励区域之间的对比,也不鼓励空间平滑。
方法

我们随机抽取与给定报告相关的图像之一,并将其分成7 × 7等大小的区域。更准确地说,我们将图像扩大并调整为224×224大小,将其输入卷积神经网络,并使用大小为7×7的输出特征图作为区域表示。
语言模型将报告的标记编码为上下文化的向量表示(考虑到它们在整个报告中的意义),我们从中计算句子表示。
然后使用多对多对齐模型从单模态表示计算跨模态表示,即从句子表示计算图像区域表示,反之亦然。
我们认为,通过对齐跨模态和单模态表示,可以鼓励图像区域表示包含报告中存在的高级语义。
模型总览
是个双塔模型欸
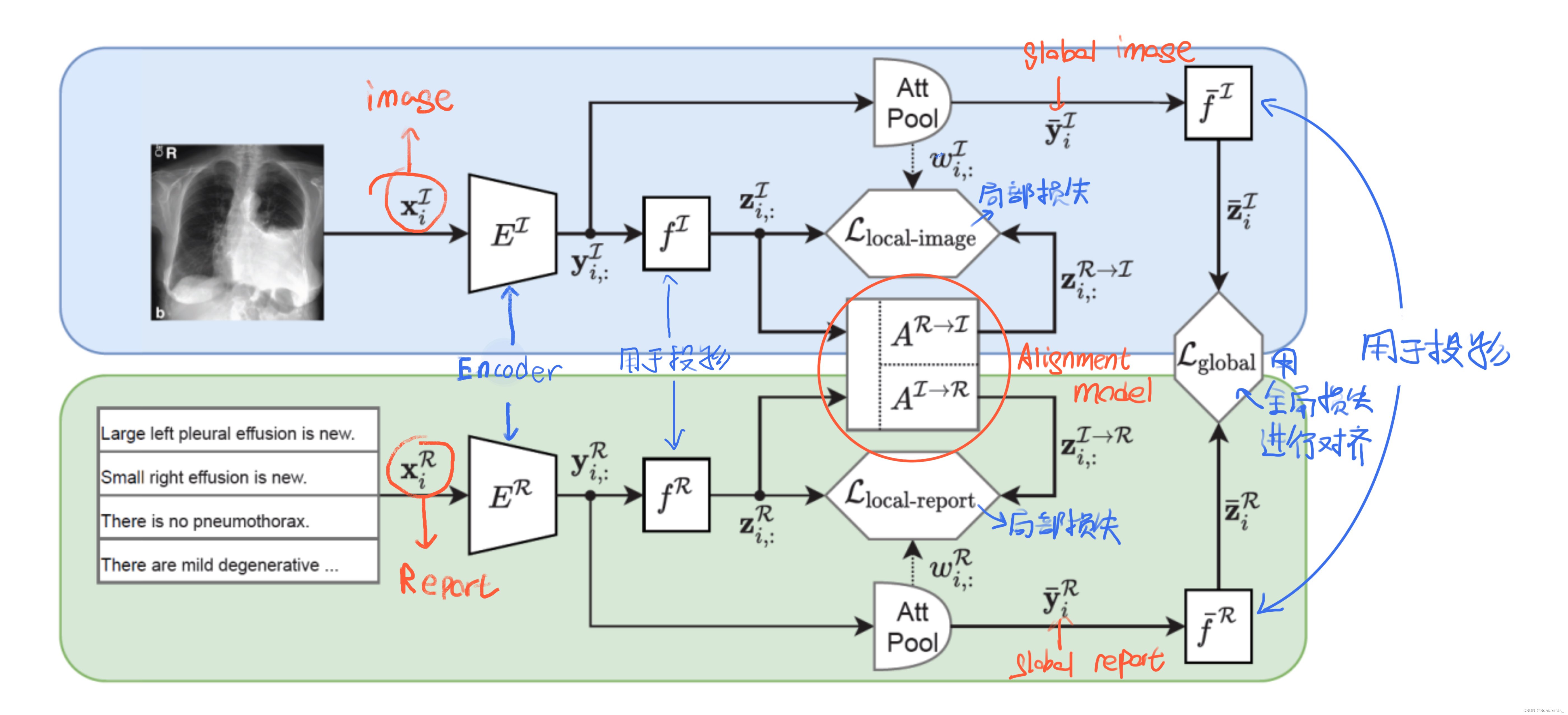
每个训练样本xi是一对图像xIi∈R224×224和由Mi个句子组成的相关报告xRi。xIi和xRi分别编码为图像和报告的两个全局表示,以及每个样本的多个局部表示,分别对应于图像区域和报告句子。然后,基于注意力的对齐模型计算跨模态表示(即来自图像区域的句子表示,反之亦然),这些表示使用局部对比损失与局部单模态表示对齐。此外,全局表示使用全局对比损失进行对齐。编码器和对齐模型在成批的图像报告对xi上进行联合训练。模型和损失函数的细节将在下面的章节中描述。
Encoding 编码器
图像
每张图像xIi使用图像编码器EI编码为K = H × W(我们使用K = 7 × 7)区域表示yI i, K∈RdI,其中K为图像区域的索引,dI为图像区域表示空间的维数。
ResNet50将全局平均池化之前的特征映射作为区域表示
文本
使用报表编码器ER将每个报表xRi编码为Mi句表示yR i,m∈RdR。其中Mi为报告样本i的句子数,m为句子的索引,dR为报告句子表示空间的维数。请注意,虽然K是常数,但每个样本的Mi可能不同。任何将句子编码为向量表示的模型都可以用于ER。
BERT base 对每个报告的连接句子的标记进行联合编码,然后对每个句子的标记表示执行Max池,以获得句子表示
attention pooling layer
multi-head querykey-value attention
投影
我们计算投影局部表示zI i,k∈RdZ和zri,m∈RdZ,投影全局表示¯zI∈R¯dZ和¯zri∈R¯dZ,从表示yI i,k, yR i,m,¯yI i和¯yR i,分别使用(非共享)非线性变换fI, fR,¯fI和¯fR,dZ是共享本地和共享全局表示空间的¯dZ的维度(我们对两者都使用512)。注意,对于局部表示,投影独立地应用于每个区域k或句子m。
Alignment Model 对齐模型
我们计算了图像区域和句子的对齐,并使用基于单头查询键值注意力(single-head query-key-value attention)的对齐模型AI→R和AR→I计算了跨模态表示[82]。
对于每个句子m,交叉模态表示zI→ri,m通过让zri,m参与所有图像区域表示zI, i,k(相关图像)来计算。因此,我们计算概率αI→R i,m,k,句子m与区域k对齐基于它们的投影表示的缩放点积分数, 线性查询键投影中Q是一个学习矩阵。
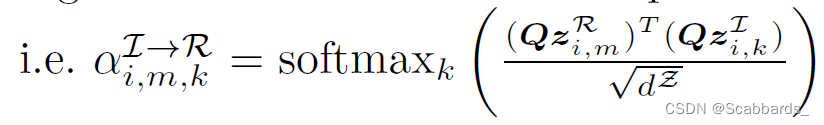
然后对齐模型AI→R使用αI→R i,m,k计算zI→R i,m作为图像区域表示zI, i,k的投影加权和,其中值投影V和输出投影O是学习矩阵。
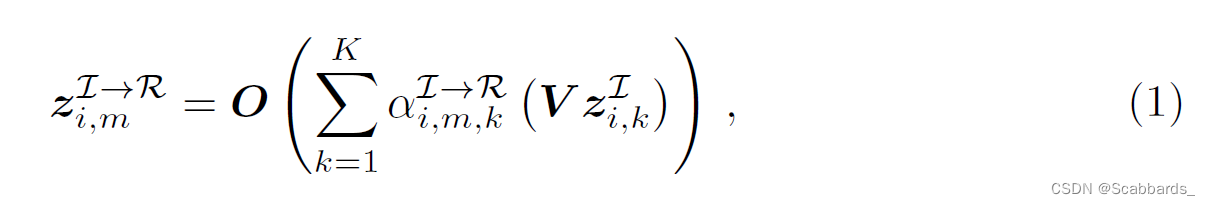
以类似的方式,对齐模型AI→R,交叉模态表示zR→I I,k由 基于zR→I i,k
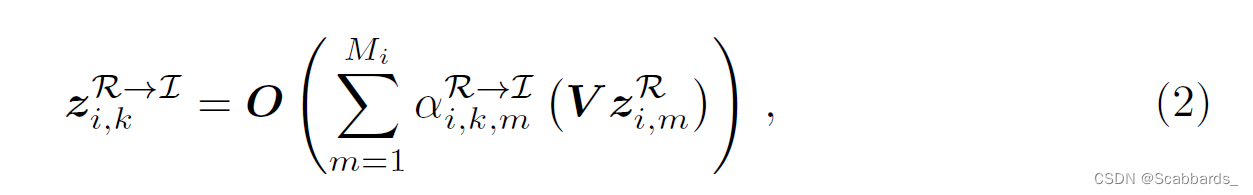
其中,

注意,由于AR→I和AI→R共享相同的矩阵Q, V和O, αR→I I,k,m和αI→R I,m,k之间的唯一区别是转置和softmax应用的索引。
Loss Function损失函数
Global Aligenment
对于全局对齐,我们遵循ConVIRT[96],最大化成对图像和报告表示之间的余弦相似性,同时最小化非成对(即来自不同样本)表示之间的相似性。
损失由图像报告部分组成,其中所有未配对的报告表示都用作负例
其中τ是相似温度(similarity temperature)(我们使用0.1),所有对数都是自然的。

报告-图像部分,定义类似:
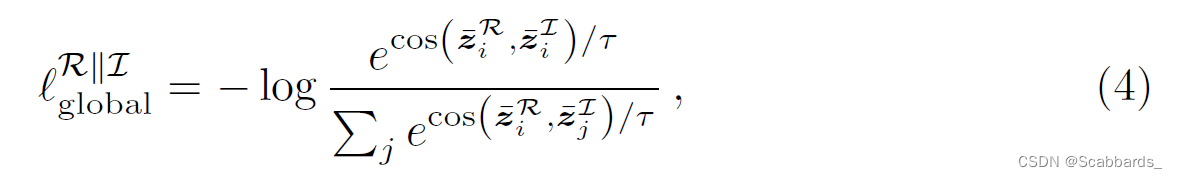
使用超参数λ∈[0,1](我们使用0.75)将这两部分组合起来:
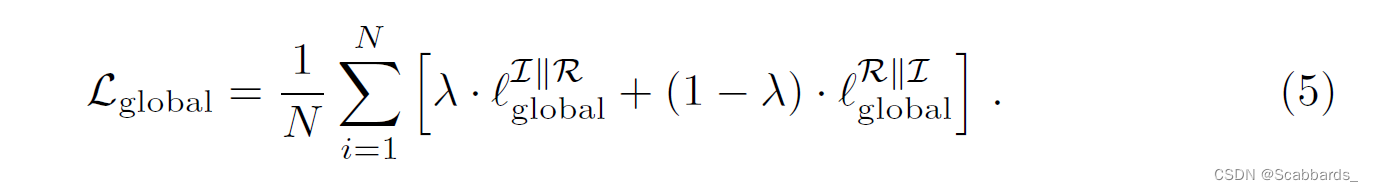
Local Alignment
暂时先放个截图,我有点理不清了(摊),理顺了再补解释
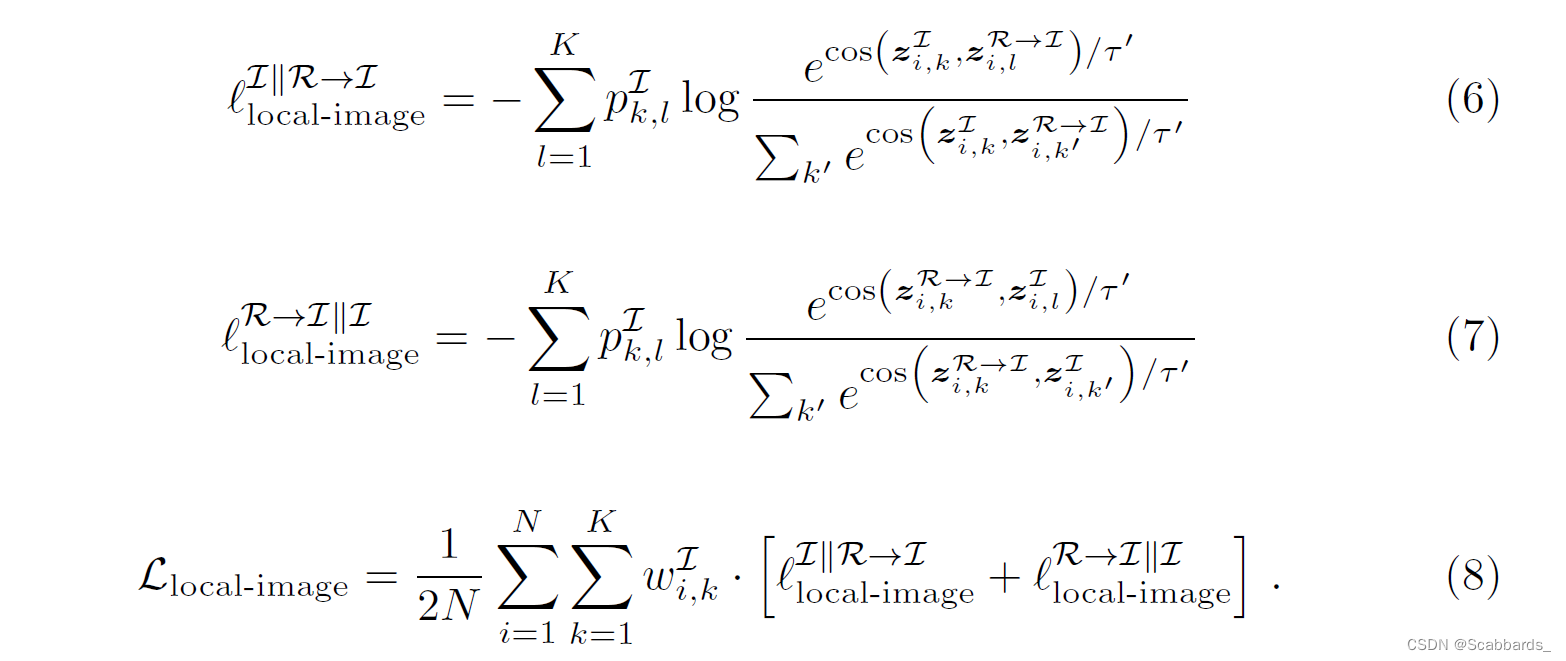
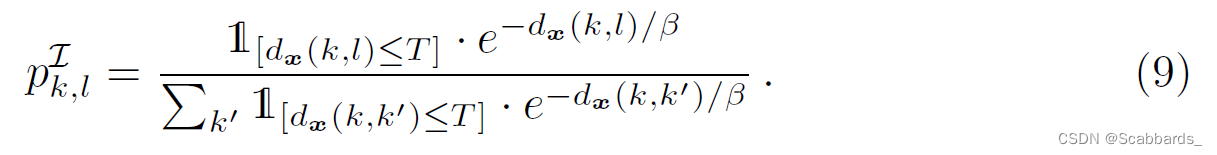
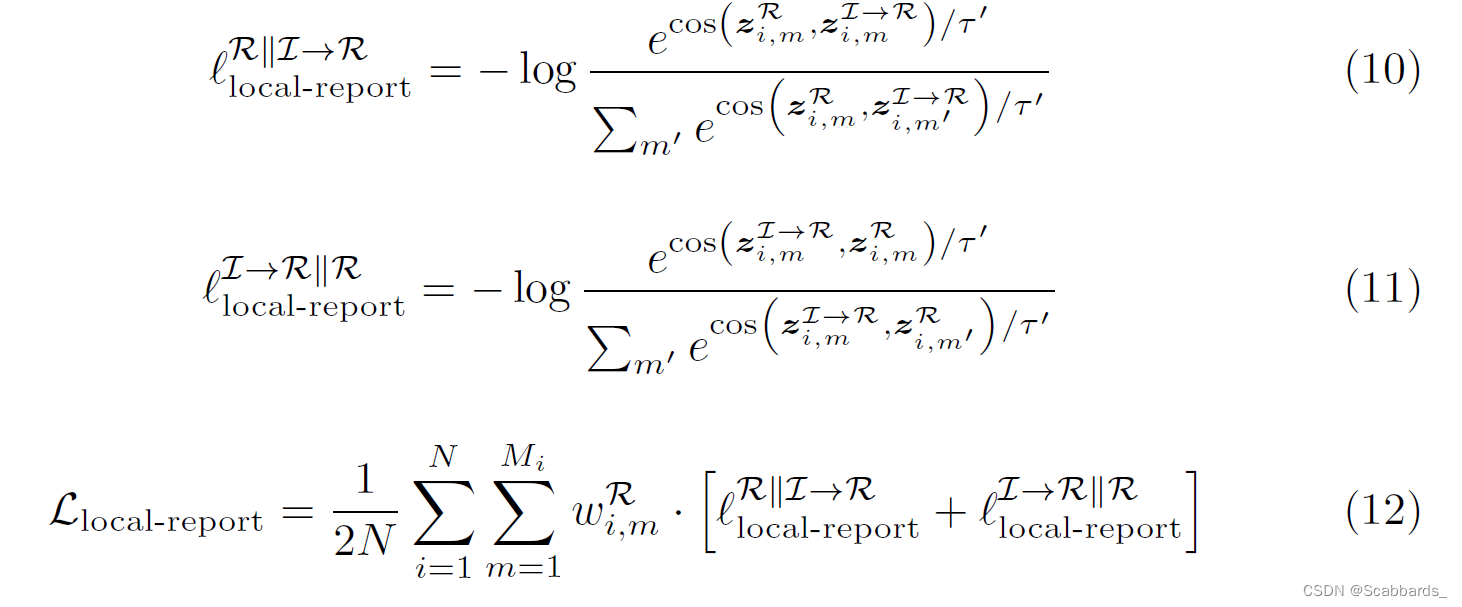
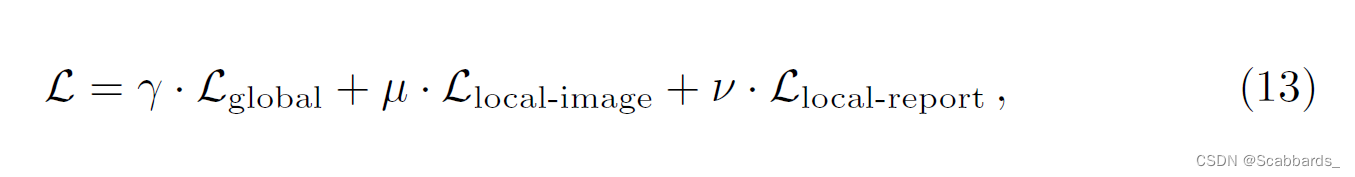
实验
我们在下游评估框架[58]中对胸部x光片进行了18个局部任务的评估,我们将在这里简要介绍。
Evaluation Protocols 评价方案
我们只使用预训练的ResNet50(来自图像编码器)。
语义分割
(i) U-Net Finetune:在这里,ResNet50被用作U-Net的主干[70],并与所有其他层共同微调;
(ii) U-Net Frozen:在这里,ResNet50被用作U-Net的冻结主干[70],只有非主干层被微调;
(iii) Linear:在这里,一个元素线性层被训练,该层在冻结ResNet50的最后一个特征映射(池化之前)之后应用,在结果被上采样到分割分辨率之前。
目标检测
(i) YOLOv3 Finetune: 此处使用ResNet50作为YOLOv3[69]模型的主干,并与非主干层共同进行微调
(ii) YOLOv3 Frozen:此处使用ResNet50作为YOLOv3[69]模型的冻结主干,仅对非主干层进行微调
(iii) Linear:此处将目标检测地面真值转换为分割蒙版,然后使用Linear分割协议进行评估。
Downstream Datasets 下游数据集
(i) RSNA Pneumonia Detection[86,74],超过26万张胸部正面x线片,检测目标为肺炎混浊。我们使用YOLOv3 Finetune, YOLOv3 Frozen和Linear,每个协议具有1%,10%和100%的训练样本;
(ii) COVID Rural[81,13],对COVID-19肺部不透明区域使用分割口罩的200多张胸部正面x线片。我们使用UNet Finetune, UNet Frozen和Linear;
(iii) SIIM-ACR Pneumothorax Segmentation[75],使用超过12000张气胸正面x线片和分割口罩。我们使用UNet Finetune, UNet Frozen协议,但由于没有使用Linear,因为分割掩码的细粒度性质;
(iv) Object CXR[38],使用9000个正面胸部x光片,检测目标为异物。我们使用YOLOv3 Finetune, YOLOv3 Frozen和Linear协议;
(v) NIHCXR[86],近1000张胸部正位x线片,检测目标为8种病理(肺不张、心脏肥大、积液、浸润、肿块、结节、肺炎和气胸)。由于每个类的数据有限,我们只使用Linear协议。
U-Net Finetune和YOLOv3 Finetune 评估了预训练图像模型在实际应用中微调的程度
线性协议直接评估学习到的局部表示(即特征映射),同时添加尽可能少的参数,因此大部分都省略了下游求值时随机初始化引入的方差。
U-Net冻结协议和YOLOv3冻结协议可以看作是两个极端之间的中间地带,其中表示是冻结的,但在更实际的设置中进行评估(但有许多随机初始化层)。总的来说,这允许对预训练表征的许多方面进行分析。
Tuning and Evaluation Procedure
我们在单个下游任务上调整所有模型,RSNA YOLOv3冻结10%。在调优期间没有评估其他下游任务,以确保模型不会偏向下游任务。调优后,对每个模型在所有下游任务上进行评估。
对于每个任务,每个模型分别调整了下游学习率(使用单个评估运行),然后运行五个评估(都使用调优学习率)。我们报告了这五次运行的平均结果及其95%置信区间。
Pre-Training Dataset
我们在MIMIC-CXR[40,41,42,26]的版本2上训练我们的方法,因为据我们所知,它是这类数据集中最大和最常用的数据集。由于所有下游任务只包含正面视图,因此我们删除所有侧面视图,这样大约保留21000个训练样本,每个样本都有一个报告和一个或多个正面图像。
对比Baseline网络
Random Init :使用默认的随机初始化方式初始化ResNet50
ImageNet[71] Init:ResNet50使用ImageNet ILSVRC-2012任务上预训练的权值进行初始化[71];
CheXpert[37]: ResNet50使用CheXpert[37]标签的监督多标签二元分类对MIMIC-CXR中患者的正面胸部x射线进行预训练
Global image pre-training methods: ResNet50使用自监督预训练方法SimCLR[9]或BYOL[30]对MIMIC-CXR的正面胸部x射线进行预训练。我们决定包括SimCLR,因为它使用与LoVT相似的损失函数,我们包括BYOL是因为它的广泛使用
Local image pre-training methods: ResNet50使用自监督预训练方法PixelPro[92]对MIMIC-CXR的正面胸部x射线进行预训练。我们使用PixelPro来研究仅使用图像时局部对比度损失的影响。
Global image-text pre-training methods: ResNet50在正面MIMICCXR上使用图像-文本方法ConVIRT[96]或CLIP[67]进行预训练。请注意,为了具有可比性,我们对CLIP进行了调整,使用与ConVIRT相同的图像和文本编码器,这样CLIP之间的主要区别就在于此
实验结果
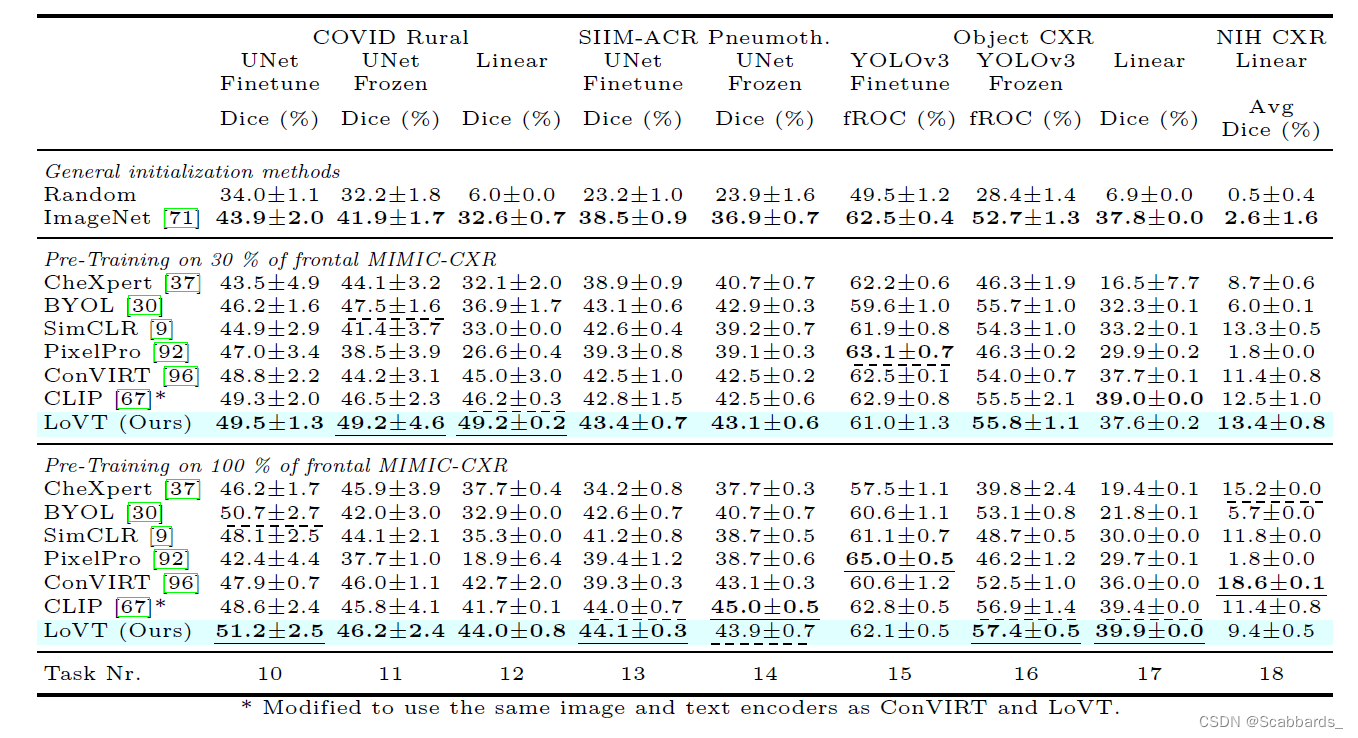
1.所有结果在五次评估运行中取平均值,并显示95%置信区间。每个任务的最佳结果用下划线表示,次优结果用虚线表示,每个预训练类别(一般初始化,30%和100%预训练)的最佳结果用粗体突出显示。请注意,YOLOv3 Frozen 10%任务(任务5)用于调优所有方法,因此可能不具有代表性,因为方法可能在此任务上过拟合。
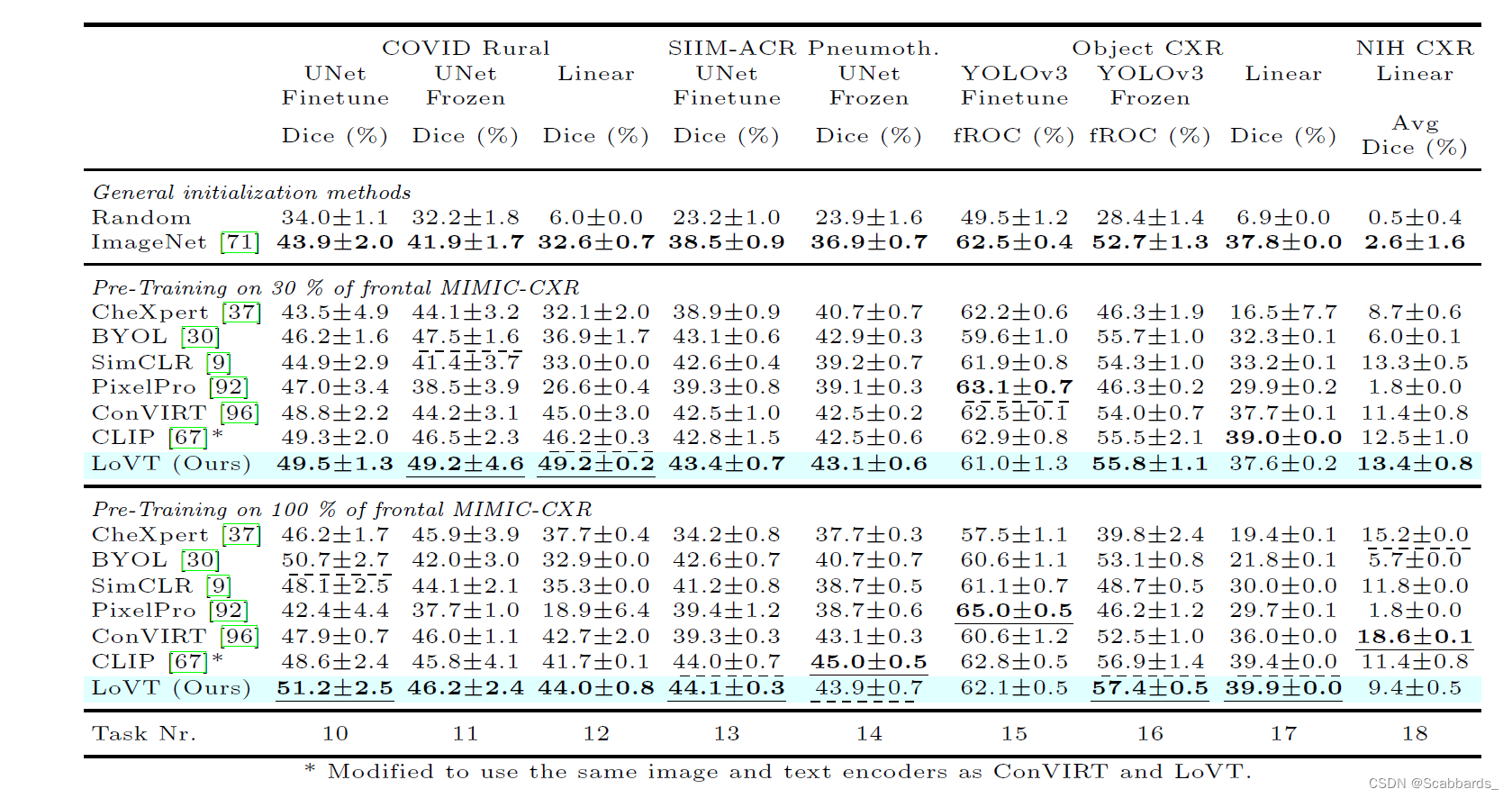
2.所有结果在五次评估运行中取平均值,并显示95%置信区间。每个任务的最佳结果用下划线标出,次优结果用虚线标出,每个预训练类别的最佳结果用虚线标出(一般初始化,30%和100%的预训练)以粗体突出显示。
消融实验
太多了,自己看文章附录吧!