目录
源文件(Chain_Stack.cpp)对函数功能的具体实现:
引言:
数据结构学习目录:
数据结构系列学习(一) - An Introduction to Data Structure
数据结构系列学习(二) - 顺序表(Contiguous_List)
数据结构系列学习(三) - 单链表(Linked_List)
数据结构系列学习(四) - 单向循环链表(Circular Linked List)
数据结构系列学习(五) - 双向链表(Double_Linked_List)
在上篇文章中我们了解学习了顺序栈,并使用代码对它进行了实现。这篇文章我们将对栈的另外一种表达形式——链栈(Chain_Stack)进行了解学习并使用代码对它进行实现。
学习:
链栈,即栈的链式存储结构,链栈是一种数据存储结构,可以通过单链表的方式来实现,使用链式栈的优点在于它能够克服用数组实现的顺序栈空间利用率不高的特点,但是需要为每个栈元素分配额外的指针空间用来存放指针域。
这里我们需要思考,我们应该如何用单链表来实现栈这一种存储方式呢?如图为不带头节点的单链表:
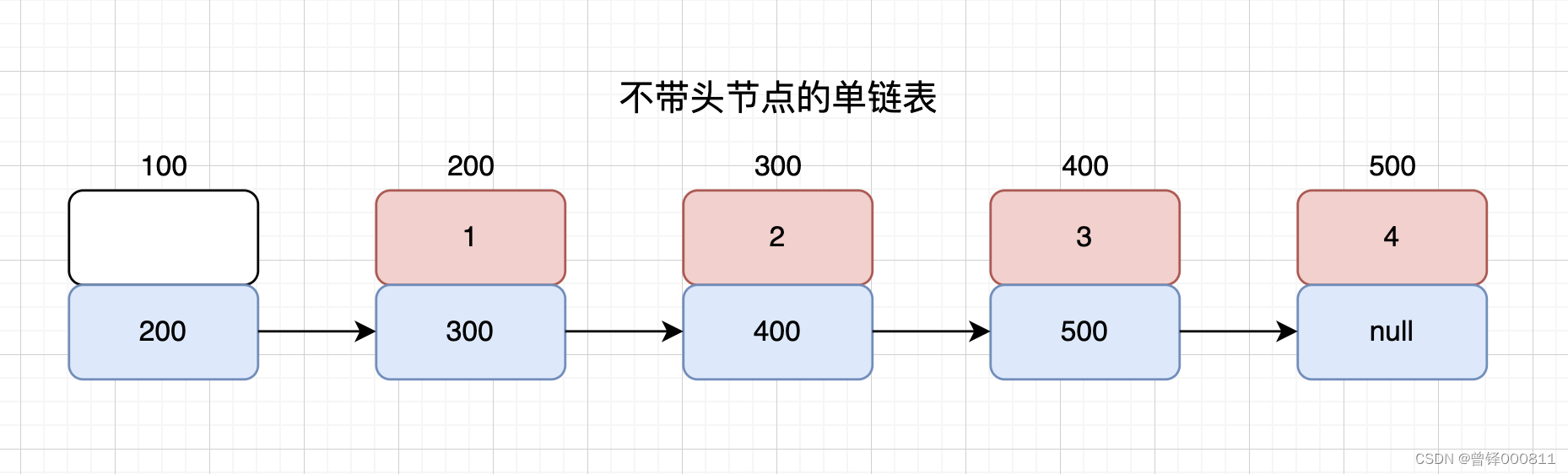
在之前我们讲过,栈(Stack)这种东西,就是限定仅在表尾进行插入或删除操作的线性表。
所以我们依照栈的特性,我们就将这个吞吐的口设定在单链表的头节点和第一个有效节点之间,其实也就是我们之前实现过的单链表中的头插和头删功能。
这玩意儿也没啥难的,说白了,就是阉割版的单链表。
代码实现:
链栈中要实现的功能函数:
初始化函数(Init_Stack);
清空函数(Clear);
销毁函数(Destroy);
打印函数(Show);
查找函数(Search);
入栈函数(Push);
出栈函数(Pop);
返回栈顶元素函数(Top);
判空函数(IsEmpty);
获取有效数据个数函数(Get_Length);
头文件(Chain_Stack.h):
设置链栈中的元素范型:
typedef int Elem_type;链栈的结构体设计:
因为我们是通过单链表的方式来实现栈这种抽象数据类型,所以我们设计链栈的结构体就直接采用链表的结构体设计。
typedef struct CStack
{
Elem_type data;
struct CStack* next;
}Stack,*PStack;所有功能函数的声明:
//初始化
void Init_Stack(PStack cstack);
//清空
void Clear(PStack cstack);
//销毁
void Destroy(PStack cstack);
//打印
void Show(PStack cstack);
//查找
PStack Search(PStack cstack,Elem_type val);
//入栈
bool Push(PStack cstack,Elem_type val);
//出栈
bool Pop(PStack cstack);
//返回栈顶元素
Elem_type top(PStack cstack);
//判空函数
bool IsEmpty(PStack cstack);
//返回有效元素个数
int Get_Length(PStack cstack);源文件(Chain_Stack.cpp)对函数功能的具体实现:
初始化函数(Init_Stack):
直接丢弃掉头节点的数据域,将头节点的next域赋值为空。
void Init_Stack(PStack cstack)
{
assert(cstack != nullptr);
cstack->next = nullptr;
}清空函数(Clear);
在链表中清空和销毁的意义一样,直接在清空函数中调用销毁函数即可。
void Clear(PStack cstack)
{
Destroy(cstack);
}销毁函数(Destroy):
当我们的链栈不为空时,就无限调用头删函数直到链表为空。
void Destroy(PStack cstack)
{
assert(cstack != nullptr);
while (!IsEmpty(cstack)){
Pop(cstack);
}
}打印函数(Show):
定义结构体类型指针p指向头节点之后的第一个有效节点,定义循环,循环条件为p的指向不为空地址,p就可以遍历到末尾节点,将p所指向的节点的data域中的数据一一打印出来即可。
void Show(PStack cstack)
{
assert(cstack != nullptr);
PStack p = cstack->next;
for(;p != nullptr;p = p->next){
printf("%3d", p->data);
}
}查找函数(Search):
查找函数为结构体指针类型,定义结构体类型指针p指向头节点之后的第一个有效节点,定义循环,循环条件为p不指向空地址,当p指针指向的节点的数据域中的值等于我们要查找的值时,返回这个节点的地址,如果没有找到,就返回空地址。
PStack Search(PStack cstack,Elem_type val)
{
assert(cstack != nullptr);
PStack p = cstack->next;
assert(p != nullptr);
for(;p != nullptr;p = p->next){
if(val == p->data){
return p;
}
}
return nullptr;
}入栈函数(Push):
此时的入栈函数相单于单链表中的头插函数,首先通过malloc函数在堆区为新节点申请内存,将我们要插入的值赋值给新节点的数据域中,将原来头节点的next域(也就是原来第一个有效节点的地址)赋值给pnewnode的next域,然后再将pnewnode的地址赋值给头节点的next域即可,如图:
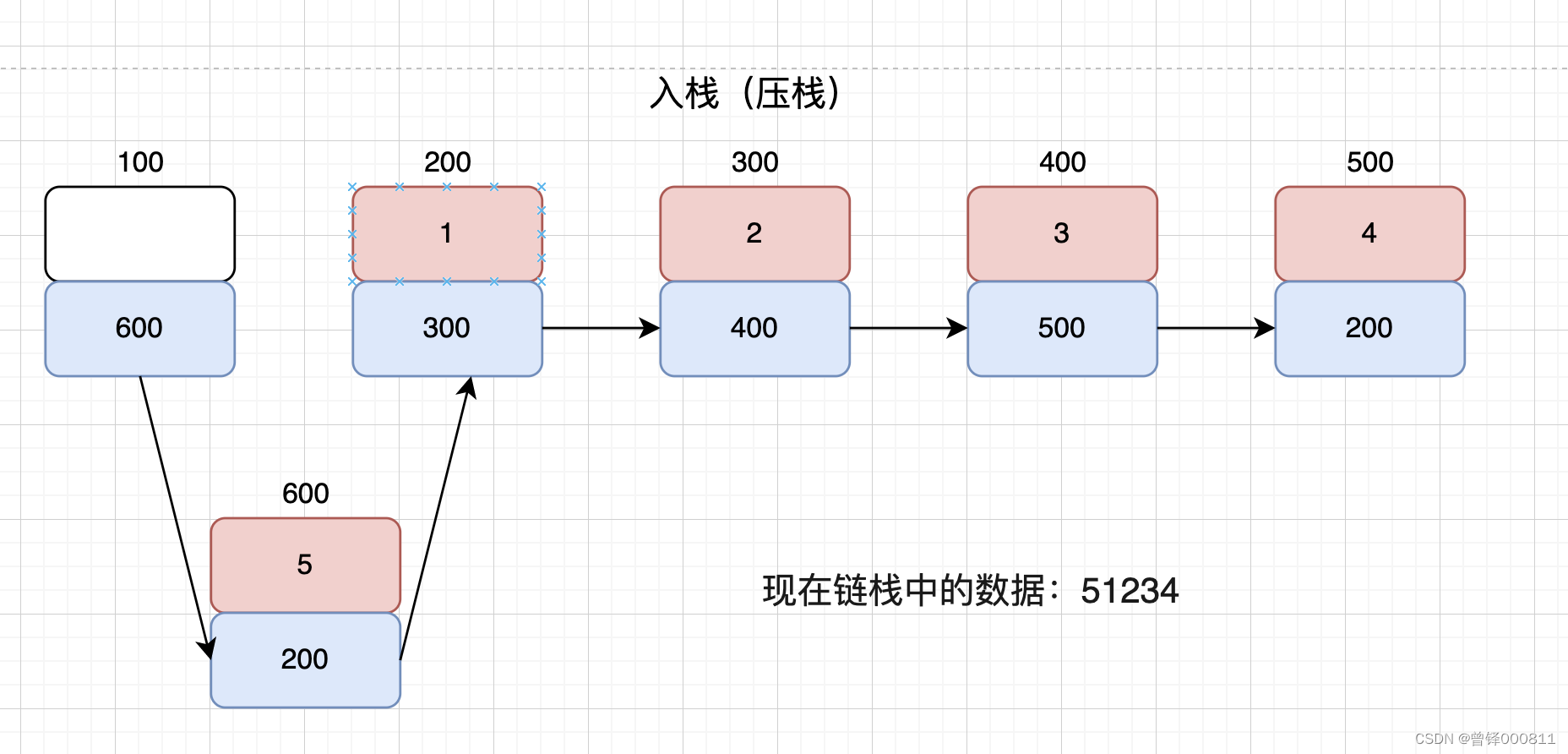
bool Push(PStack cstack,Elem_type val)
{
assert(cstack != nullptr);
PStack pnewnode = (PStack)malloc(1 * sizeof(Stack));
assert(pnewnode != nullptr);
pnewnode->data = val;
pnewnode->next = cstack->next;
cstack->next = pnewnode;
return true;
}出栈函数(Pop):
此时的出栈函数相当于单链表中的头删函数,首先对链表进行判空,如果链表为空,则直接返回为假。定义结构体类型指针p指向头节点之后的第一个有效节点,所以这时候p的next域保存的就是第二个有效节点的地址,然后我们进行跨越指向操作,将第二个有效节点的地址赋值给头节点的next域即可,如图:

bool Pop(PStack cstack)
{
assert(cstack != nullptr);
if(IsEmpty(cstack)){
return false;
}
PStack p = cstack->next;
assert(p != nullptr);
cstack->next = p->next;
return true;
}返回栈顶元素函数(Top):
返回元素的类型为我们之前设置的链栈元素范型,定义结构体类型指针p指向头节点之后的第一个有效节点,定义循环,循环条件为p等于空地址,此时p就能遍历到末尾节点,然后我们将末尾节点的数据域中的值返回即可。
Elem_type top(PStack cstack)
{
assert(cstack != nullptr);
PStack p = cstack->next;
for(;p != nullptr;p = p->next);
printf("%3d",p->data);
}判空函数(IsEmpty):
当头节点的next域为空,则代表整个链栈为空。
bool IsEmpty(PStack cstack)
{
assert(cstack != nullptr);
return cstack->next == nullptr;
}获取有效数据个数函数(Get_Length):
定义count整形值,定义结构体类型指针p指向头节点之后的第一个有效节点,p每向后走一位count的值就加1,最后将count的值返回即可。
int Get_Length(PStack cstack)
{
assert(cstack != nullptr);
int count = 0;
PStack p = cstack->next;
for(;p != nullptr;p = p->next){
count++;
}
return count;
}
测试:
测试初始化函数、打印函数:
对链栈进行初始化,并将10个元素通过入栈函数填充至其中,将链栈中的元素打印出来。
#include "Chain_Stack.h"
#include<cstdio>
int main()
{
Stack chain;
Init_Stack(&chain);
for(int i = 0;i < 10;i++){
Push(&chain,i + 1);
}
printf("原始数据为:\n");
Show(&chain);
return 0;
/*
此处添加其他测试代码...
*/
}运行结果:

测试清空函数:
Clear(&chain);
printf("\n经过清空操作之后的数据为:\n");
Show(&chain);运行结果:
测试销毁函数:
Destroy(&chain);
printf("\n经过销毁操作之后的数据为:\n");
Show(&chain);运行结果:
 测试查找函数:
测试查找函数:
我们要在链栈中查找的元素为2:
PStack p = Search(&chain,2);
printf("\n元素2在链栈中的地址为:%p\n",p);运行结果:
 测试入栈函数:
测试入栈函数:
对链栈初始化完成之后,再将11入栈:
Push(&chain,11);
printf("\n经过入栈操作之后的数据为:\n");
Show(&chain);运行结果:
测试出栈函数:
Pop(&chain);
printf("\n经过一个出栈后的数据为:\n");
Show(&chain);运行结果:

测试返回栈顶元素函数:
printf("\n栈顶元素为:%3d",top(&chain));运行结果:
总结:
顺序栈的实现在于使用了数组这个基本数据结构,数组中的元素在内存中的存储位置是连续的,且编译器要求我们在编译期就要确定数组的大小,这样对内存的使用效率并不高,因为内存总是一块一块儿的,无法避免因数组空间用光而引起的溢出问题,二在系统将内存分配给数组后,则这些内存对于其他任务就不可用;而对于链栈而言,使用了链表来实现栈,链表中的元素存储在不连续的地址,由于是动态申请内存,所以我们可以以非常小的内存空间开始,另外当某个项不使用时也可将内存返还给系统。
链栈时栈这种抽象数据类型的第二种表现形式,总体难度相对偏低,当然这是建立在你对单链表的构造和代码相当熟悉的前提下,书写链式栈也相当于是我们再次练习了单链表的相关代码,同时,掌握链栈也是比较重要的。
参考资料:
严蔚敏、吴伟民 - 《数据结构(C语言版)》