目录
源文件(Double_Linked_List)对函数功能的具体实现:

引言:
数据结构学习目录:
数据结构系列学习(一) - An Introduction to Data Structure
数据结构系列学习(二) - 顺序表(Contiguous_List)
数据结构系列学习(三) - 单链表(Linked_List)
数据结构系列学习(四) - 单向循环链表(Circular Linked List)
在上一篇文章中,我们学习了单项循环链表的理论知识并使用代码对它进行了实现,在链式存储结构中还有另外一种表现形式——双向链表。在我们之前学习的单链表或者单向循环链表中,链表中的每一个节点保存的都是它的后继节点的地址,而我们今天将要介绍和学习的双向链表却不一样,双向链表中的节点既能保存它的后继节点的地址,也能保存它的前驱节点的地址。这也是他为什么叫做双向链表的原因。
学习:
双向链表和单链表不同,双向链表每一个节点既保存后继节点的地址,又保存前驱节点的地址。
为什么会有双向链表?
在严蔚敏的《数据结构(C语言版)》中是这样说的,链式存储结构中只有一个指示直接后继的指针域,由此,从某个节点出发只能顺指针往后寻查其他节点。为克服单链表这种单向性的缺点,就产生了双向链表。
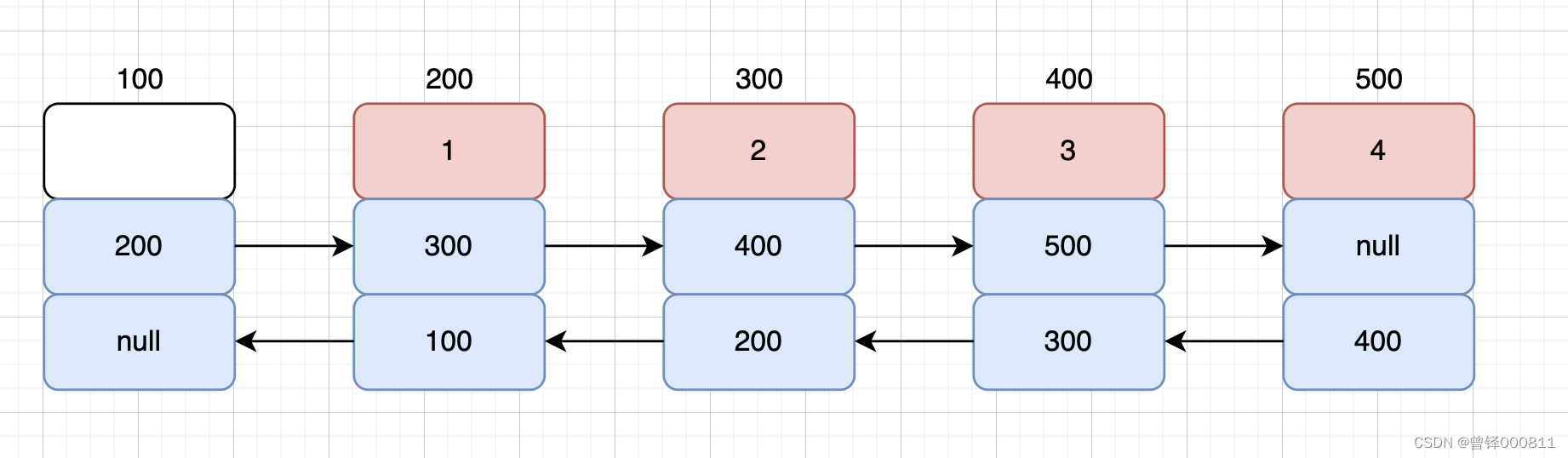
双向链表存在的意义:每个节点既可以找到直接后继,也可以找到直接前驱。且每一个节点既可以向后走,也可以向前走,相当于是对单链表的改进,如图:
代码实现:
双向链表中我们要实现的功能(15个):
初始化函数(Init_dlist);
清空函数(Clear);
销毁函数(无线头删)(Destroy1);
销毁函数(双指针协作释放节点)(Destroy2);
打印函数(Show);
查找函数(Search);
获取有效长度函数(Get_Length);
判空函数(IsEmpty);
头插函数(Insert_head);
尾插函数(Insert_tail);
按位置插函数(Insert_pos);
头删函数(Delete_head);
尾删函数(Delete_tail);
按位置删函数(Delete_pos);
按值删函数(Delete_val);
头文件(Double_Linked_List):
结构体的设计:
顾名思义,双向链表中有两个指针域分别是保存上一个节点地址的前驱(prior域),和保存下一个节点地址的后继(next域),还有保存数据的data域,如图:

所以我们就根据双向链表的结构来对双向链表进行结构的设计:
typedef int Elem_type;
typedef struct DNode
{
Elem_type data;
struct DNode* next;
struct DNode* prior;
}DNode, *PDnode;函数的声明:
void Init_dlist(PDnode dlist);
void Clear(PDnode dlist);
void Destroy(PDnode dlist);
void Destroy1(PDnode dlist);
void Show(PDnode dlist);
struct DNode* Search(PDnode dlist,Elem_type val);
int Get_Length(PDnode dlist);
bool IsEmpty(PDnode dlist);
bool Insert_head(PDnode dlist,Elem_type val);
bool Insert_tail(PDnode dlist,Elem_type val);
bool Insert_pos(PDnode dlist,int pos,Elem_type val);
bool Delete_head(PDnode dlist);
bool Delete_tail(PDnode dlist);
bool Delete_pos(PDnode dlist,int pos);
bool Delete_val(PDnode dlist,Elem_type val);源文件(Double_Linked_List)对函数功能的具体实现:
初始化函数(Init_dlist):
因为双向链表的节点由三部分组成,分别是:数据域、next域(后继)、prior域(前驱),我们在对双向链表进行初始化的时候,首先明确初始阶段没有任何有效节点,所以初始数据域不存放任何数据,再将next域和prior域赋值为空即可。
void Init_dlist(PDnode dlist)
//如果没有有效节点,则双向链表的头节点,应该:头节点的数据域浪费掉,不使用,头节点的next域
{
assert(dlist != nullptr);
dlist->next = nullptr;
dlist->prior = nullptr;
}清空函数(Clear):
前文中提到,链表中清空和销毁的含义一样,所以我们直接再清空函数中调用销毁函数即可。
void Clear(PDnode dlist)
{
Destroy(dlist);
}销毁函数(无线头删)(Destroy1):
销毁链表的第一种方式:当链表不为空,我们无限次调用头删函数直到将链表中所有的节点删除完。
void Destroy(PDnode dlist)//无线头删
{
while(!IsEmpty(dlist)){
Delete_head(dlist);
}
}销毁函数(双指针协作释放节点)(Destroy2):
销毁链表的第二种方式:两个指针配合对节点进行释放。首先我们将头节点断开(将头节点的next域置空),定义结构体类型指针p指向第一个有效节点,定义结构体类型指针q并置空。定义循环,使用p指针遍历链表。p每指向一个节点就将q的next域赋值给q,然后再将q指针释放,再将q复制给p。
void Destroy1(PDnode dlist)//两个指针辅助
{
assert(dlist != nullptr);
PDnode p = dlist->next;
PDnode q = nullptr;
dlist->next = nullptr;
while(p != nullptr){
q = q->next;
free(p);
p = q;
}
}打印函数(Show):
定义结构体类型指针p指向第一个有效节点,定义循环。p每遍历到一个节点就将p所指向节点的数据域中的值打印出来。
void Show(PDnode dlist)
{
assert(dlist != nullptr);
PDnode p = dlist->next;
for(;p != nullptr;p = p->next){
printf("%5d",p->data);
}
printf("\n");
}查找函数(Search):
定义结构体类型指针p指向头节点之后的第一个有效节点,定义循环,检查在p遍历整个链表的过程中检查指针p指向节点中的数据域中的值是否等于要查找的值,如果如果等于则返回该节点的地址,如果没有找到,则返回空地址。
struct DNode* Search(PDnode dlist,Elem_type val)
{
assert(dlist != nullptr);
PDnode p = dlist->next;
for(;p->next != nullptr;p = p->next){
if(p->data == val){
return p;
}
}
return nullptr;
}获取有效长度函数(Get_Length):
定义count整形值用来记录有效节点的个数,定义结构体类型指针p指向头节点之后的第一个有效节点,定义循环,循环条件为p不等于空,每遍历到一个有效节点count的值就加一,函数的最后返回count的值。
int Get_Length(PDnode dlist)
{
assert(dlist != nullptr);
int count = 0;
PDnode p = dlist->next;
for(;p != nullptr;p = p->next){
count++;
}
return count;
}判空函数(IsEmpty):
当头节点的next域为空,则代表整个链表没有有效节点,意思就是链表为空。
bool IsEmpty(PDnode dlist)
{
return dlist->next == nullptr;
}头插函数(Insert_head):
在写头插函数之前,我们需要考虑到当我们向堆区申请pnewnode的内存空间之后,我们应该如何更改pnewnode和它的前后节点的指向性问题?
如图:

首先我们需要做的就是修改pnewnode本身数据域和之阵雨,将要插入的数值放入pnewnode的数据域,将原先头节点的next域中存放的地址(也就是下一个有效节点的地址)赋值给pnewnode的next域,然后我们再将头节点的地址复制给pnewnode的prior域。这个时候问题来了,我们是先修改头节点的next域还是先修改第二个有效节点的prior域呢?这个问题在我们在之前单链表的时候就遇到过,当我们进行节点的添加时,如果我们先修改新节点之前的节点的next域就会导致后续节点地址的丢失,计算机将无法找到后续节点。那么同样的道理,我们在双向链表中,如果先修改头节点的next域势必会造成后续节点地址的丢失。所以我们正确的做法应该是先修改原先第一个有效节点的prior域,再来修改头节点的next域。
注意:如果此时链表中只有一个头节点的话,我们只需要修改头节点的next域和pnewnode的prior域,再将pnewnode的next域赋值为空即可。
所以总的来说修改指针指向的步骤应该就是:新节点的next域和prior域、后节点的prior域,前节点的next域。
bool Insert_head(PDnode dlist,Elem_type val)
{
assert(dlist != nullptr);
PDnode pnewnode = (PDnode) malloc(1 * sizeof(DNode));
//先修改pnewnode自身的两个域,再处理下一个节点的prior域,最后处理上一个节点的next域
assert(pnewnode != nullptr);
pnewnode->data = val;
pnewnode->next = dlist->next;//1
pnewnode->prior = dlist;
if(dlist->next != nullptr) {
dlist->next->prior = pnewnode;
}
dlist->next = pnewnode;
return true;
}尾插函数(Insert_tail):
我们首先向堆区申请新节点内存(pnewnode),将要插入的数据保存在申请的新节点之中的data域中,定义结构体类型指针p指向头节点,定义循环,循环条件为p不等于空,将p的next域复制给p,这时p就指向了末尾节点。然后我们修改指针的指向,原先末尾节点的next域(nullptr)值赋值给pnewnode的next域,将原先末尾节点的地址赋值给pnewnode的prior域,这时我们再来将pnewnode的地址复制给原先末尾节点的next域即可,如图:
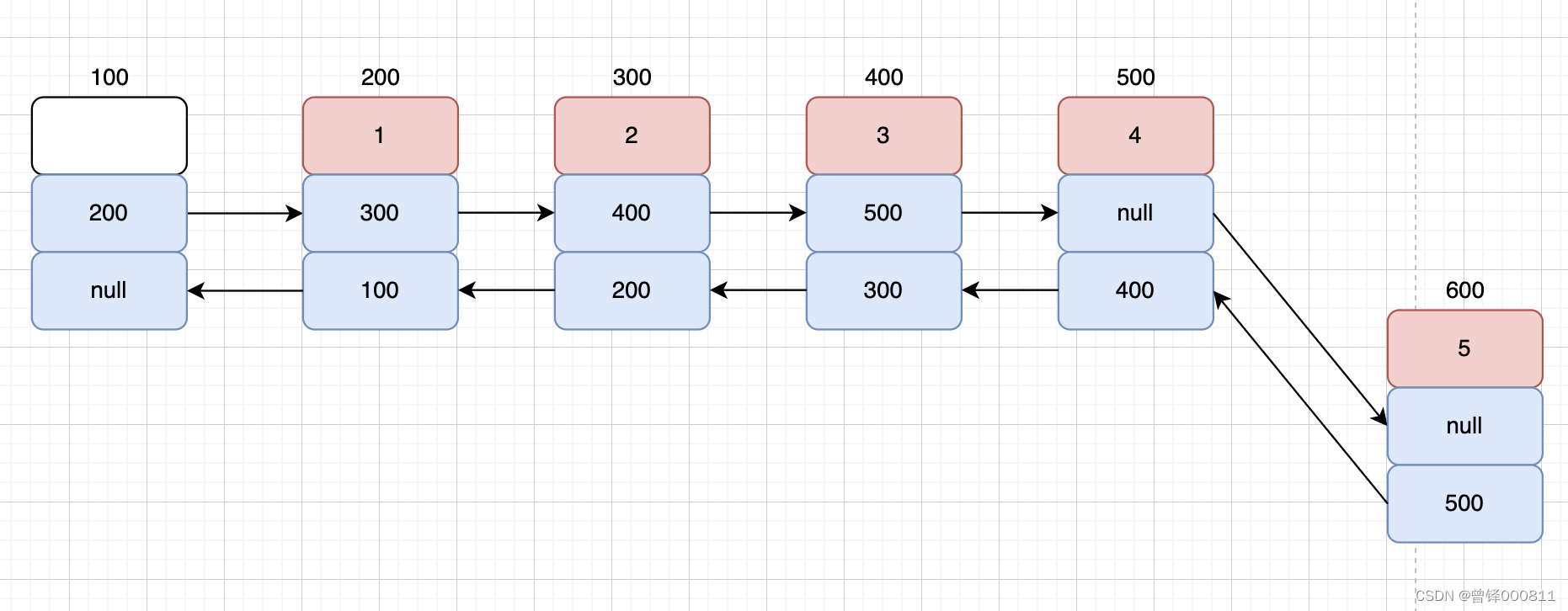
bool Insert_tail(PDnode dlist,Elem_type val)//不存在特殊情况 每一种情况都是修改三个指针域
{
assert(dlist != nullptr);
PDnode pnewnode = (PDnode) malloc(1 * sizeof(DNode));
assert(pnewnode != nullptr);
pnewnode->data = val;
PDnode p = dlist;
for(;p->next != nullptr;p = p->next);
pnewnode->next = p->next;
pnewnode->prior = p;
p->next = pnewnode;
return true;
}按位置插函数(Insert_pos):
我们首先向堆区申请新节点内存(pnewnode),将要插入的数据保存在申请的新节点之中的data域中,当pos为0时,直接调用我们之前写过的头插函数,当pos等于整个链表的长度 - 1时,直接调用我们之前写过的尾插函数。如果这两种情况都不是,那就是中间位置插入,定义结构体类型指针p指向头节点,定义循环定位指针p到插入位置,然后我们修改指针的指向,将p的next域(插入位置之后节点的地址)赋值给pnewnode的next域,然后我们将p指针的地址(插入位置之前的节点的地址)复制给pnewnode的prior域,然后我们将pnewnode自身的地址赋值给插入位置之后的节点的prior域,然后再修改p指针(插入位置之前节点)的next域,将pnewnode自身的地址复制给p的next域即可,如图:

bool Insert_pos(PDnode dlist,int pos,Elem_type val)//当pos==0的时候是头插 当pos等于length的时候是尾插,其他位置pos >0 && pos < length 的时候是中间插入
{
assert(dlist != nullptr);
assert(pos >= 0 && pos <= Get_Length(dlist));
PDnode pnewnode = (PDnode) malloc(1 * sizeof(DNode));
assert(pnewnode != nullptr);
pnewnode->data = val;
if(pos == 0){
return Insert_head(dlist,val);
}
else if(pos == Get_Length(dlist) - 1){
return Insert_tail(dlist,val);
}
PDnode p = dlist;
for(int i = 0;i < pos;i++){//当pos等于几
p = p->next;
}
pnewnode->next = p->next;//1
pnewnode->prior = p;//2
p->next->prior = pnewnode;//4
p->next = pnewnode;//3
return true;
}头删函数(Delete_head):
在写头删函数之前,我们首先要对链表进行判空,此时我们应该考虑第一种情况,如果链表此时只有一个有效节点,那么我们只需要将头节点的next域置空即可。如果有效节点的个数大于1,定义结构体类型指针p指向链表的第一个有效节点,将p的next域(也就是第二个有效节点的地址)复制给头节点的next域,再将头节点的地址赋值给第二个有效节点的prior域即可,如图:
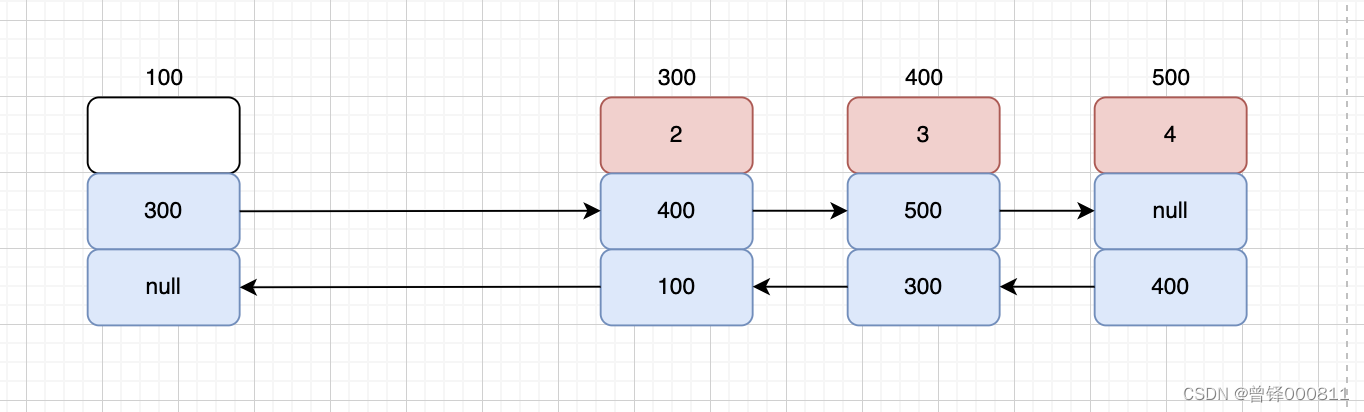
bool Delete_head(PDnode dlist)
{
assert(dlist != nullptr);
if(IsEmpty(dlist)){
return false;
}
if(dlist->next->next == nullptr){
dlist->next = nullptr;
}
PDnode p = dlist->next;
dlist->next = p->next;
p->next->prior = dlist;
free(p);
return true;
}尾删函数(Delete_tail):
首先对链表进行判空,定义结构体类型指针p指向头节点,定义循环使p指向尾节点,定义结构体类型指针q指向头节点,定义循环,循环条件为q的next域不等于p,再将q的next域赋值给p,p则指向了倒数第二个节点,现在我们将p的next域(也就是nullptr) 赋值给q的next域即可,如图:
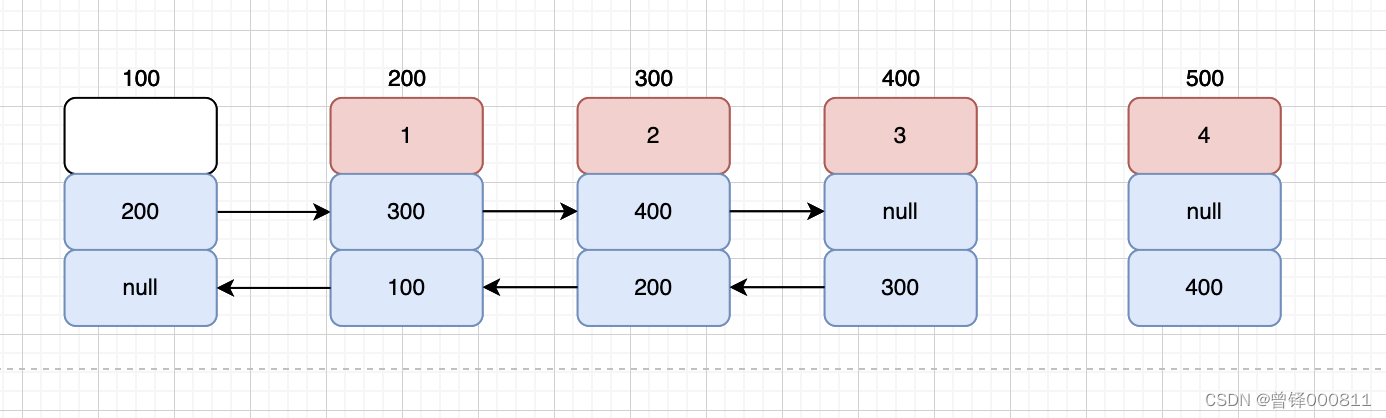
bool Delete_tail(PDnode dlist)
{
//尾删不存在特殊情况,因为待删除节点就是尾节点,且待删除节点的后一个节点永远永远不存在
assert(dlist != nullptr);
if(IsEmpty(dlist)){
return false;
}
PDnode p = dlist;
for(;p->next != nullptr;p = p->next);
PDnode q = dlist;
for(;q->next != p;q = q->next);
q->next = p->next;
free(p);
return true;
}按位置删函数(Delete_pos):
首先对链表进行判空,如果pos为0的话直接调用我们之前写过的头删函数即可,如果pos等于链表有效长度减1的话直接调用我们之前写过的尾删函数即可,如果既不是头删也不是尾删那就是中间位置删除。定义结构体类型指针q指向指向头节点,定义循环,循环条件为i < pos,循环完成后将q的next域赋值个q,q则指向待删除位置的前一个节点,q的next域的则代表待删除位置的下一个节点,定义结构体类型指针p,将q的next域赋值个给p,此时p就指向了待删除节点,然后我们进行跨越指向操作,我们将待删除节点下一个节点的地址(也就是p的next域)赋值给待删除节点上一个节点的next域(也就是q的next域),然后然后我们再将q指向节点的地址赋值给p的prior域即可,如图:
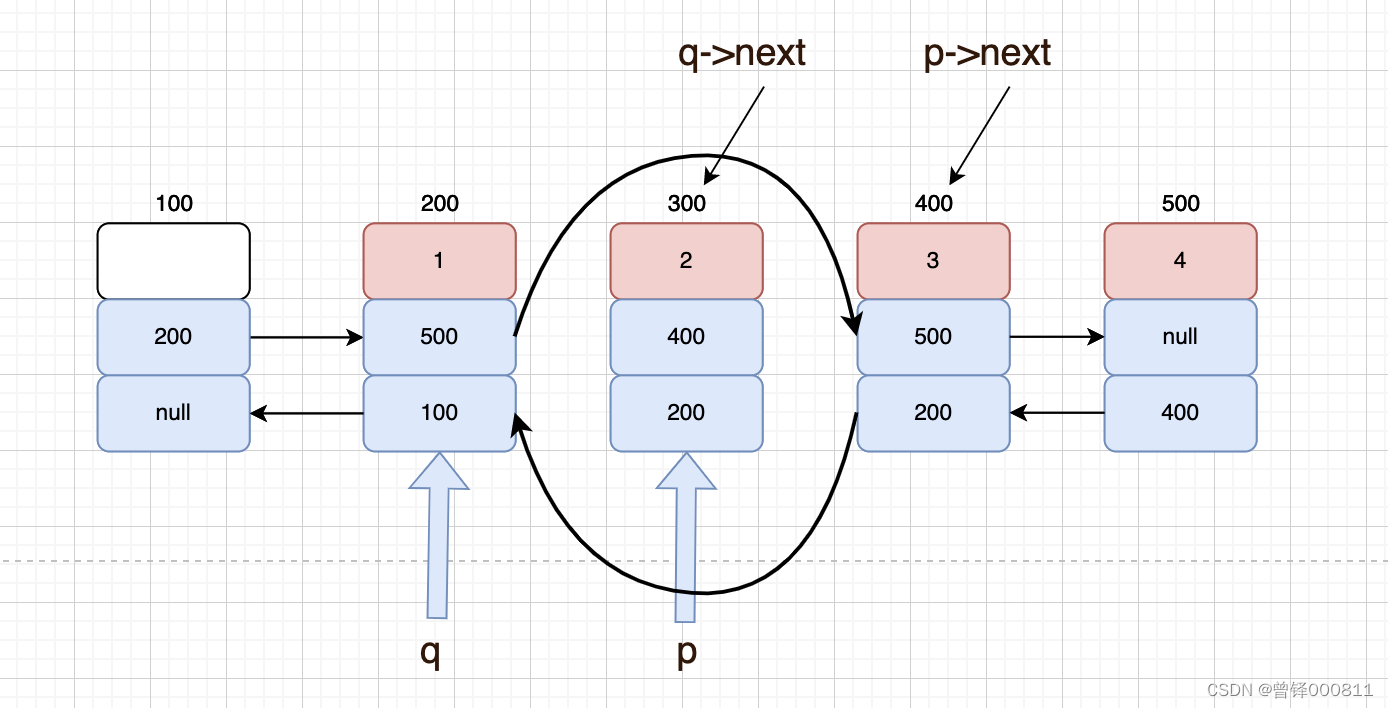
bool Delete_pos(PDnode dlist,int pos)
{
assert(dlist != nullptr);
assert(pos >= 0 && pos < Get_Length(dlist));
if(IsEmpty(dlist)){
return false;
}
//头删的情况
if(pos == 0){
return Delete_head(dlist);
}
//尾删的情况
if(pos == Get_Length(dlist) - 1){
return Delete_tail(dlist);
}
//既不是头删也不是尾删的情况——中间位置的删除,需要统一修改两个指针域
PDnode q = dlist;
for(int i = 0;i < pos;i++){
q = q->next;
}
PDnode p = q->next;
q->next = p->next;
p->next->prior = q;
free(p);
return true;
}按值删函数(Delete_val):
首先对链表进行判空如果链表为空则返回为假。定义结构体类型指针p用来保存查找函数所返回的地址,如果保存的地址为空则返回为假,如果不为空则p指向待删除节点,定义结构体类型指针q指向头节点,定义循环,循环条件为q的next域不为空,我们再将q的next域赋值给q,则q此时指向p节点前一个节点的地址,这里我们考虑一种特殊情况,如果链表中只有一个有效节点(也就是p的next域为空)那么我们直接将q的next赋值为空即可,如果有效节点的个数大于1,我们再进行跨越指向操作,将待删除节点后一个节点的地址赋值给前一个节点的next域,再将待删除节点前一个节点的地址复制给后一个节点的prior域,如图:
bool Delete_val(PDnode dlist,Elem_type val)
{
assert(dlist != nullptr);
if(IsEmpty(dlist)){
return false;
}
PDnode p = Search(dlist,val);
if(p == nullptr){
return false;
}
PDnode q = dlist;
for(;q->next != p;q = q->next);
if(p->next == nullptr){
q->next = nullptr;
}
else{
q->next = p->next;
p->next->prior = q;
}
free(p);
return true;
}测试:
测试初始化函数、打印函数:
#include<cstdio>
#include<cassert>
#include<cstdlib>
#include "Double_Linked_List.h"
int main()
{
DNode head;
Init_dlist(&head);
for(int i = 0;i < 10;i++){
Insert_pos(&head,i,i + 1);
}
printf("原始数据为:\n");
Show(&head);
/*
其他函数的测试代码在此添加...
*/
}运行结果:
测试头插函数:
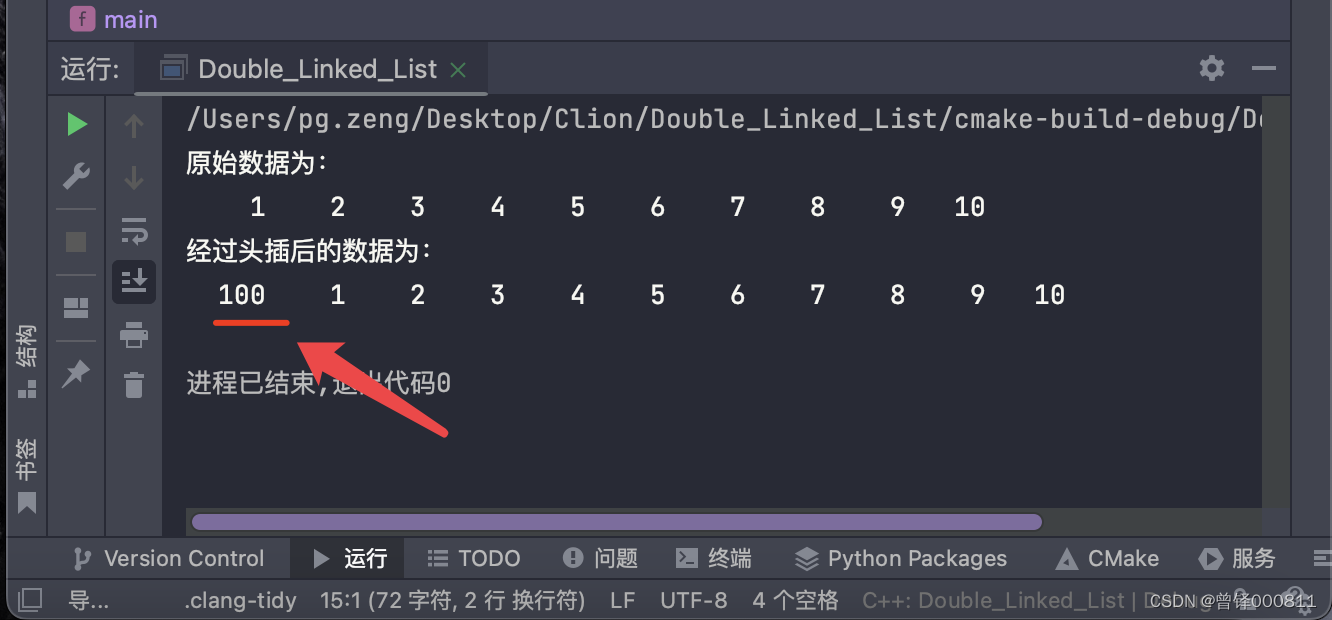
我们将100插入至链表的头部:
printf("经过头插后的数据为:\n");
Insert_head(&head,100);
Show(&head);运行结果:
测试尾插函数:
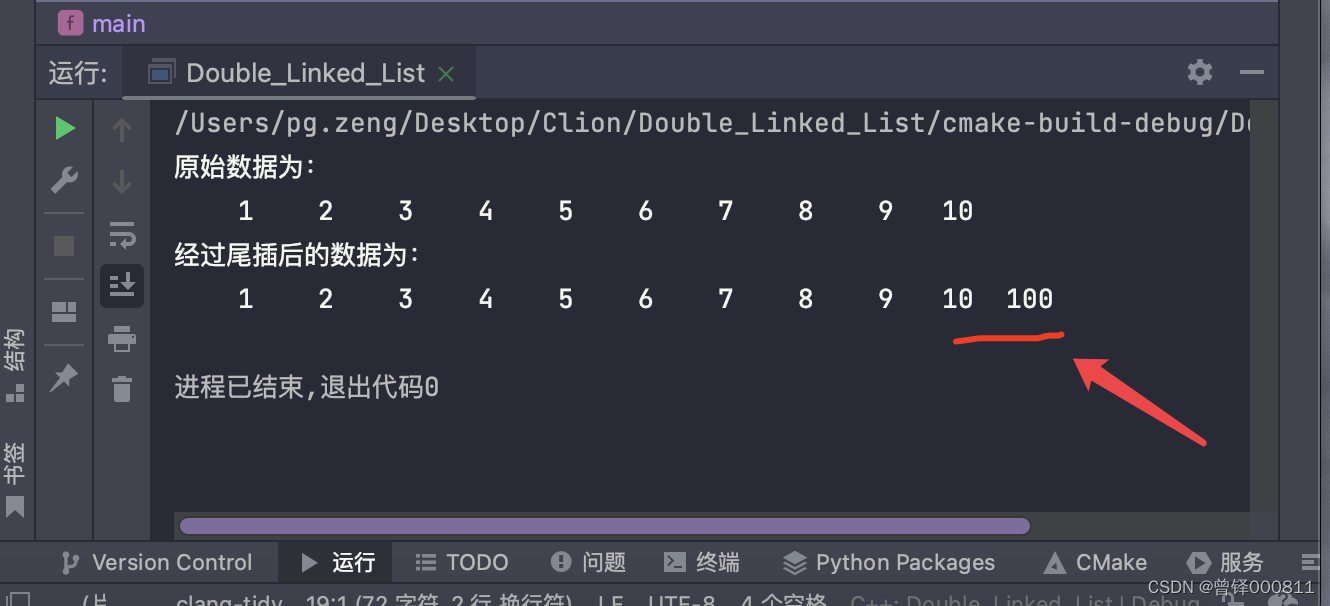
我们将100插入至链表的尾部:
printf("经过尾插后的数据为:\n");
Insert_tail(&head,100);
Show(&head);运行结果:
测试按位置插函数:
我们将100插入至链表的第二个有效节点之后:
printf("经过按位置插后的数据为:\n");
Insert_pos(&head,2,100);
Show(&head);运行结果:
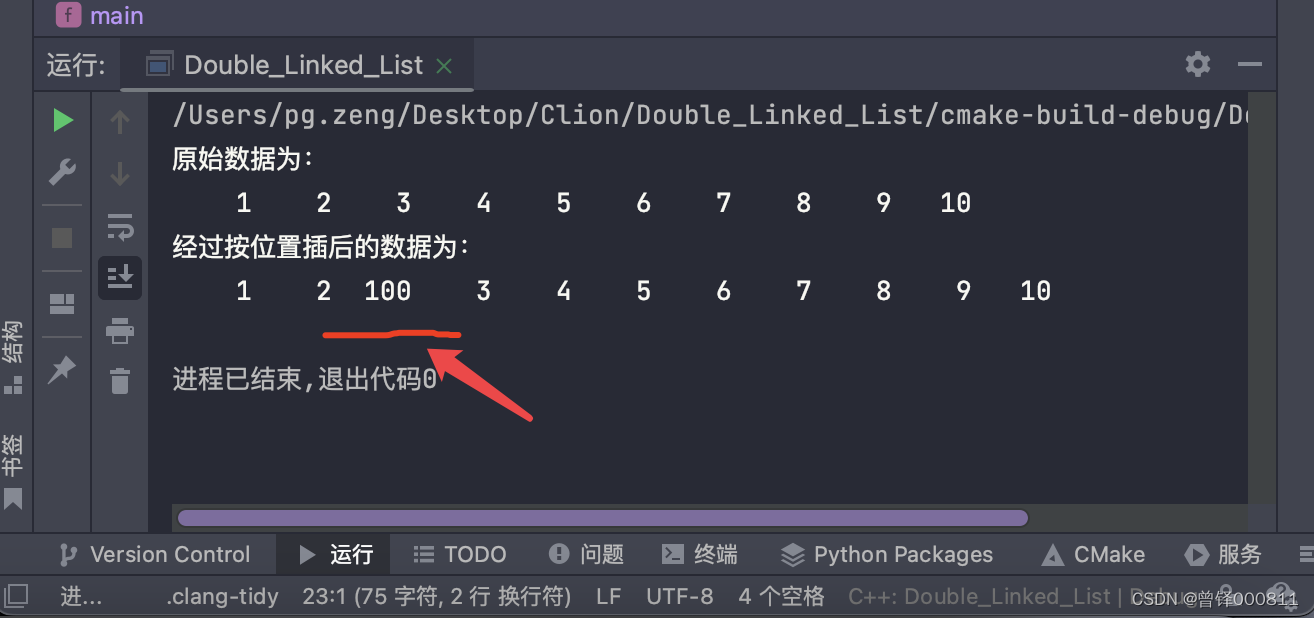
测试头删函数:
我们对链表的头部元素进行删除操作:
printf("经过头删后的数据为:\n");
Delete_head(&head);
Show(&head);运行结果;
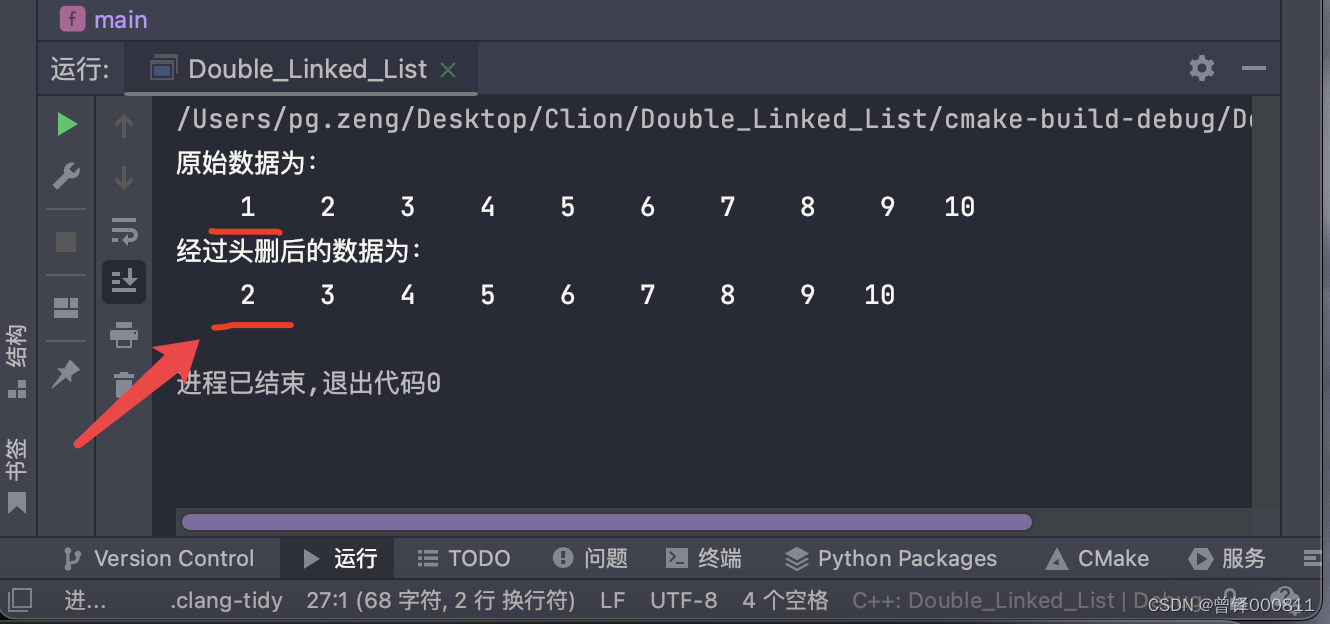
测试尾删函数:
我们对链表的尾部元素进行删除:
printf("经过尾删后的数据为:\n");
Delete_tail(&head);
Show(&head);运行结果:
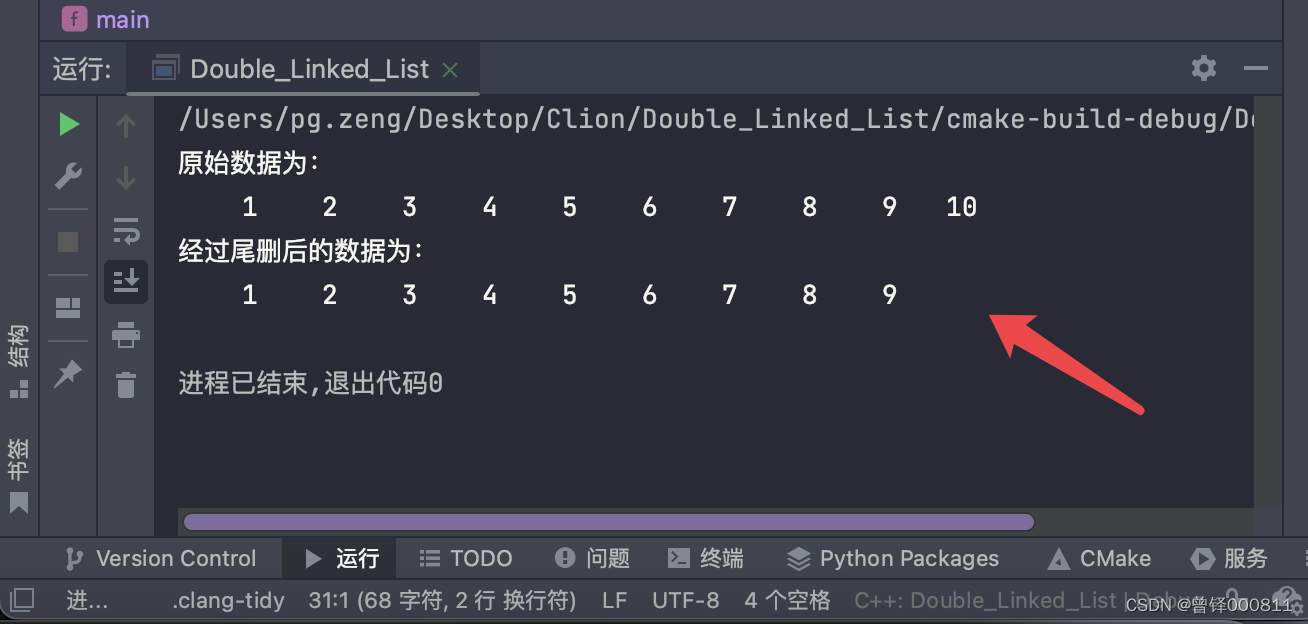
测试按位置删函数:
我们删除链表第四个有效节点之后的元素:
printf("经过按位置删后的数据为:\n");
Delete_pos(&head,4);
Show(&head);运行结果:
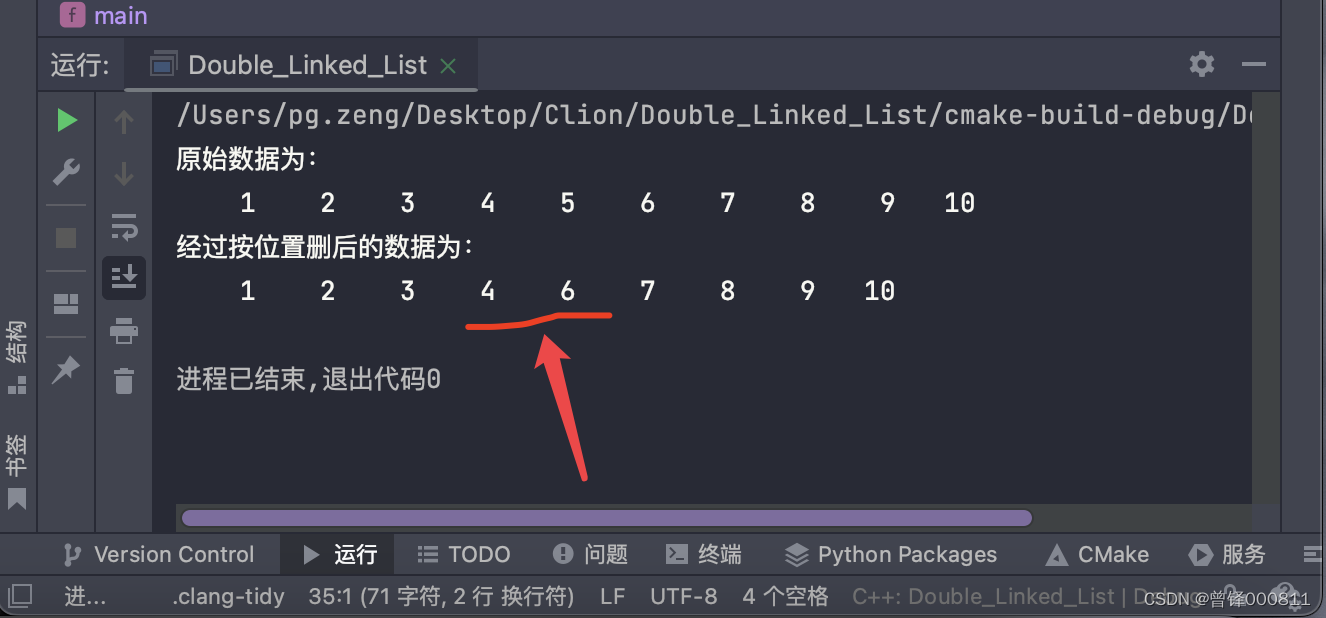
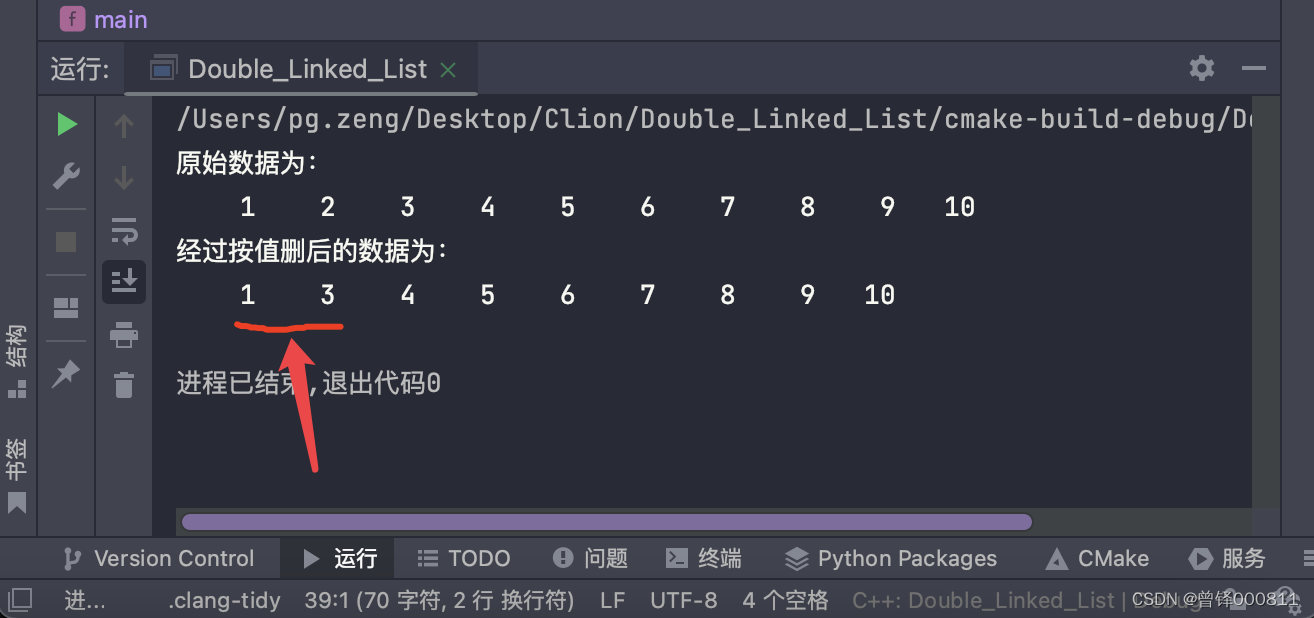
测试按值删函数:
我们要删除链表中的元素2:
printf("经过按值删后的数据为:\n");
Delete_val(&head,2);
Show(&head);运行结果;
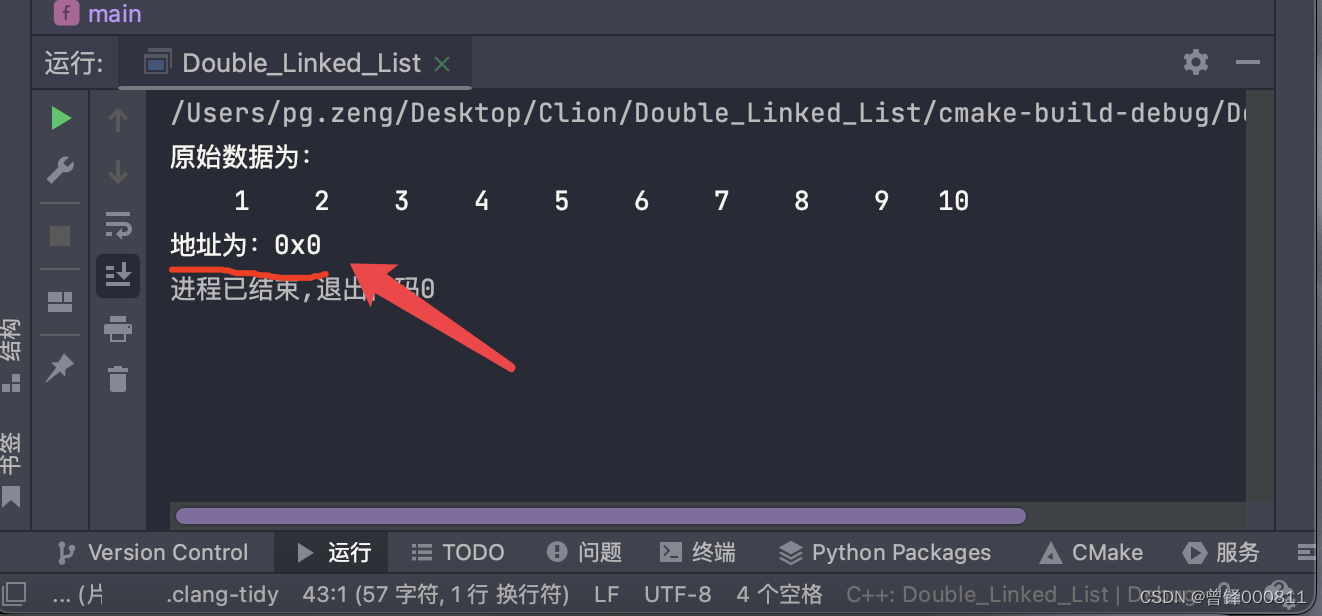
测试查找函数:
查找链表中是否有元素4:
PDnode p = Search(&head,4);
printf("地址为:%p",p);运行结果:

查找链表中是否有元素100:
PDnode p = Search(&head,100);
printf("地址为:%p",p);运行结果:
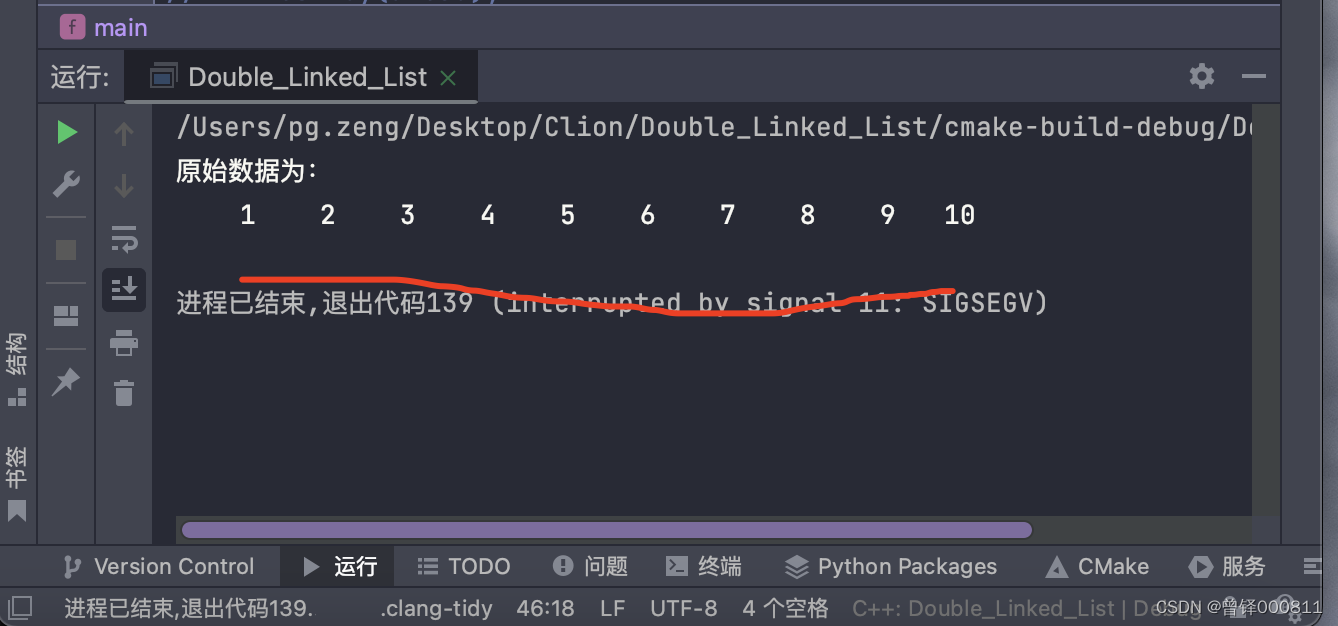
测试清空函数:
Clear(&head);
Show(&head);运行结果:
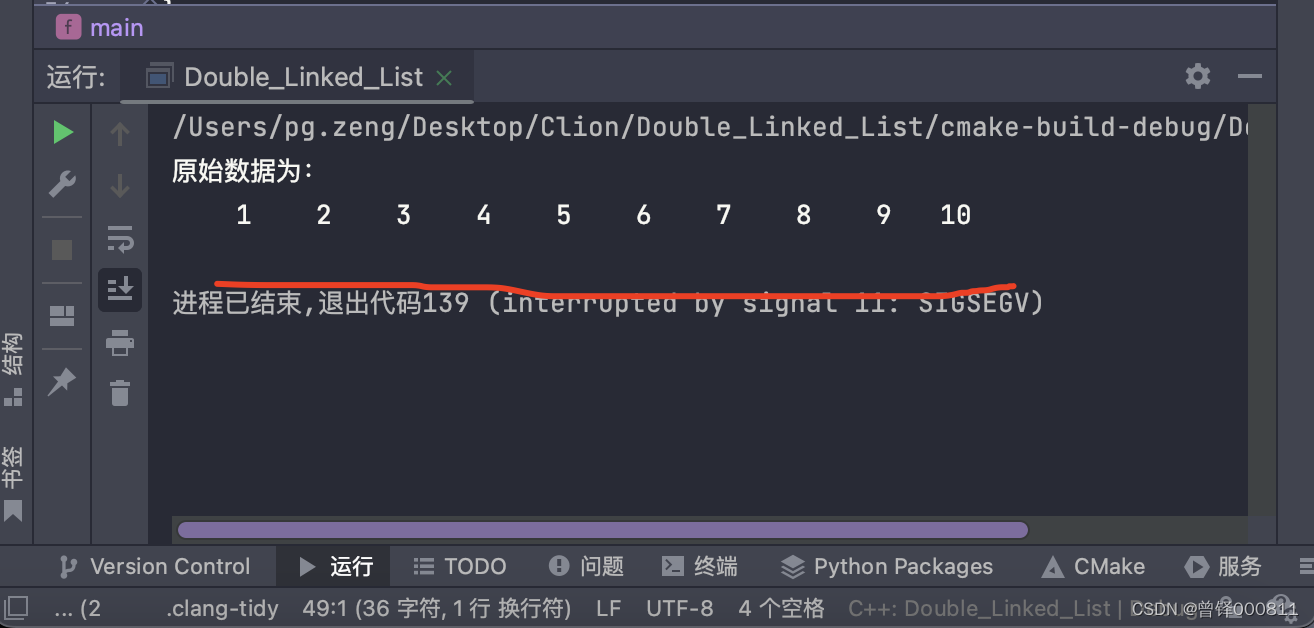
测试销毁函数1:
Destroy(&head);
Show(&head);运行结果:
测试销毁函数2:
Destroy1(&head);
Show(&head);运行结果:
总结:
双向链表是对单链表的优化,克服了链表只能从前往后走的缺点,在双向链表中每一个节点既有能保存上一个节点地址的prior域,也有能保存下一个节点的next域,所以每一个节点既可以往后走也可以往前走,双向链表存在的意义就是从任意一个节点出发都能访问到链表中的任何一个节点。双向链表的难度相较于单链表要高一些,但在学习并了解了双向链表的原理之后,写出代码还是比较容易的,同时双向链表也比较重要,在Linux系统的进程中,就是使用的双向链表来对进程的地址进行保存,从而实现跨越访问,因此掌握双向链表的知识和独立书写出代码是非常重要的。