题目1
将下面的程序编译、连接,用 Debug 加载、跟踪,然后回答问题
assume cs:code, ds:data, ss:stack
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ; 占16字节
data ends
stack segment
dw 1,2,3,4,5,6,7,8 ; 占16字节
stack ends
code segment
start: mov ax, stack ; 获取栈段
mov ss, ax ; 设置栈段
mov sp, 16 ; 设置栈顶 ss:sp
mov ax, data
mov ds, ax ; ds 指向 data 段
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax, 4c00h
int 21h
code ends
end start
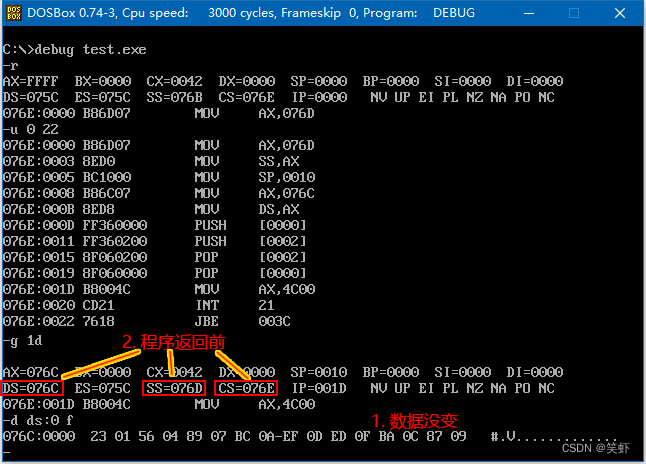
- CPU 执行程序,程序返回前,data 段中的数据为多少?
答:数据没变。先入后出,保持了顺序。 - CPU 执行程序,程序返回前,cs= 076E 、ss= 076D 、ds= 076C 。
- 设程序加载后,code 段的段地址为 X,则 data 段的段地址为= X-2 ,stack 段的段地址为 X-1 。
题目2
将下面的程序编译、连接,用 Debug 加载、跟踪,然后回答问题
assume cs:code, ds:data, ss:stack
data segment
dw 0123h,0456h
data ends
stack segment
dw 1,2
stack ends
code segment
start: mov ax, stack ; 获取栈段
mov ss, ax ; 设置栈段
mov sp, 16 ; 设置栈顶 ss:sp
mov ax, data
mov ds, ax ; ds 指向 data 段
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax, 4c00h
int 21h
code ends
end start
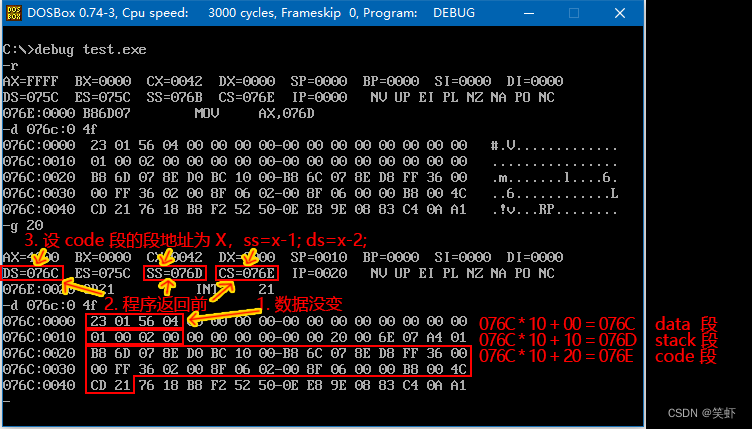
- CPU 执行程序,程序返回前,data 段中的数据为多少?
答:数据没变。先入后出,保持了顺序。 - CPU 执行程序,程序返回前,cs= 076E 、ss= 076D 、ds= 076C 。
- 设程序加载后,code 段的段地址为 X,则 data 段的段地址为= X-2 ,stack 段的段地址为 X-1 。
- 对于如下定义的段:如果段中的数据占N 个字节,则程序加载后,该段实际占有的空间为
n % 16 ? n + (16 - n % 16) : n字节。
到网上看到别人的公式( N/16+1) * 16,但当正好是16的倍数时,这个公式显示与观察到的效果不符。
name segment
...
name ends
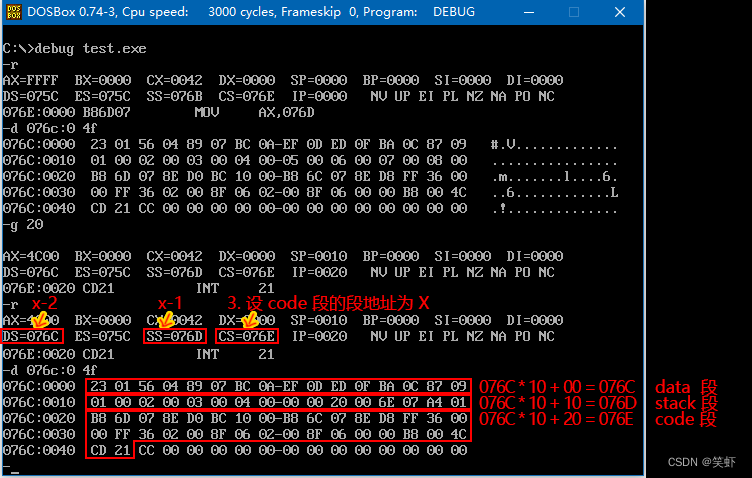
观察程序加载后CX=0042与题目1中相同,可知虽然只声明了4个字节,但是系统还是按16字节分配了内存。
可以看到数据段和栈段都是16字节。代码段从076C:0020开始。
看下通过观察推测的结果:
[...Array(9527).keys()].map(n => `${
n} = ${
n % 16 ? n + (16 - n % 16) : n}`)

题目3
将下面的程序编译、连接,用 Debug 加载、跟踪,然后回答问题
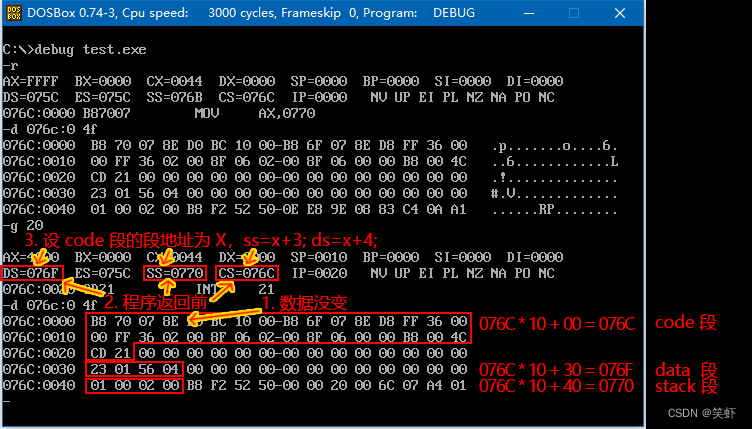
- CPU 执行程序,程序返回前,data 段中的数据为多少?
答:数据没变。先入后出,保持了顺序。 - CPU 执行程序,程序返回前,cs= 076C 、ss= 0770 、ds= 076F 。
- 设程序加载后,code 段的段地址为 X,则 data 段的段地址为= X+3 ,stack 段的段地址为 X+4 。
题目4
如果将(1)、(2)、(3)题中的最后一条伪指令“end start”改为“end”(也就是说不指明程序的入口),则哪个程序仍然可以正确执行?请说明原因。
答: 题目3的代码可以正常执行,因为代码段正好在程序开头。CS:IP指向第一行指令。
题目5
程序如下,编写 code 段中的代码,将 a段和 b 段中的数据依次相加,将结果存到c段中。
assume cs:code
a segment
db 1, 2, 3, 4, 5, 6, 7, 8 ; 占16字节
a ends
b segment
db 1, 2, 3, 4, 5, 6, 7, 8 ; 占16字节
b ends
d segment
db 0, 0, 0, 0, 0, 0, 0, 0 ; 占16字节
d ends
code segment
start: mov ax, a
mov ds, ax
mov bx, 0 ; i = 0
mov cx, 8 ; len = 8
s: mov al, ds:[bx]
add al, ds:[bx+16] ; 寄存器不够用,用偏移量来定位
mov ds:[bx+16+16], al ; 寄存器不够用,用偏移量来定位
inc bx ; i++
loop s ; i < len 循环
mov ax, 4c00h
int 21h
code ends
end start
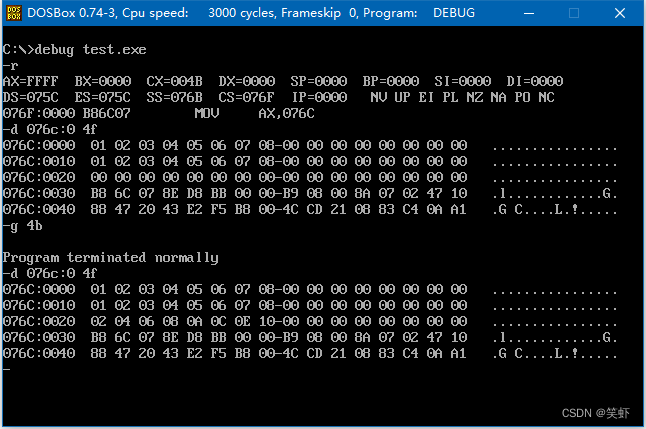
c segment编译不过,我就换成了d- 程序加载后可以看到 CS:IP 指向 076F:0
[bx+16+16]这种写法在第7章中会详细介绍。
题目6
程序如下,编写 code 段中的代码,用 push 指令将 a 段中的前 8 个字型数据,逆序存储到 b 段中。
assume cs:code
a segment ; CS-3
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh ; 占32字节
a ends
b segment ; CS-1
dw 0,0,0,0,0,0,0,0 ; 占16字节
b ends
code segment
start: mov ax, a
mov ds, ax
mov ax, b
mov ss, ax
mov sp, 10h
; 下面实现循环处理
mov bx, 0 ; i = 0
mov cx, 8 ; len = 8
s: push [bx] ; a 中取出第一个,放到 b末尾。压栈是从底往上走的
add bx, 2 ; i = i+2 字类型占两字节
loop s ; i < len 循环
mov ax, 4c00h
int 21h
code ends
end start
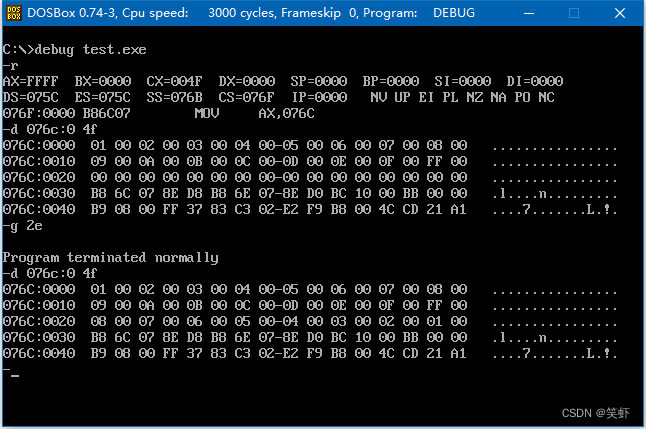
总结
- 系统分配内存16字节起步。
- 定义段,即可声明内容空间。一回事。
- 知道段的定义顺序,又知道它们的大小,可以能过偏移量算出各段的位置。