本实验为《汇编语言》(王爽著,第3版)第133页 实验 5
将下面的程序编译、连接,用
debug加载、跟踪。assume cs:code, ds:data, ss:stack data segment dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h data ends stack segment dw 0, 0, 0, 0, 0, 0, 0, 0 stack ends code segment start: mov ax,stack mov ss, ax mov sp,16 mov ax, data mov ds, ax push ds:[0] push ds:[2] pop ds:[2] pop ds:[0] mov ax,4c00h int 21h code ends end start编译和连接的步骤略。
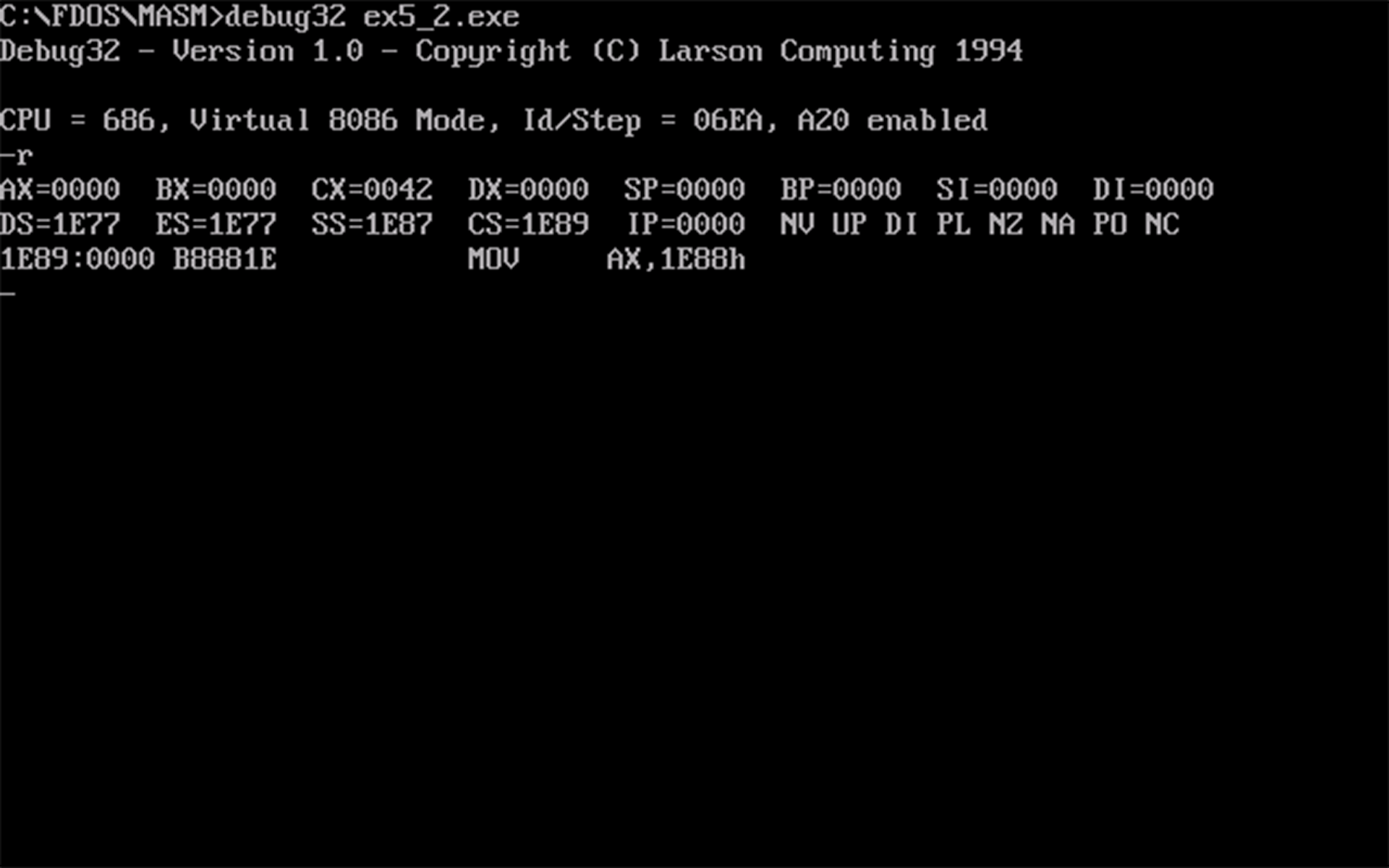
- 由
r命令查看cx的值得知,该程序总共占用42H个字节。现在扣除数据段和栈段的16个字数据 (共占用20H个字节) 可知代码段占用22H个字节。对cs:ip及其以后的22H个内存单元反汇编即可得知返回指令的地址,如下图所示:
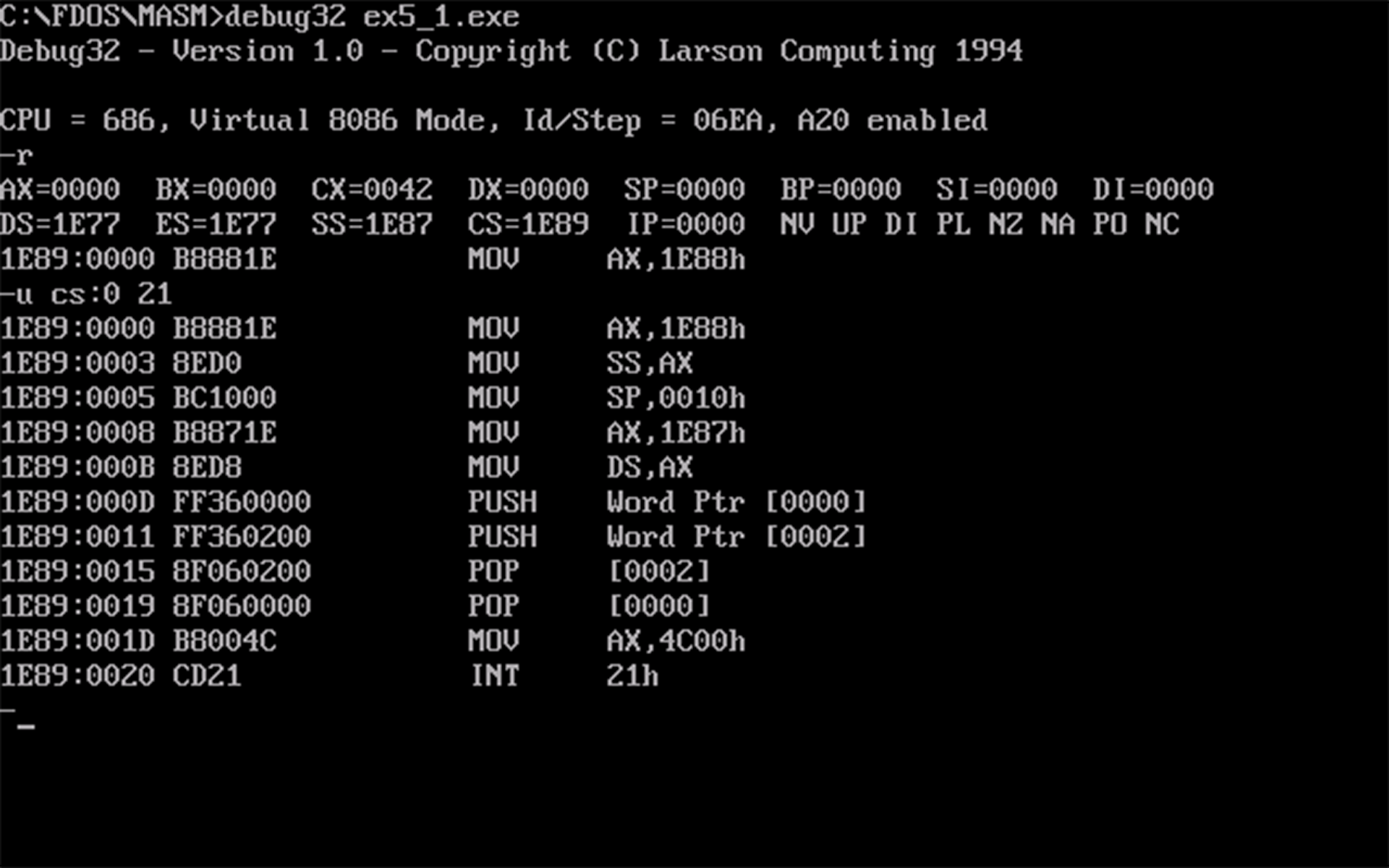
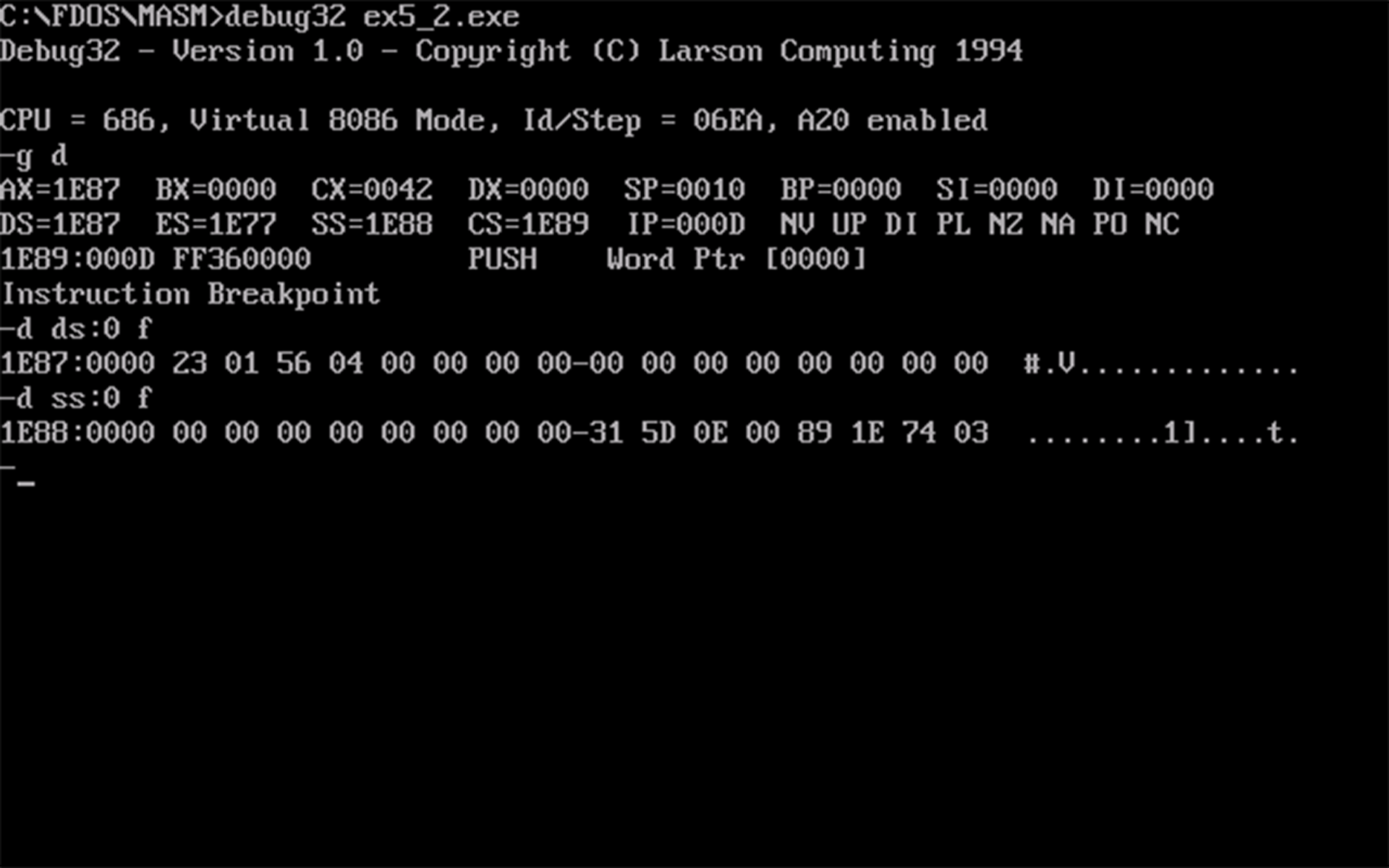
- 使用
g命令执行到返回指令之前,如下图所示:
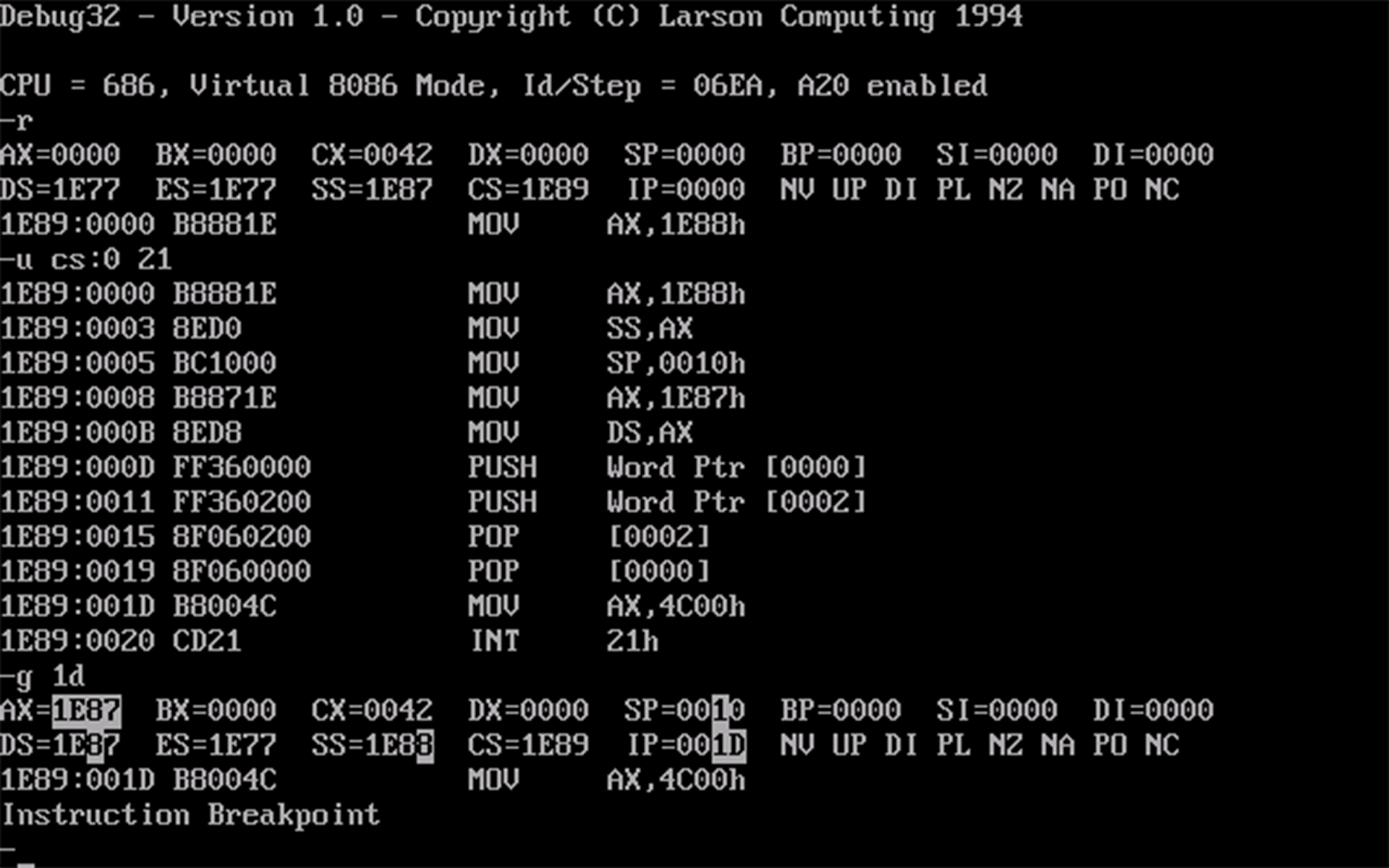
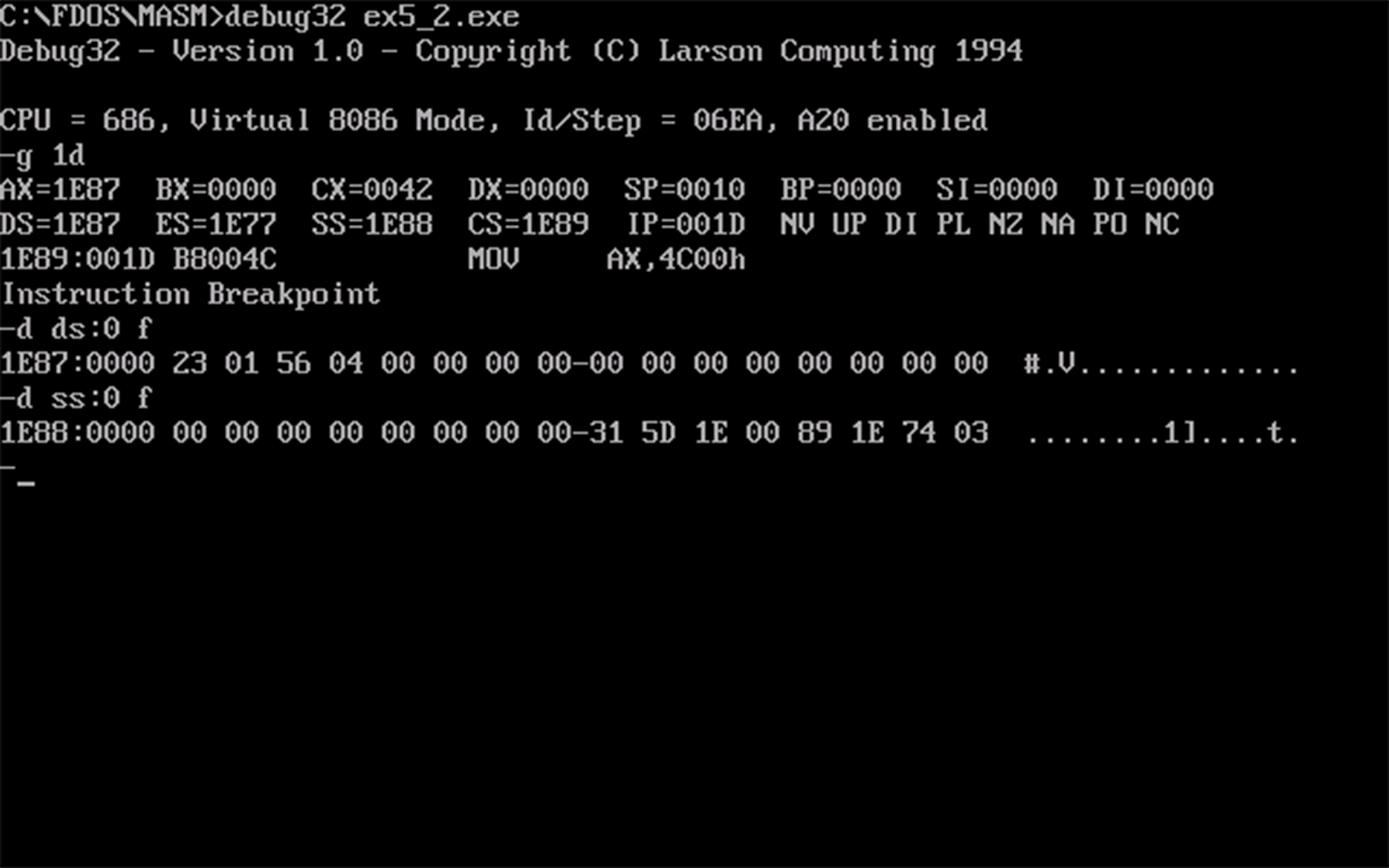
- 使用
d命令查看数据段的值,如下图所示:
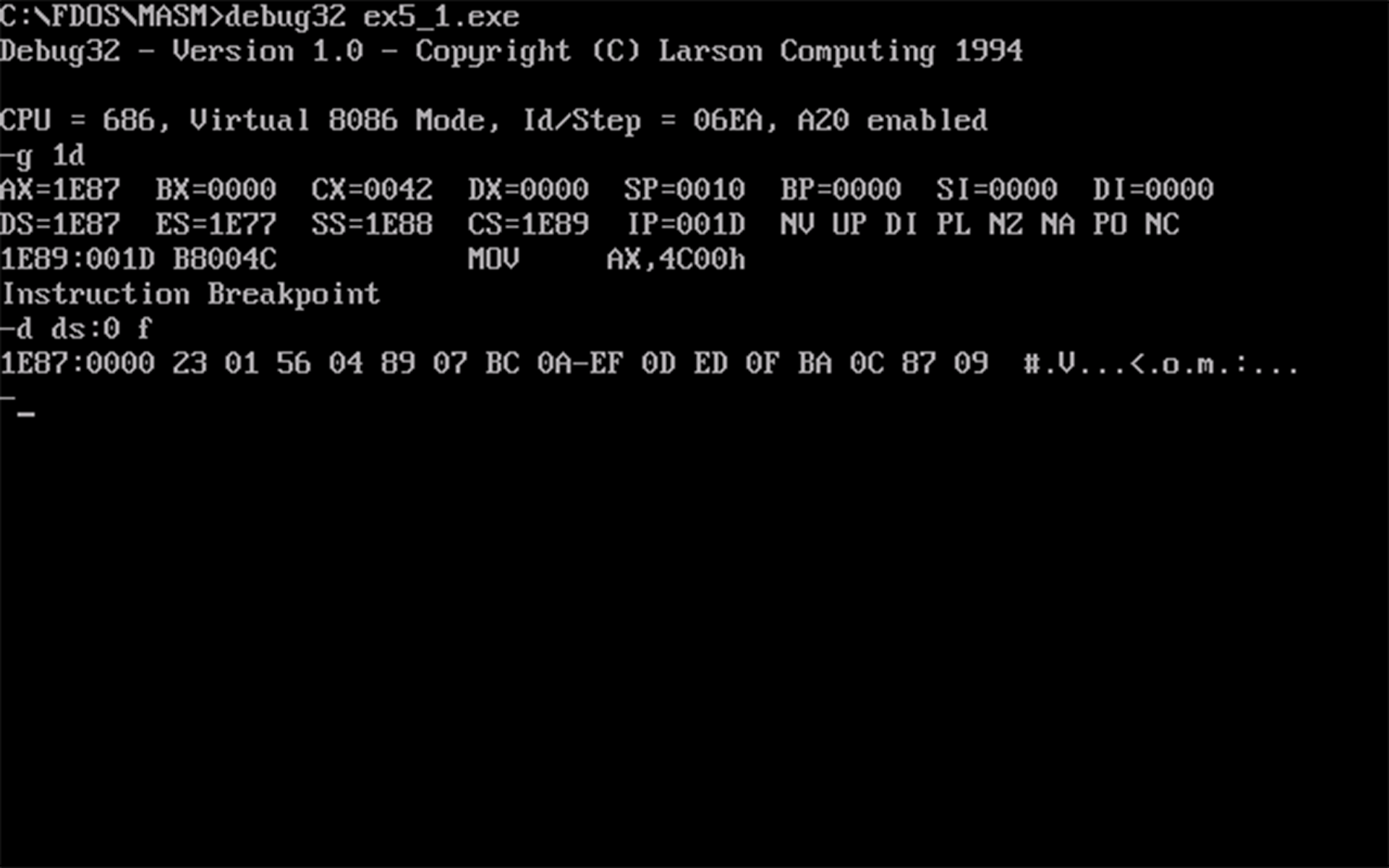
数据段的值是和运行前一样的,该程序并没有数据段的值。
程序返回前
cs、ss和ds的值如下图所示:
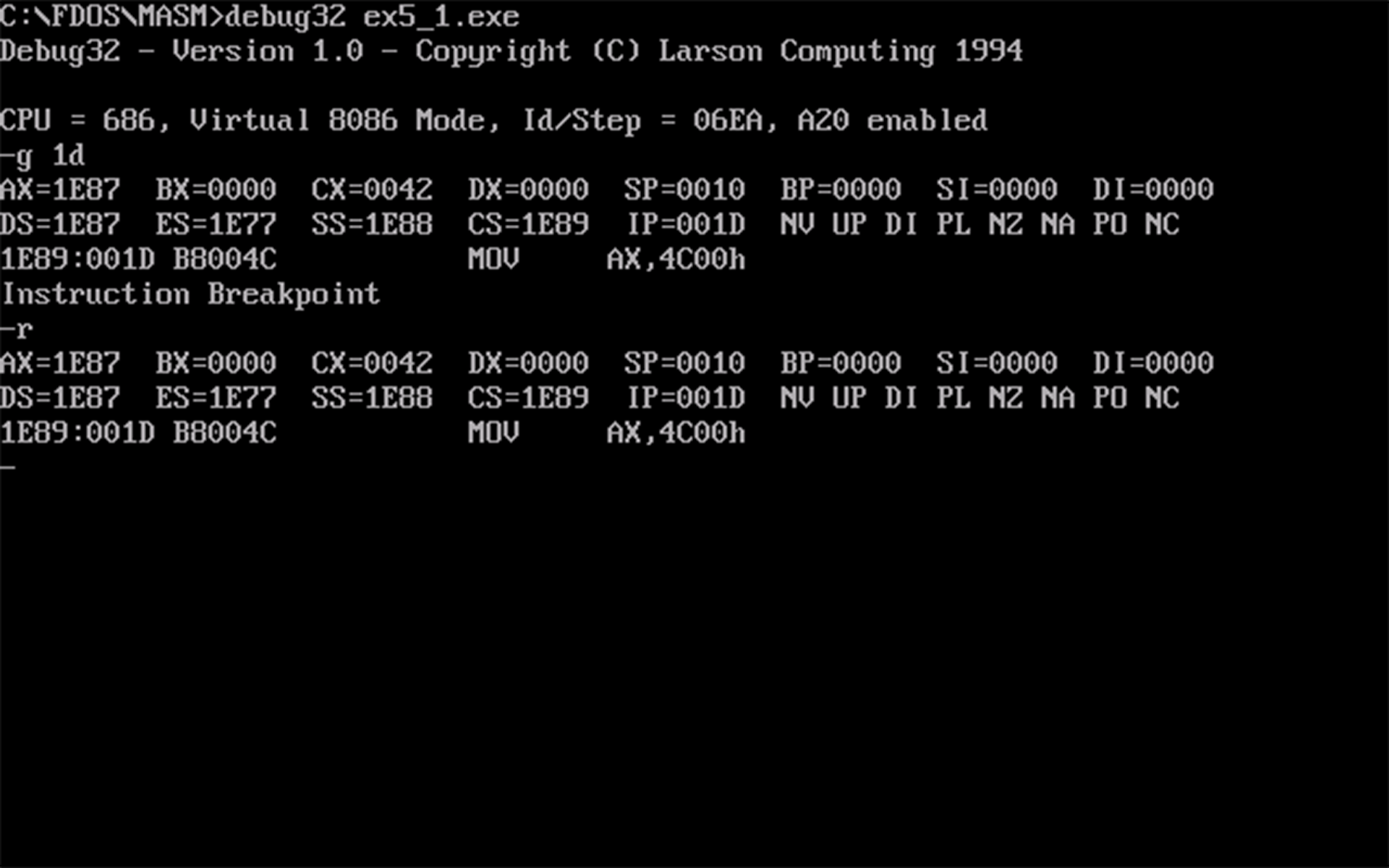
- 由以上实验推断,程序加载后,设代码段的段地址为 \(x\),则数据段的段地址为 \(x-2\),栈段的段地址为 \(x-1\)。
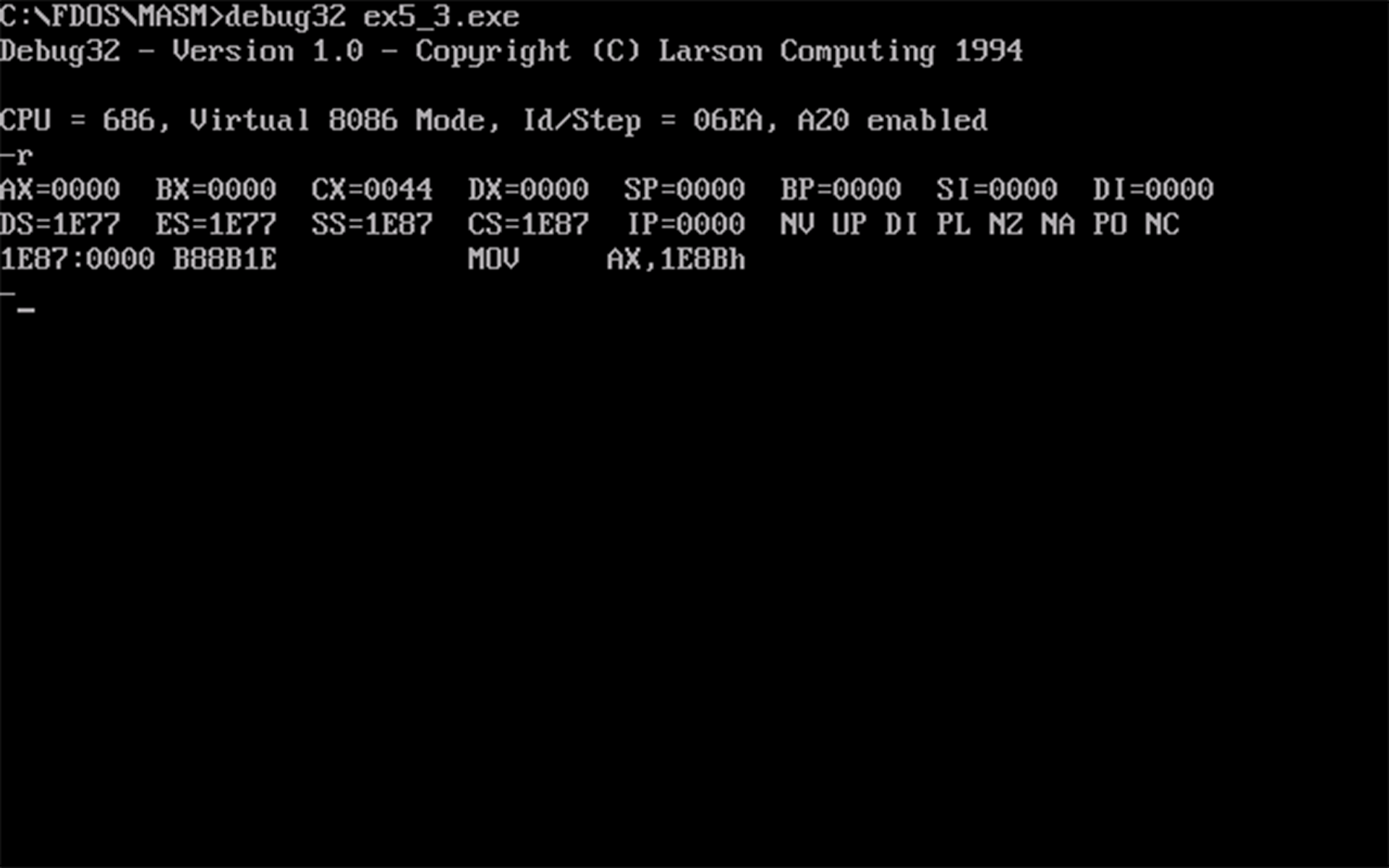
- 由
将下面的程序编译、连接,用
debug加载、跟踪。assume cs:code, ds:data, ss:stack data segment dw 0123h, 0456h data ends stack segment dw 0, 0 stack ends code segment start: mov ax,stack mov ss, ax mov sp,16 mov ax, data mov ds, ax push ds:[0] push ds:[2] pop ds:[2] pop ds:[0] mov ax,4c00h int 21h code ends end start编译和连接的步骤略。
- 按照上一个实验的经验,这次数据段和栈段应该占用
8个字节,但事实并没有这么简单。查看cx的值可见和先前的实验是一样的,都是32H。如下图所示:
- 由于代码段的大小不会发生改变,可以推测数据段和栈段分别占
10H个字节,且10H个字节是系统为数据段和栈段分配的单位最小空间。 - 现在用
debug查看数据段和栈段中的数据,如下图所示 (反汇编步骤略):
- 使用
g命令执行到返回指令之前,如下图所示:
- 数据段和预期的那样,没有发生改变。但栈段的未使用部分发生了改变,依据
ss:a到ss:d的数据推测,这里存储了cs:ip的历史值 (cs:(ip - 1))。 - 程序返回前
cs、ss和ds的值和上一个实验一样,cs、ss和ds的关系也一样,截图略。 - 如果
10H个字节是系统为数据段和栈段分配的单位最小空间,设段中的数据占 \(N\) 个字节,则程序加载后,该段实际占有空间为 $ \lfloor \dfrac{N+15} {16} \rfloor$。
- 按照上一个实验的经验,这次数据段和栈段应该占用
将下面的程序编译、连接,用
debug加载、跟踪。assume cs:code, ds:data, ss:stack code segment start: mov ax,stack mov ss, ax mov sp,16 mov ax, data mov ds, ax push ds:[0] push ds:[2] pop ds:[2] pop ds:[0] mov ax,4c00h int 21h code ends data segment dw 0123h, 0456h data ends stack segment dw 0,0 stack ends end start编译和连接的步骤略。
- 理论上程序大小应该和前两个一样,但查看
cx的值发现又不同了,如下图所示:
- 这里猜测系统通过某种方式为代码段分配了
10H的整数倍字节的空间,如下图所示:
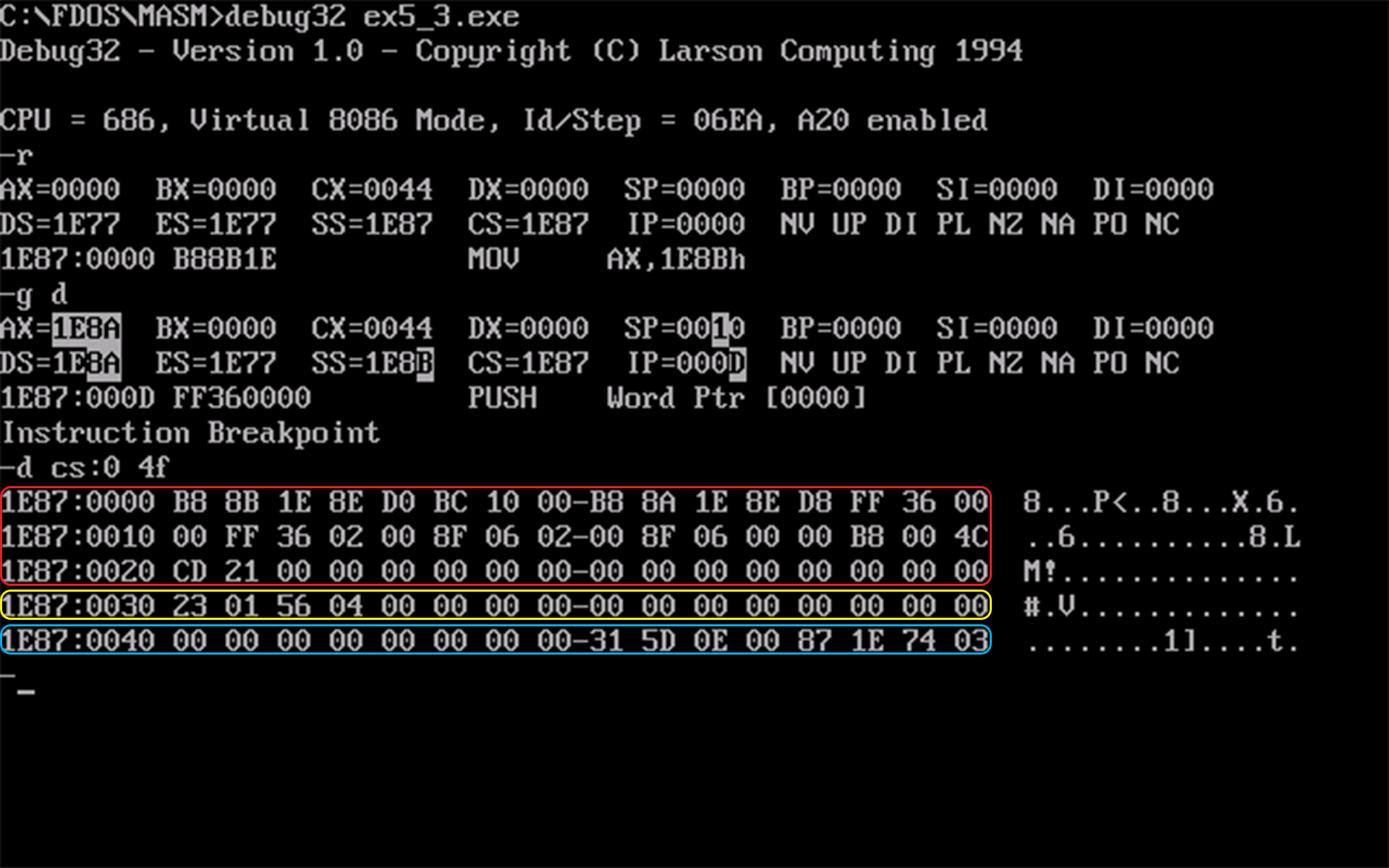
红框、黄框和蓝框分别对应代码段、数据段和栈段 - 可见代码段占用了
30H个字节,但是这与实际的大小矛盾,根据该程序比之前的大了2个字节,我的猜测是一个字节存放了补全的数 (这里是 0),另一个字节是补全的位数 (这里是 14)。至于为什么数据段和栈段没有使用这种补全机制,大概是因为其中的数据是多变的,直接将空间确定下来可以便于后期对数据的增减,以及减小因越界产生的安全隐患;还有一种可能只是与数据段和栈段保持统一。 - 数据段中的数据保持不变,截图略。
- 程序返回前
cs、ss和ds的值如下图所示:
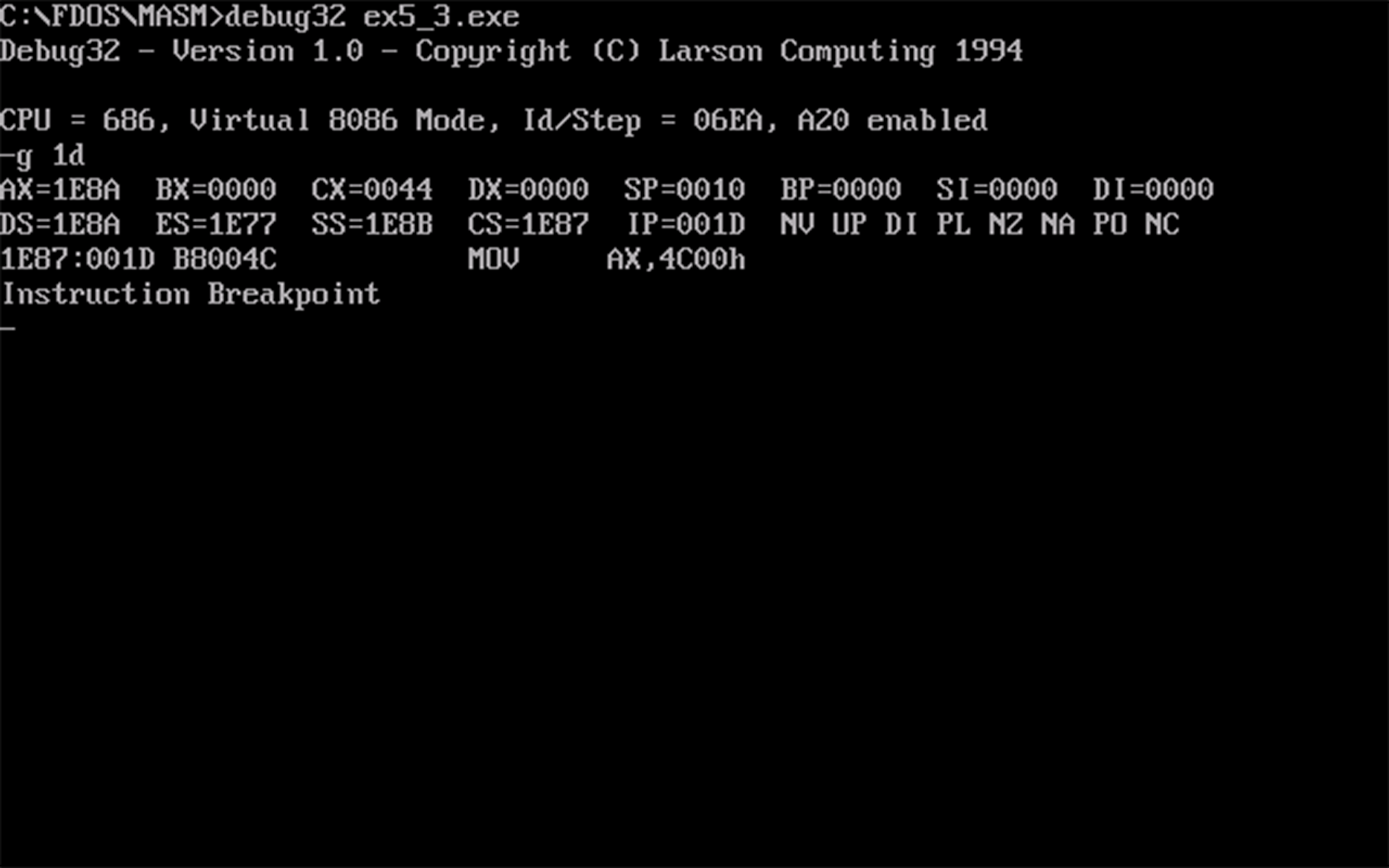
- 程序加载后,设代码段的段地址为 \(x\),则数据段的段地址为 \(x+3\),栈段的段地址为 \(x+4\)。
- 理论上程序大小应该和前两个一样,但查看
如果将 1. 、2. 、3. 题中的最后一条伪指令
end start改为end,3 个程序理论都能执行,但数据会被误认为机器码,可能因为非法语句导致系统报错。没有end start也就没有start使得程序从头执行,也就是说只有 3. 中的程序才能正确执行,因为代码段写在了前面。编写代码段中的代码,将
a段和b段中的数据依次相加,将结果存到c段中。- 以下为示例程序:
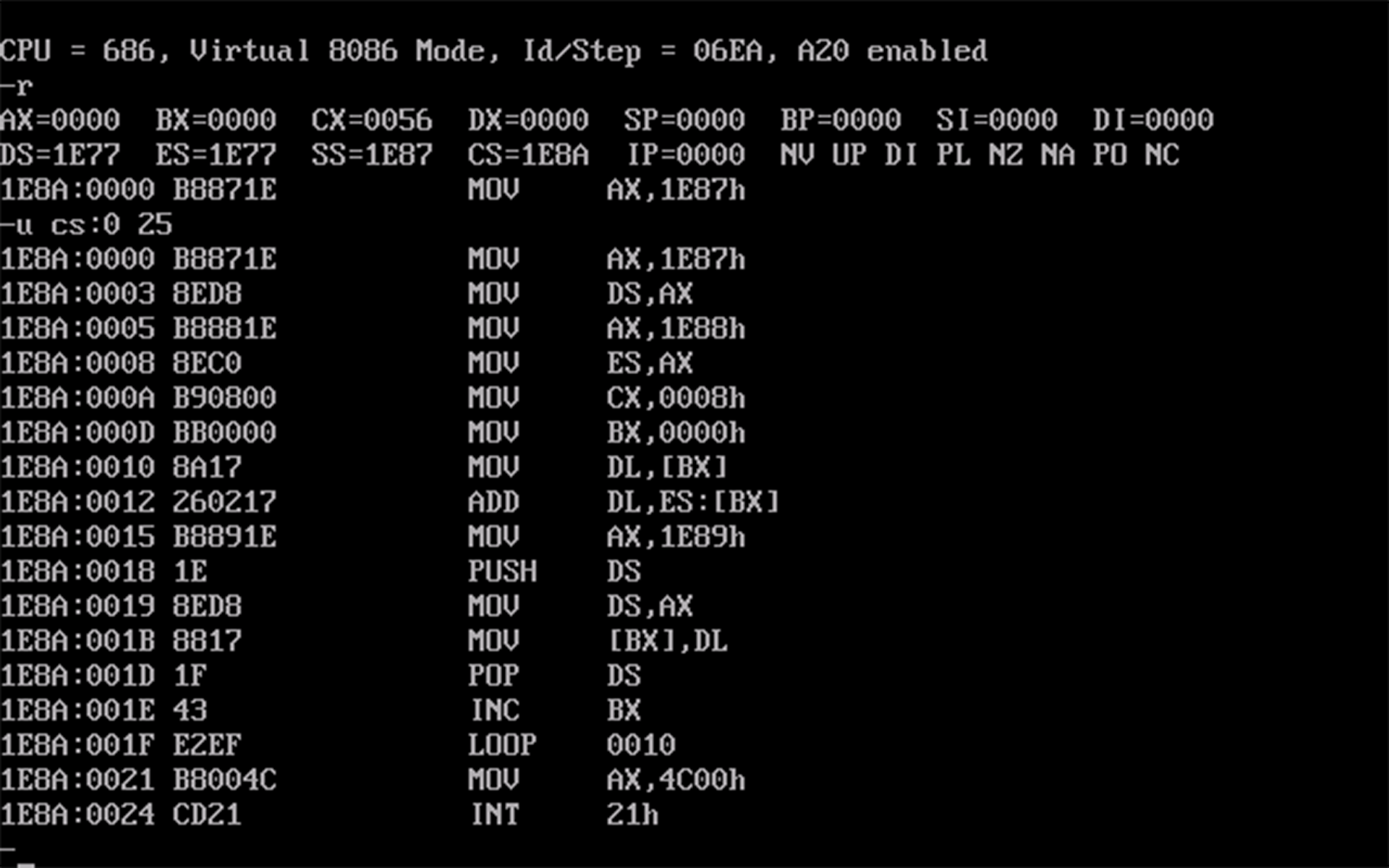
assume cs:code a segment db 1,2,3,4,5,6,7,8 a ends b segment db 1,2,3,4,5,6,7,8 b ends c segment db 8 dup(0) c ends code segment start: mov ax, a mov ds, ax mov ax, b mov es, ax mov cx, 8 mov bx, 0 s: mov dl, ds:[bx] ; ds 可以省略不写 add dl, es:[bx] mov ax, c push ds ; 使用栈的特性来 "保护现场" mov ds, ax mov [bx], dl pop ds inc bx loop s mov ax, 4c00h int 21h code ends end start- 查看
cx得程序所占空间,代码段的大小为56H - 3 * 10H =26H,反汇编得a、b和c的段地址,如下图所示:
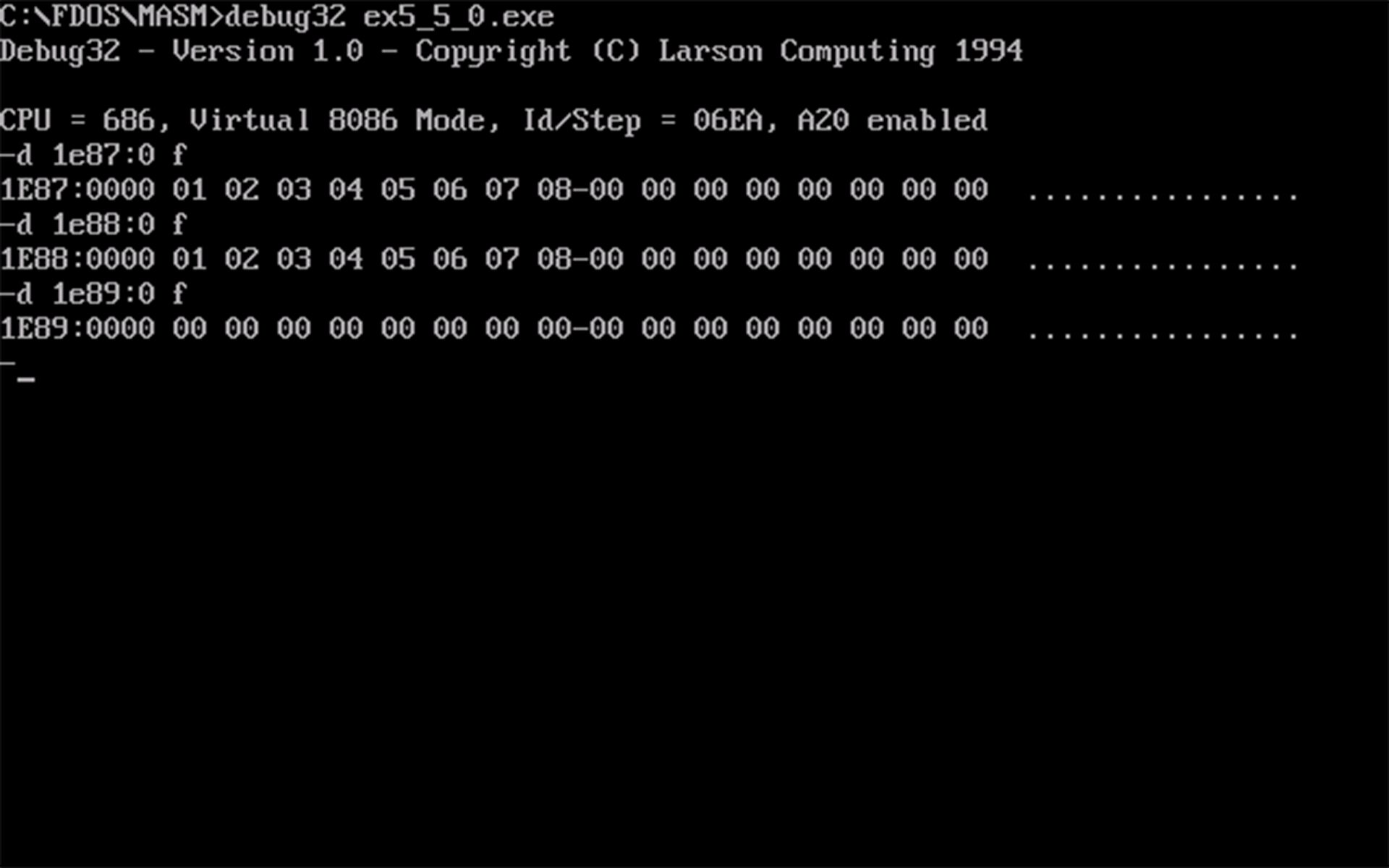
- 查看运行前
a段、b段和c段的数据,如下图所示:
- 返回前的数据如下图所示:
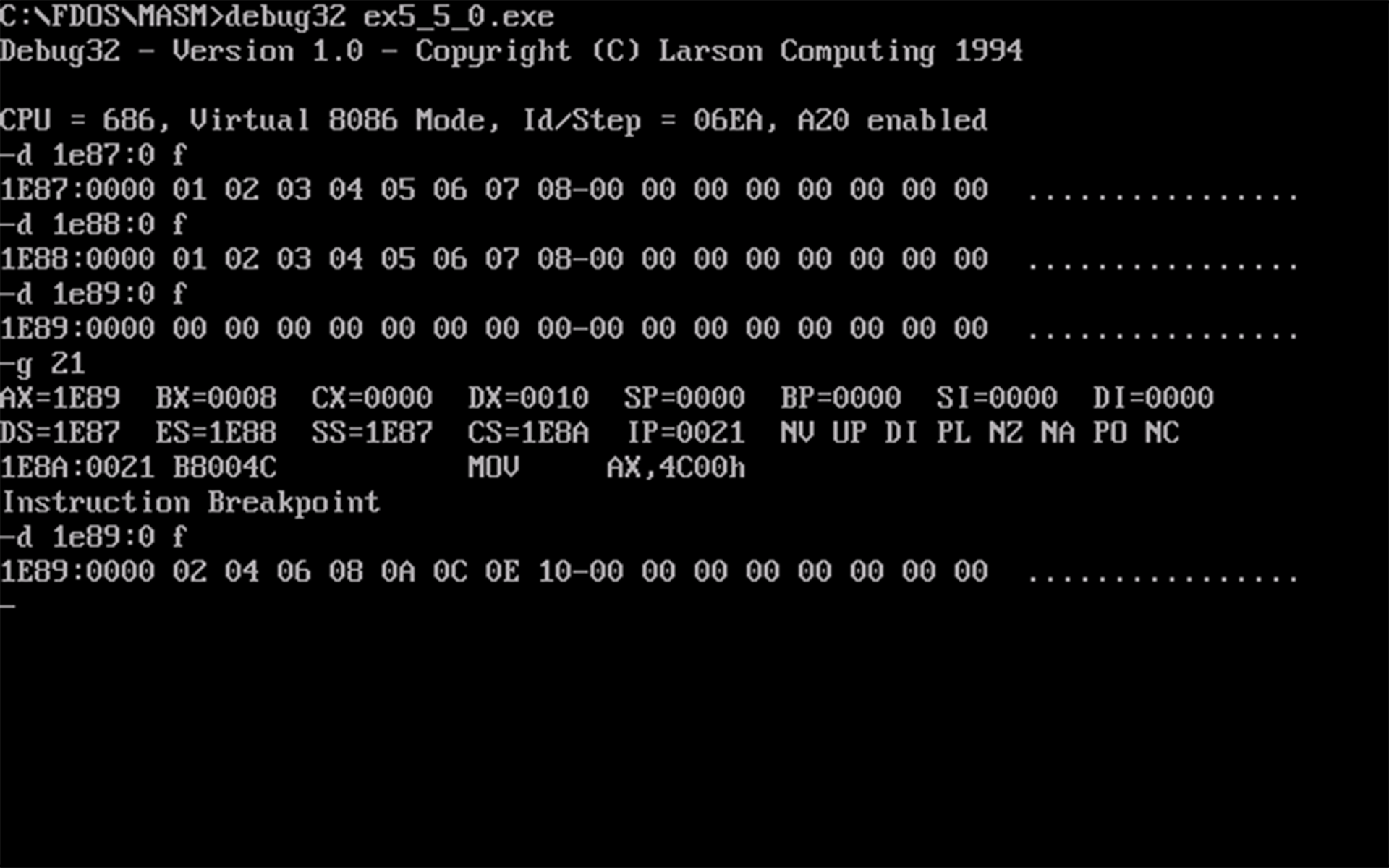
编写代码段中的代码,用
push指令将a段中的前 8 个字型数据,逆序存储到b段中。assume cs:code a segment dw 1, 2, 3, 4, 5, 6, 7, 8, 9, 0ah, 0bh, 0ch, 0dh, 0eh, 0fh, 0ffh a ends b segment dw 8 dup(0) b ends code segment start: mov ax, a mov ds, ax mov ax, b mov ss, ax ; 利用栈先入后出的特性逆序存放到 b mov sp, 16 mov bx, 0 mov cx, 8 s: push ds:[bx] add bx, 2 loop s mov ax, 4c00h int 21h code ends end start- 查看
cx得程序所占空间,代码段的大小为4FH - 20H - 10H =16H,反汇编得a和b的段地址,如下图所示:
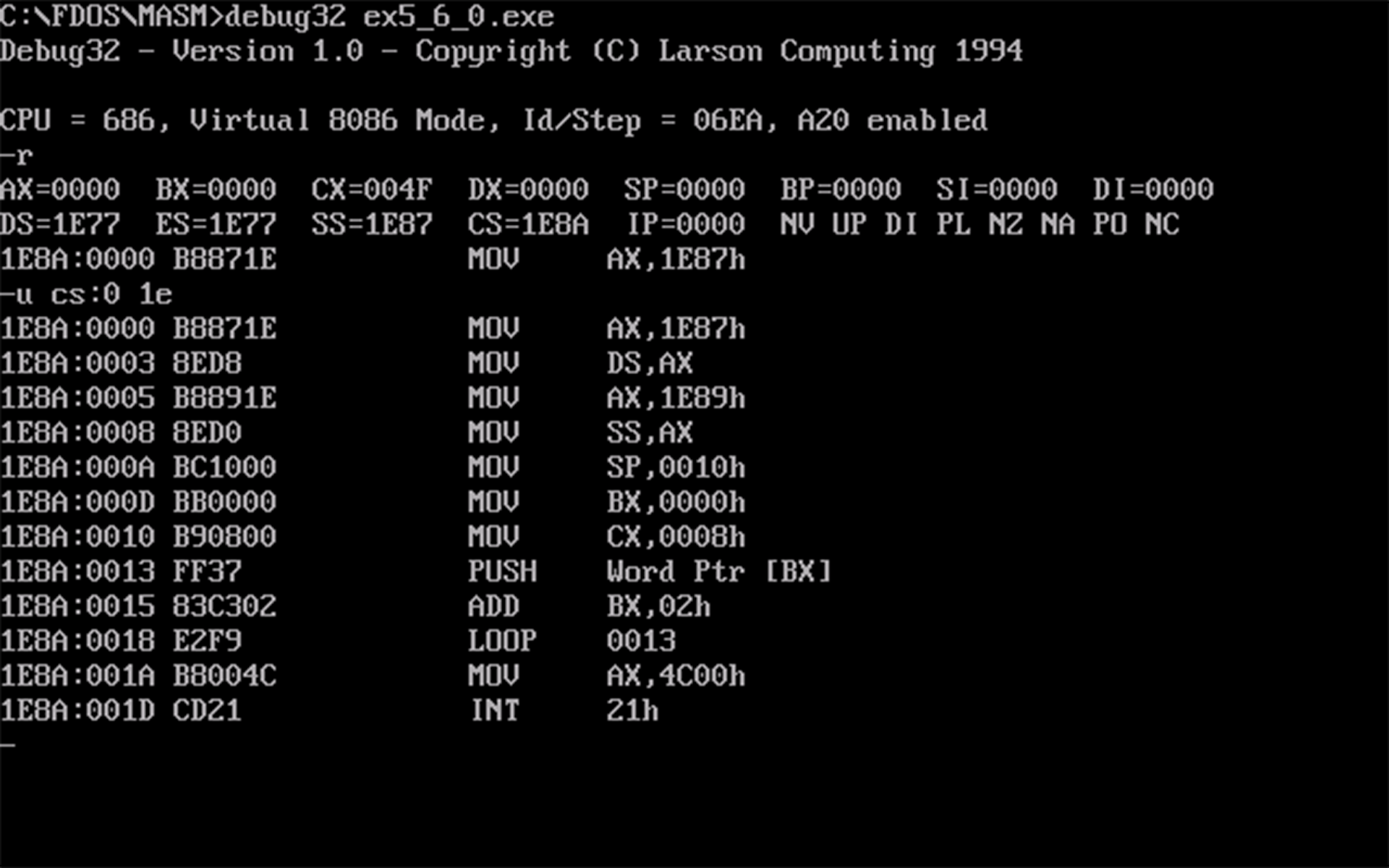
- 运行前和返回前的数据如下图所示:
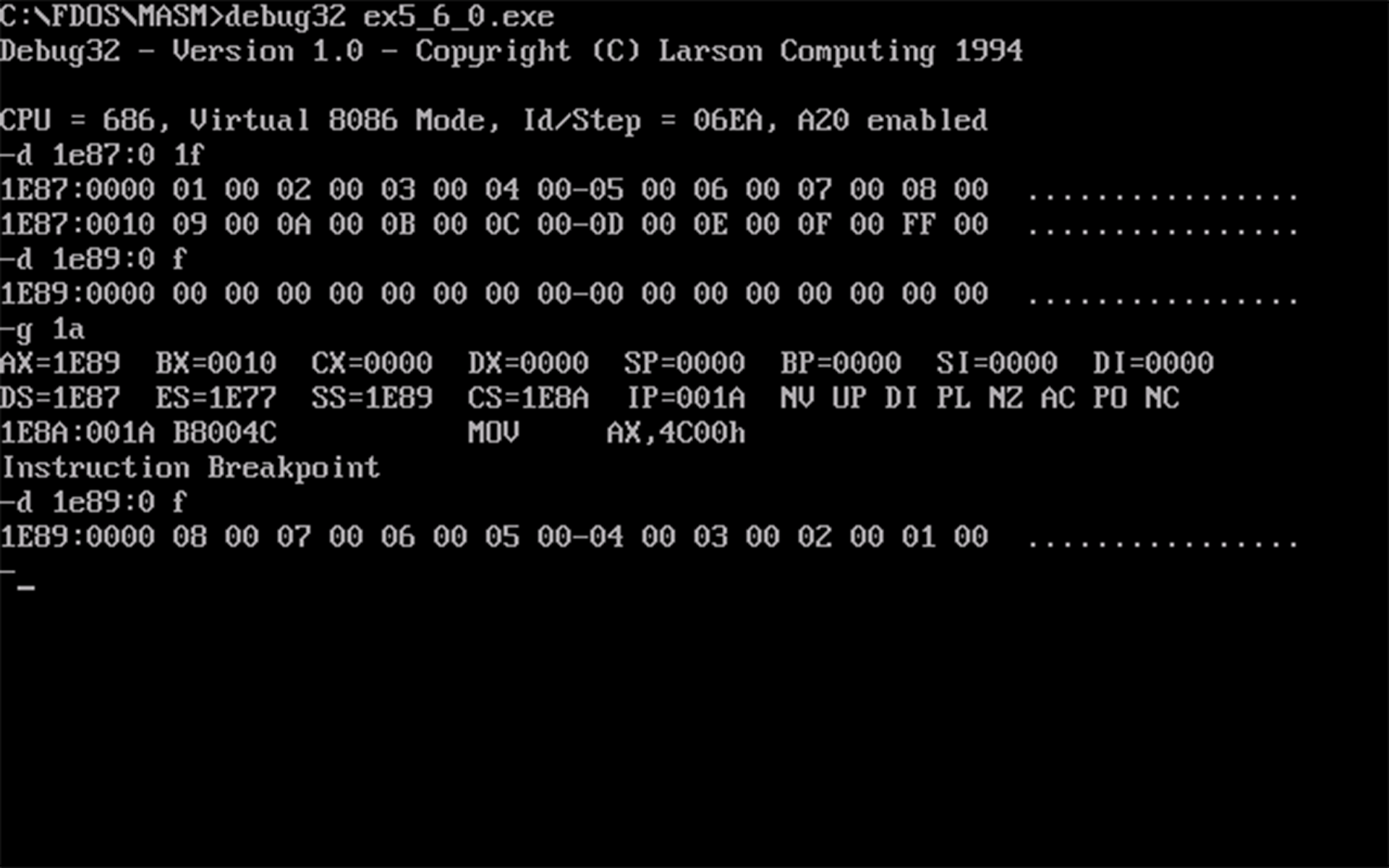
- 查看