1. 在 Transformer 之前生成文本
重要的是要注意,生成算法并不是新的。先前的语言模型使用了一个叫做循环神经网络或RNN的架构。尽管RNN在其时代很强大,但由于需要大量的计算和内存来很好
地执行生成任务,所以它们的能力受到了限制。让我们看一个RNN执行简单的下一个词预测生成任务的例子。
模型只看到了一个之前的词,预测不可能很好。当您扩展RNN实现以能够看到文本中的更多前面的词时,您必须大幅度地扩展模型使用的资源。至于预测,嗯,模型在这里失败了。

即使您扩展了模型,它仍然没有看到足够的输入来做出好的预测。为了成功预测下一个词,模型需要看到的不仅仅是前几个词。模型需要理解整个句子甚至整个文档。这里的问题是语言是复杂的。
在许多语言中,一个词可以有多个含义。这些是同音词。在这种情况下,只有在句子的上下文中我们才能看到是什么类型的银行。

句子结构中的词可以是模糊的,或者我们可能称之为句法模糊性。以这句话为例:“老师用书教学生。”老师是用书教学还是学生有书,还是两者都有?如果有时我们自己都不能理解人类语言,算法如何能理解呢?

好吧,在2017年,Google和多伦多大学发布了这篇论文《Attention is All You Need》后,一切都改变了。变压器架构已经到来。
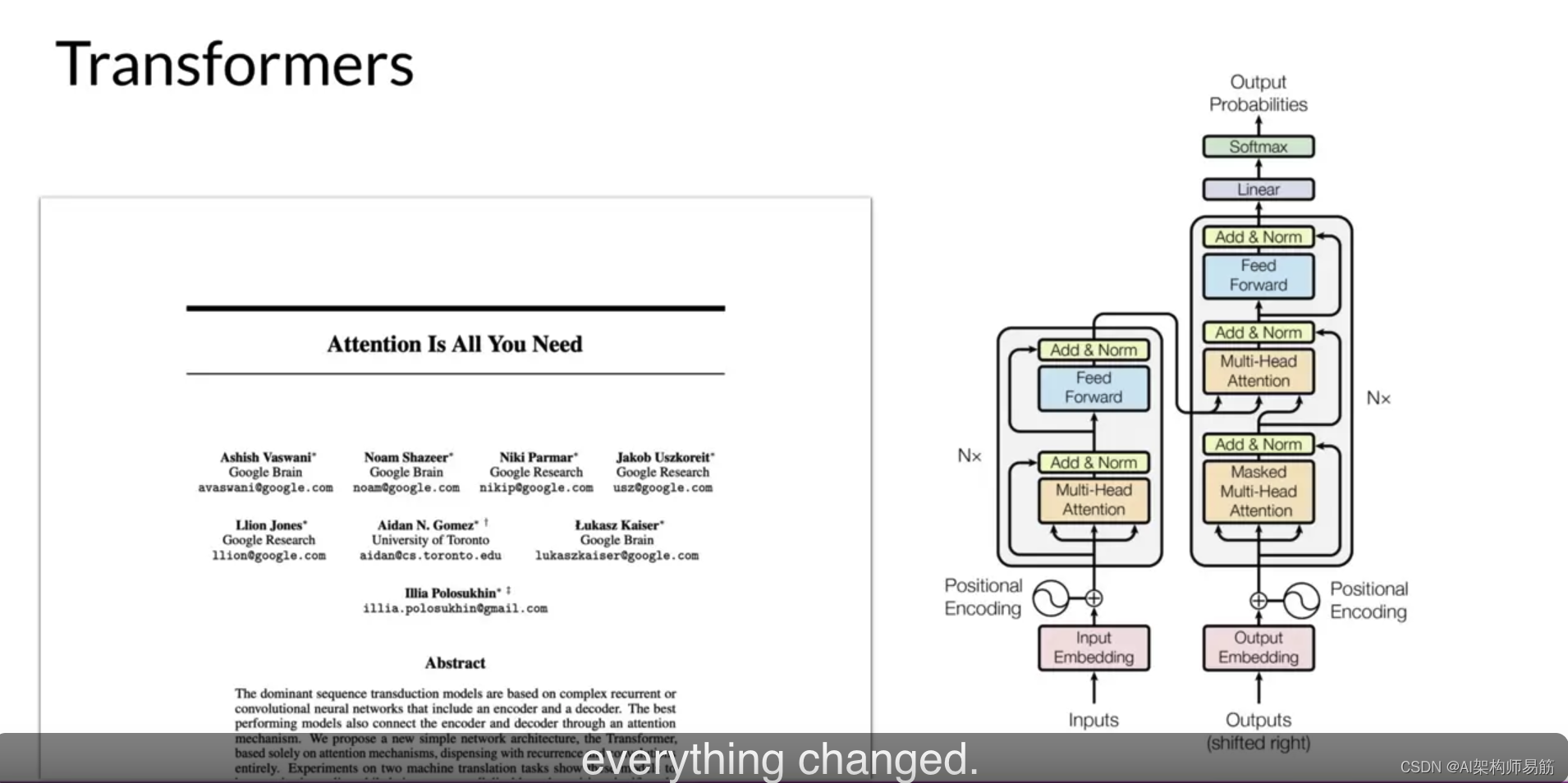
这种新颖的方法解锁了我们今天看到的生成AI的进步。它可以有效地扩展到使用多核GPU,它可以并行处理输入数据,使用更大的训练数据集,并且关键是,它能够学会关注它正在处理的词的含义。而Attention is All You Need。这就是标题。

参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/vSAdg/text-generation-before-transformers