最近由于要做SGG方向,恰巧之前保存过这篇论文
2107.12309.pdf (arxiv.org)![]() https://arxiv.org/pdf/2107.12309.pdf
https://arxiv.org/pdf/2107.12309.pdf
说在前面
想进一步了解SGG任务的可以看下这篇综述,后续我也会进一步研究。
2104.01111.pdf (arxiv.org)![]() https://arxiv.org/pdf/2104.01111.pdf
https://arxiv.org/pdf/2104.01111.pdf
如图是其中给出的一个场景图例子:

场景图生成的方法基本分成五类:
- CRF-based
- TransE-based
- CNN-based
- RNN/LSTM-based
- Graph-based。(以后的侧重点)
场景图的应用包括:
- Visual-Textual Transformer
- Image-Text Retrieval
- Visual Question Answering
- Image Understanding & Reasoning
- 3D Scene Understanding
- Human-Object / Human-Human Interaction。
场景生成的挑战在于一下几个方面:
- 场景图的长尾分布
- 距离远目标之间的Relationships检测
- 动态场景图的生成
- 基于场景图的Social relationship检测
- 关于visual reasoning的模型和方法
主要贡献
- 提出了用于动态场景图生成的时空转换器STTran,其编码器提取帧内的空间上下文,解码器捕获帧之间的时间依赖关系。
- 利用多标签损失引入一种新的生成场景图的策略:semi-constraint。
- 通过实验证明了STTran可以很好地利用时间上下文 (temporal context) 来改善关系检测。
研究背景
目前对场景理解 (scene understanding) 的研究正在从图像转移到更有挑战性的视频上。尽管已有不少工作针对action recognition和action localization,但目前对于逐帧的关系检测/场景图生成还属于空白。从视频生成动态场景图(Dynamic scene graph), 比从图像生成场景图更具挑战性,因为目标之间的动态关系和帧之间的时间依赖性需要更丰富的语义解释。如图显示了图像和视频生成scene graph的不同:
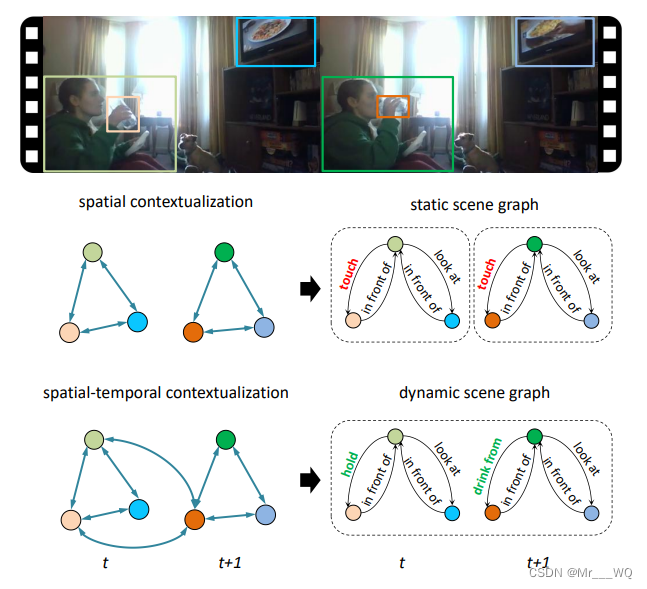
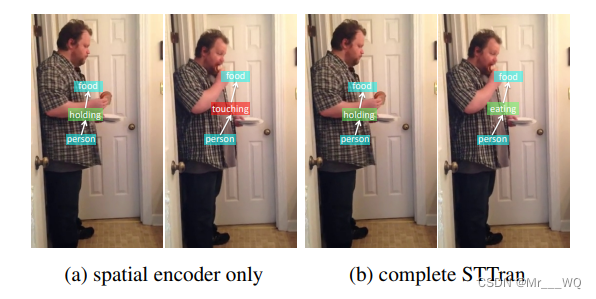
相比于基于图片的场景图生成,在生成给定视频的动态场景图时不仅可以利用单个帧的视觉,空间和语义信息,还可以利用时间上下文准确地推测出该帧中出现的关系。 例如下图中,尽管语义上person-touching-food并不能算错,但是结合前一帧的信息,person-eating-food才是更准确的动作关系。
Method
如图是STTran的架构示意图:
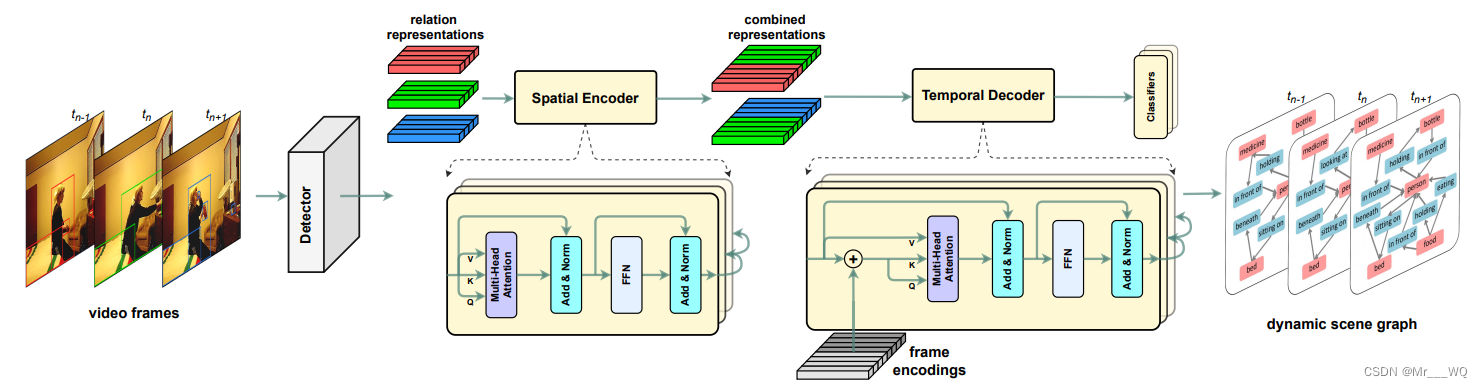
其中目标检测主干在 RGB 视频帧中提议目标区域,并对关系特征向量(relationship feature vectors)进行预处理。 时空变换器STTran的Encoder,先提取单帧的空间上下文。 由来自不同帧的编码器组所修正的关系表证(relation representations),组合在一起添加到学习的帧编码(frame encodings)中。 Decoder层捕获时间依赖性,并用线性分类器为不同关系类(例如注意力、空间、上下文)预测关系,图中FFN 表示前馈网络(feed-forward network)。
目标检测网络,作者用的是FasterRCNN,backbone使用了ResNet101
生成谓语表示:
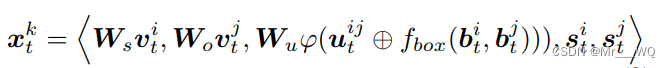
t:第t帧,k:第k个谓词
i,j:谓词关联到的两个物体,第i个和第j个
v:目标检测网络提取的视觉特征
uij:i,j两个物体的union box经过ROIAlign的特征
fbox:把物体i的bbox和物体j的bbox转换成特征,并且和uij维度相同
φ:展平
s:物体类别的语义嵌入信息
Spatial Encoder
- 关注于在一个帧中转换空间上下文,其输入为:
;
- 其第n层的输出为:
;
- 空间编码器由N个相同的
组成,并按顺序堆叠,第n层的输入为第n-1层的输出;
- 不同于一些主要的转换器方法,空间编码器没有将位置编码集成到输入中,因为帧内的关系在直观上是平行的;
- 在关系表示中隐藏的空间信息在自注意机制中起着至关重要的作用;
- 空间编码器堆栈的最终输出被送到Temporal Decoder中。
Temporal Decoder
不同于以往的单词位置和像素位置,我们将定制帧编码来将时间未知注入到关系表中。由于时域解码器中由窗口η \etaη决定的嵌入向量的数量是固定的,且相对较短,因此帧编码使用可学习的嵌入参数构造的。
,其中
是和
有相同长度的绝对向量。实验中还使用了正弦编码方法作为对比。
- 时域解码器主要用来捕捉帧之间的时间依赖;
- 其使用滑动窗口对帧进行批处理,使消息在相邻帧之间传递,避免与远帧的干扰;
去掉了带掩码的多头自注意层;
- 长度为η的滑动窗口在
中运行,其中第i个生成的输入为
,其中T是整个视频的长度;
- 解码器和编码器相同,由N个相同的自注意层堆叠;
- 其第一层为:
(增加了帧编码),
;
- 最后一个解码器的输出作为最终预测;
- 由于使用了滑动窗口,一个帧中的关系在不同批次的输入中由不同的表示,选择最早出现在窗口中的表现。
实验
关于时空变换器STTran训练的损失函数,它包括两个:基于可信度的multi-label margin loss和标准的cross entropy loss
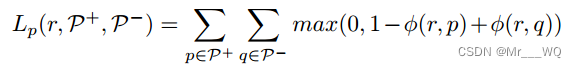
一般有两种典型的策略来生成具有推理关系分布的场景图:

这里提出一个半约束(Semi Constraint)策略。Semi Constraint 允许主-宾对(subject-object pair)有多个谓词 。这里谓词只有当对应关系可信度大于给定门限是才是正。
测试时主-谓-宾关系<subject-predicate-object>的得分为

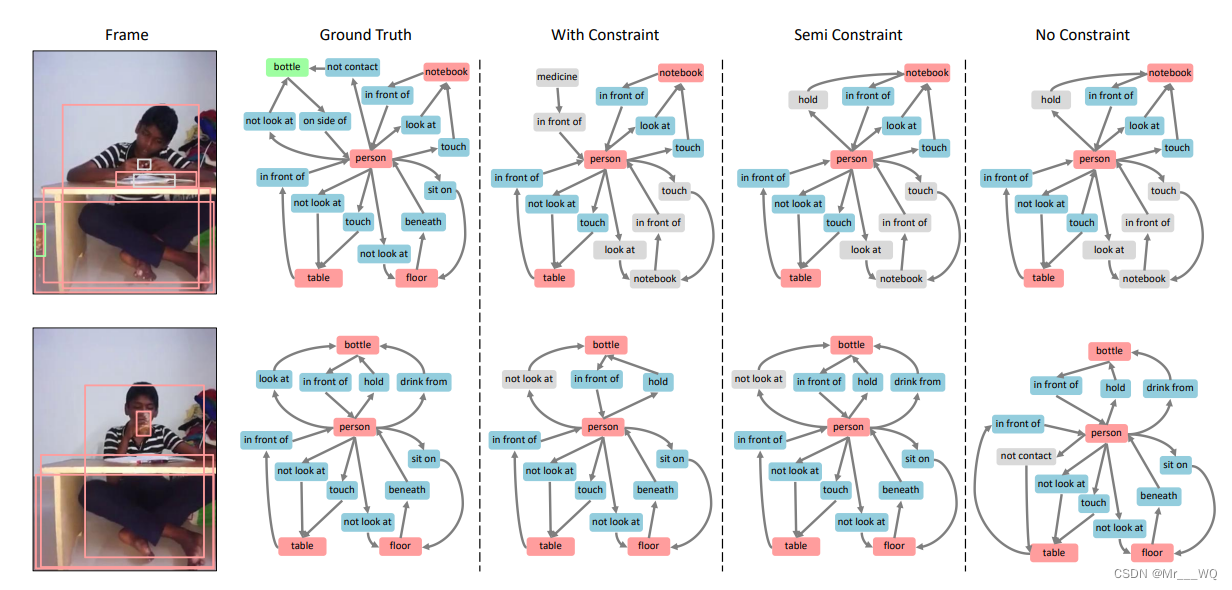
如图是各种策略的例子:
实验的Action Genome (AG) 数据集是斯坦福大学在 Charades 数据集(见ECCV'16论文“Hollywood in homes: Crowdsourcing data collection for activity understanding“)之上提供帧级场景图标签(详细看CVPR‘20论文“Action genome: Actions as compositions of spatio-temporal scene graphs“)。它包括35 个目标类(没有人) 476229 个边框和 25 个关系类的 1715568 个实例,一共标注 234253 帧。
这 25 种关系细分为三种不同的类型:(1)attention relationships表示一个人是否正在看一个目标,(2)spatial relationships,而(3)contact relationships,表示接触目标的不同方式。 在 AG 数据中,有135484 个主-宾对,标记为多种spatial relationships(例如<人-前面-门> 和<人-侧面-门>)或contact relationships(例如<人-吃-食物> 和 <人-拿-食物>)。
进行评估的3个测度来自图像域的场景图生成,用来测试视频域的动态场景生成方法:
- (1) predicate classification (PREDCLS)
- (2) scene graph classification (SGCLS)
- (3) Scene graph detection (SGDET)
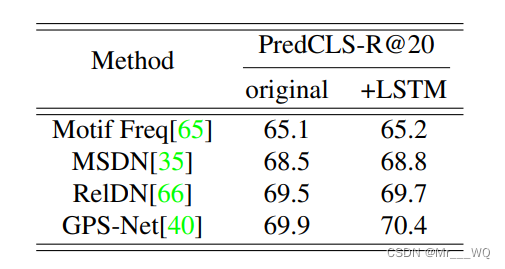
实验结果如下。其中比较的几个SOTA方法有:
- VRD:“Visual relationship detection with language priors”. ECCV2016
- MSDN:“Scene graph generation from objects, phrases and region captions”,ICCV2017
- Motif Freq:“Neural motifs: Scene graph parsing with global context”,CVPR2018.
- VCTREE:“Learning to compose dynamic tree structures for visual contexts“,CVPR2019
- RelDN:“Graphical contrastive losses for scene graph parsing”,CVPR2019
- Gps-net: Graph property sensing network for scene graph generation,CVPR2020


结论
- 该文提出了一种用于动态场景图生成的时空转换器(spatial - temporal Transformer, STTran),其编码器提取帧内的空间上下文,解码器捕获帧间的时间依赖关系。
- 与以往的单标签损失不同,该文利用多标签损失并引入一种新的生成场景图的策略。
- 多个实验表明,时间背景对关系预测有积极影响。
- 在Action Genome数据集上,动态场景图生成任务其获得了SOTA的结果。