随着神经网络层数的加深,优化函数越来越容易陷入局部最优解(即过拟合,在训练样本上有很好的拟合效果,但是在测试集上效果很差。为了解决深层神经网络的训练问题,一种有效的手段是采取无监督逐层训练(unsupervised layer-wise training),其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,这被称之为“预训练”(pre-training)
事实上,“预训练+微调”的训练方式可被视为是将大量参数分组,对每组先找到局部看起来较好的设置,然后再基于这些局部较优的结果联合起来进行全局寻优。这样就在利用了模型大量参数所提供的自由度的同时,有效地节省了训练开销。
另一种节省训练开销的做法是进行“权共享”(weightsharing),即让一组神经元使用相同的连接权,这个策略在卷积神经网络(Convolutional Neural Networks,简称CNN)中发挥了重要作用。下图为一个CNN网络示意图:

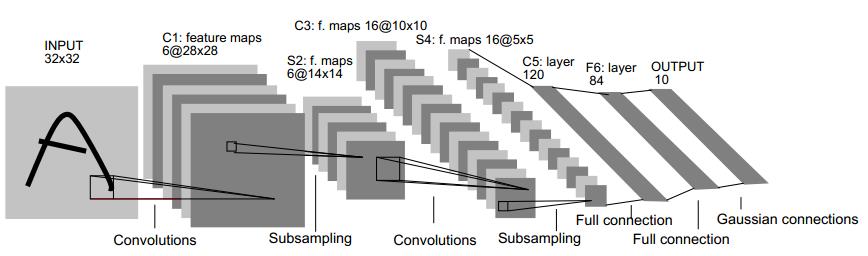
CNN可以用BP算法进行训练,但是在训练中,无论是卷积层还是采样层,其每组神经元(即上图中的每一个“平面”)都是用相同的连接权,从而大幅减少了需要训练的参数数目。