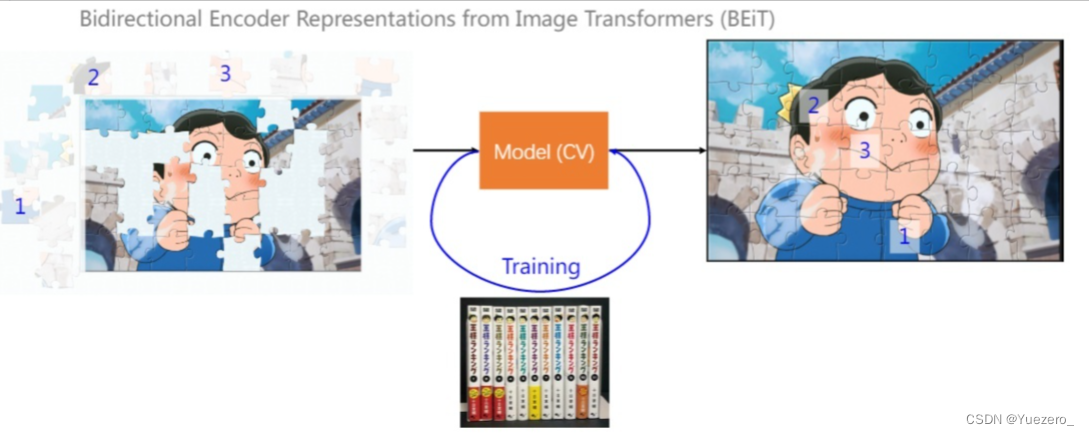
BEiT 是把 BERT 模型成功用在 image 领域的首创,也是一种自监督训练的形式,所以取名为视觉Transformer的BERT预训练模型。这个工作用一种巧妙的办法把 BERT 的训练思想成功用在了 image 任务中。
BERT:Bidiractional(双向) Encoder Representations from Transformers
SS L 自监督学习:机器学习分为有监督学习,无监督学习和强化学习,Self-Supervised Learning自监督学习,它可能不直接面对某一个具体的任务,Unsupervised Pre-train, Supervised Fine-tune.,但是它是通用的,需要接head来面对下游任务 (Downstream Tasks)。
1. BERT
BERT的目标有两个,一个是预测缺失的部分,另一个是预测上下文语义。
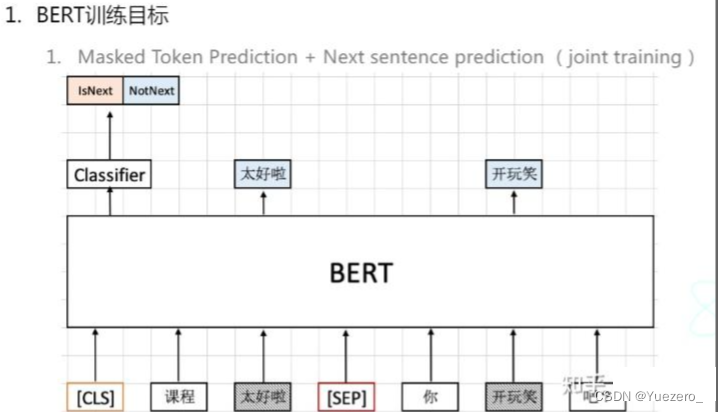
自监督学习:假装看不到输入的某一部分,然后学习怎么预测它。在这里面,假装的意思是用这一部分(抹掉的部分)拿来当作label用来监督模型。用图展示的话就是下面图中的示例,"很棒的"被抹去,希望BERT这个模型去学习,使得给出缺失部分的预测。看不到的部分可以不止一个。

2. BeiT (BERT->CV)
How to do SSL on image?
输入变为图像,一部分是看得见的,一部分是不可见的。