对onnx文件里的冗余节点“identity”进行修剪
在进行模型部署的过程中,我发现转换好的onnx模型含有大量的“identity”节点。实测过程中发现,这些节点不会影响onnx的推理结果,也不会影响onnx转换成的tensorrt推理引擎的推理结果,但是会严重影响onnx的推理速度。同时转换成的tensorrt文件也比正常的大很多,推理速度也会受到严重影响。
所以在此记录对“identity”节点的修剪过程和代码。
identity节点
目前我还没搞清楚为什么会出现大量“identity”节点,但是它貌似没有影响我最终的结果,只是影响了速度。我的onnx可视化效果长这样:
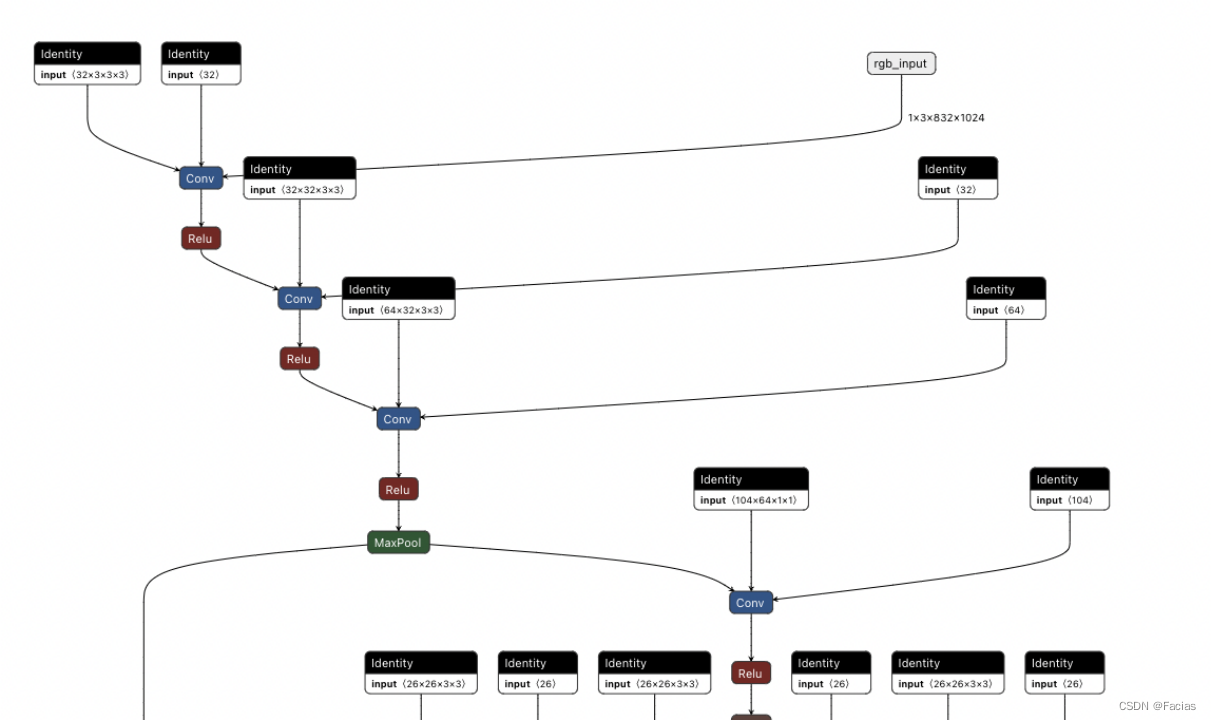
剪完之后长这样:
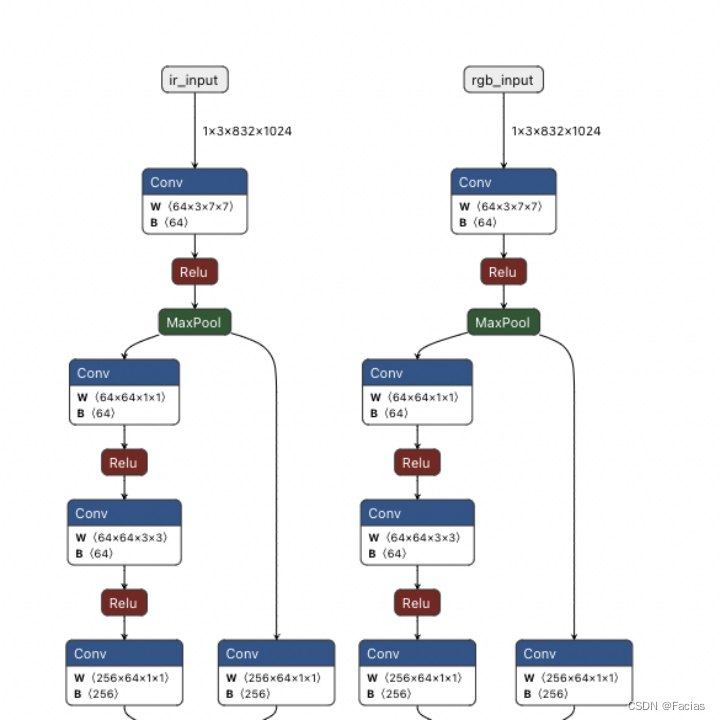
剪完之后再转换tensorrt文件,文件大小要比之前小很多,速度也变快了
修剪代码
我使用的onnx-simplifier进行修剪的,先安装:
pip install onnx-simplifier
然后就可以直接用了:
import onnx
import onnxoptimizer
#加载修剪之前的模型
onnx_model = onnx.load(r"mmdeploy/s2anet2onnx2/resnet50+cat+fam+deform-1024-prune.onnx")
#去掉identity层
all_passes = onnxoptimizer.get_available_passes()
print("Available optimization passes:")
for p in all_passes:
print('\t{}'.format(p))
print()
#保存修剪后的模型
onnx_optimized = 'mmdeploy/s2anet2onnx2/resnet50+cat+fam+deform-1024-prune.onnx'
passes = ['eliminate_identity']
optimized_model = onnxoptimizer.optimize(onnx_model, passes)
onnx.save(optimized_model, onnx_optimized)