MapTask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度那么,mapTask并行实例是否越多
越好呢?其并行度又是如何决定呢?Mapper数量由输入文件的数目、大小及配置参数决定;
MapReduce将作业的整个运行过程分为两个阶段:Map阶段Reduce阶段。
Map阶段由一定数量的Map Task实例组成,例如:
- 输入数据格式解析:InputFormat
- 输入数据处理:Mapper
- 本地规约:Combiner(相当于local reducer,可选)
- 数据分组:Partitioner
Reduce阶段由一定数量的Reduce Task实例组成,例如:
- 数据远程拷贝
- 数据按照key排序
- 数据处理:Reducer
- 数据输出格式:OutputFormat
1.MapReduce的Map阶段:
1.1.从HDFS读取数据:
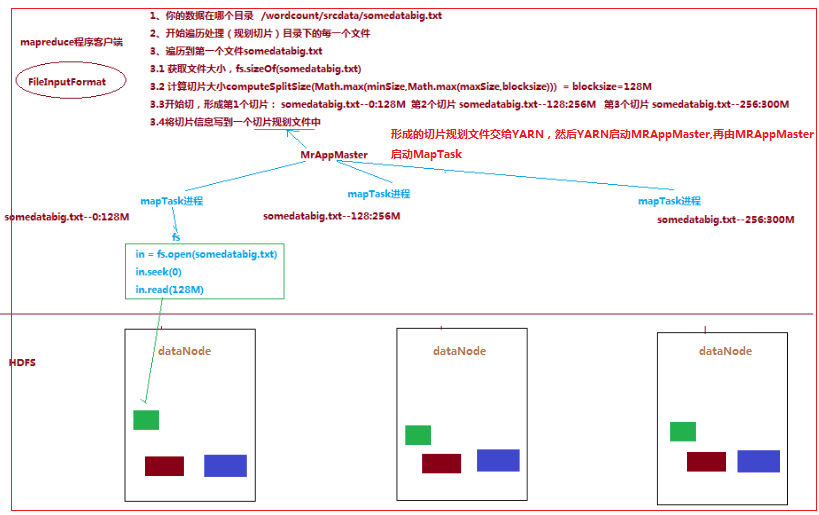
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据
划分成逻辑上的多个split),然后每一个split分配一个MapTask并行实例处理,即就是到底启动多少个MapTask实例就意味着将
数据切成多少份(一个切片对应一个MapTask实例)
切片逻辑及形成的切片规划描述文件,由 FileInputFormat 实现类的getSplits()方法完成:流程如下: