
目录
一.引言
Baichuan-13B 具有良好的中文语料输出功能,在部署 Baichuan-13B 模型时,博主尝试不同张数的显卡部署模型推理服务,下面看看不同卡以及是否量化模型在内存和推理时间上有何区别。
二.模型加载
1.量化加载
◆ 基础配置
config_kwargs = {
"trust_remote_code": True,
"cache_dir": None,
"revision": 'main',
"use_auth_token": None,
}◆ 8_bit 加载
config_kwargs["load_in_8bit"] = True
config_kwargs["quantization_config"] = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0
)◆ 4_bit 加载
config_kwargs["load_in_4bit"] = True
config_kwargs["quantization_config"] = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)Tips:
这里实际测试情况下,Baichuan-13B 量化前后显存消耗一致,即量化未生效,可以试试调整 llm_int8_threshold 的阈值再尝试一下。
2.多卡加载
◆ API 加载
bc_model = AutoModelForCausalLM.from_pretrained(
ori_model_path,
config=config,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=True,
revision='main',
device_map='auto'
)添加 device_map='auto' 参数,如果还不生效可以尝试在脚本中添加:
export CUDA_VISIBLE_DEVICES=0,1根据实际卡的情况,修改对应的 device_id 即可。
◆ accelerate 加载
if torch.cuda.device_count() > 1:
from accelerate import dispatch_model
from accelerate.utils import infer_auto_device_map, get_balanced_memory
device_map = infer_auto_device_map(bc_model, max_memory=get_balanced_memory(bc_model))
bc_model = dispatch_model(bc_model, device_map)
print('multi GPU predict => {}'.format(device_map))
else:
bc_model = bc_model.cuda()
print("single GPU predict")通过 infer_auto_device_map 获取不同 layer 对应的 device,这里 accelerate 版本为 0.21.0。
三.模型推理
这里采用 P40-24G 作为基础显卡,常规 Baichuan-13B 加载需要 28G 显存,下面使用双卡 P40 和三卡 P40 尝试推理。
1.显存查看
为了观察推理时多卡的显存占用情况,我们使用 shell 命令和 python 命令对显存进行监控。
◆ Nvidia 显卡监控
在 shell 命令行输入下述命令,每 3 s 调用一次 nvidia-smi 查看一次显卡使用情况
watch -n 3 nvidia-smi◆ Python subprocess 调用
import subprocess
def get_gpu_memory_usage(info):
# 使用nvidia-smi命令获取显卡信息
cmd = "nvidia-smi --query-gpu=memory.used --format=csv,nounits,noheader"
result = subprocess.run(cmd, stdout=subprocess.PIPE, shell=True, encoding='utf-8')
memory_used = result.stdout.strip().split('\n')
print("[%s Memory Usage: %s]" %(info, ','.join(memory_used)))使用 python subprocess 调用 nvidia-smi cmd 命令,最后得到的 memory_used 为每张卡的显存使用情况,我们只需要在需要监控显卡显存的位置调用该函数即可,info 为对应的日志节点,例如加载模型前后,推理任务前后。
2.双卡推理
◆ 双卡 divice 分配
{'model.embed_tokens': 0, 'model.layers.0': 0, 'model.layers.1': 0, 'model.layers.2': 0, 'model.layers.3': 0,
'model.layers.4': 0, 'model.layers.5': 0, 'model.layers.6': 0, 'model.layers.7': 0, 'model.layers.8': 0,
'model.layers.9': 0, 'model.layers.10': 0, 'model.layers.11': 0, 'model.layers.12': 0, 'model.layers.13': 0,
'model.layers.14': 0, 'model.layers.15': 0, 'model.layers.16': 0, 'model.layers.17': 0, 'model.layers.18': 0,
'model.layers.20': 1, 'model.layers.21': 1, 'model.layers.22': 1, 'model.layers.23': 1, 'model.layers.24': 1,
'model.layers.25': 1, 'model.layers.26': 1, 'model.layers.27': 1, 'model.layers.28': 1, 'model.layers.29': 1,
'model.layers.30': 1, 'model.layers.31': 1, 'model.layers.32': 1, 'model.layers.33': 1, 'model.layers.34': 1,
'model.layers.35': 1, 'model.layers.36': 1, 'model.layers.37': 1, 'model.layers.38': 1, 'model.layers.39': 1,
'model.norm': 1, 'lm_head': 1, 'model.layers.19': 1}0-19 的 model.layers 分在了 0 卡,20-39 的 model.layers 分在了 1 卡,查看显存日志:
[模型加载后 Memory Usage: 12232,13436]
[模型生成前 Memory Usage: 13746,13548]基本单卡的负载在 12G + 的情况。
◆ 双卡推理 GPU-Util
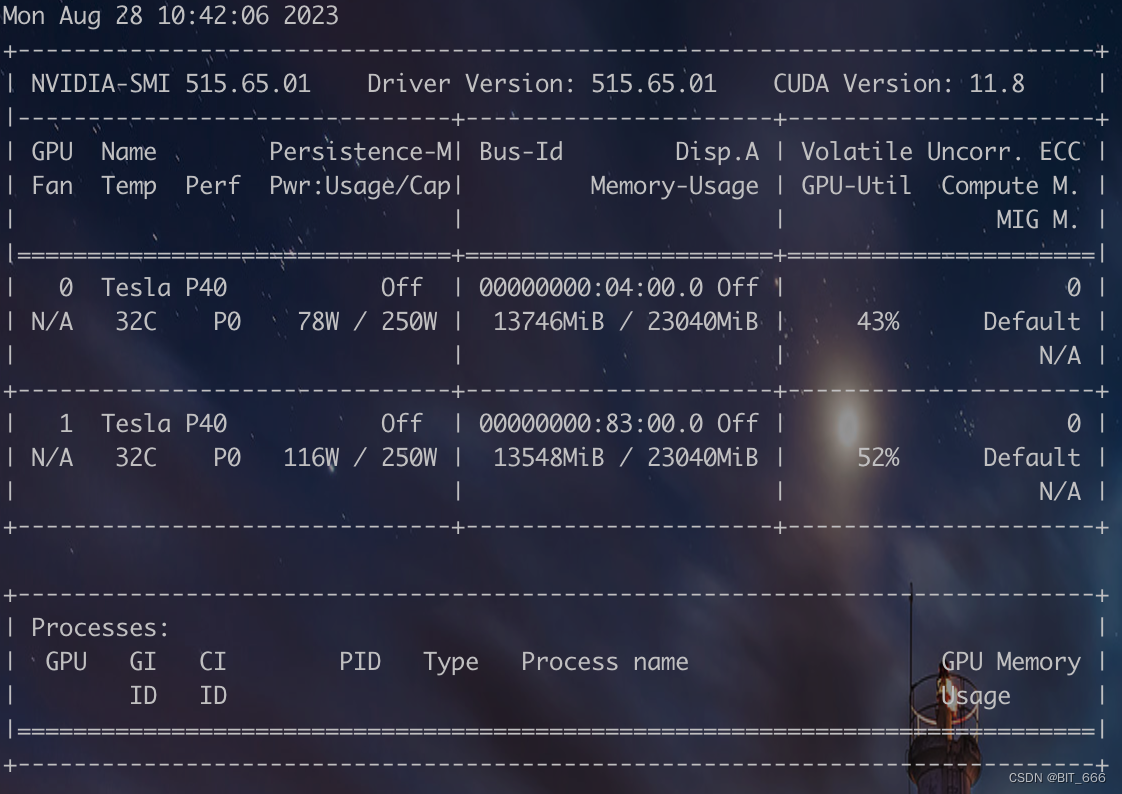
推理期间双卡的显存占用都在 13G,GPU-Util 均在 50% 左右,测试了两次耗时:
Cost: 804.4720668792725 Count: 54
Cost: 673.4583792686462 Count: 54平均生成一条样本耗时 13.67 s,两次耗时波动还是有点大,更精确的结果需要更多次试验且结合自己的输入输出的 token 数量。
3.三卡推理
◆ 三卡 divice 分配
{'model.embed_tokens': 0, 'model.layers.0': 0, 'model.layers.1': 0, 'model.layers.2': 0, 'model.layers.3': 0,
'model.layers.4': 0, 'model.layers.5': 0, 'model.layers.6': 0, 'model.layers.7': 0, 'model.layers.8': 0,
'model.layers.9': 0, 'model.layers.10': 0, 'model.layers.11': 0, 'model.layers.13': 1, 'model.layers.14': 1,
'model.layers.15': 1, 'model.layers.16': 1, 'model.layers.17': 1, 'model.layers.18': 1, 'model.layers.19': 1,
'model.layers.20': 1, 'model.layers.21': 1, 'model.layers.22': 1, 'model.layers.23': 1, 'model.layers.24': 1,
'model.layers.25': 1, 'model.layers.27': 2, 'model.layers.28': 2, 'model.layers.29': 2, 'model.layers.30': 2,
'model.layers.31': 2, 'model.layers.32': 2, 'model.layers.33': 2, 'model.layers.34': 2, 'model.layers.35': 2,
'model.layers.36': 2, 'model.layers.37': 2, 'model.layers.38': 2, 'model.layers.39': 2, 'model.norm': 2,
'lm_head': 2, 'model.layers.26': 2, 'model.layers.12': 1}0-11 的 model.layers 分配给 0 卡,12-25 卡1,26-39 分给卡2,除此卡 1 还加载了 embed_tokens ,卡 2 还加载了 lm_head,查看显存日志:
[模型加载后 Memory Usage: 8018,8596,9222]
[模型生成前 Memory Usage: 9510,8674,9300]基本单卡负载在 8-9 G。
◆ 三卡推理 GPU-Util
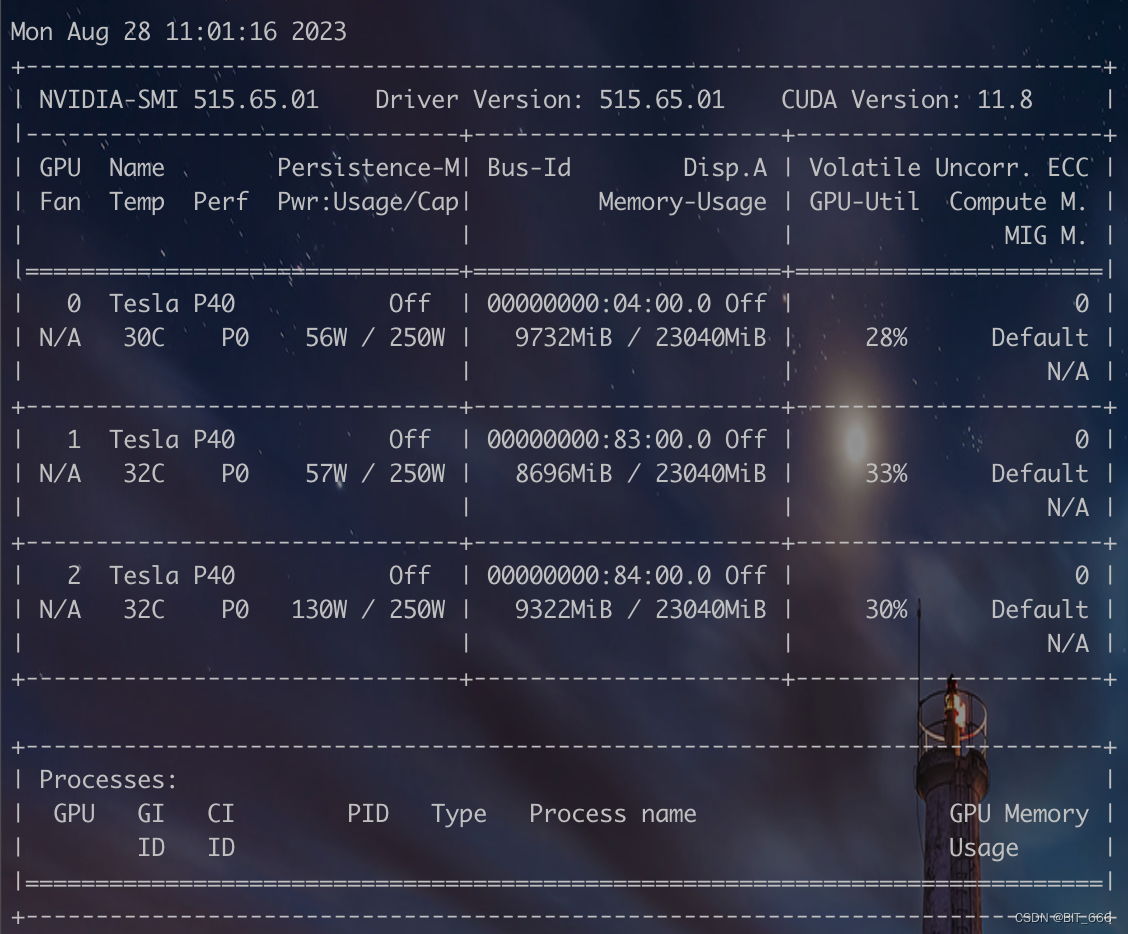
推理期间双卡的显存占用都在 9G 附近,GPU-Util 均在 30% 左右,同样测试两次耗时:
常规: Cost: 751.8843202590942 Count: 54
量化: Cost: 773.8875942230225 Count: 54平均生成一条样本耗时 14.11 s。
◆ 多卡推理效率差异
上面测试 3卡 推理 14.11s 每条,2卡 推理 13.67s 每条,多一张卡甚至比少一张卡还慢,下面看下可能导致多卡推理速度变慢的可能:
● 通信开销
在多卡GPU系统中,不可避免地需要进行数据传输和同步操作。当使用三张GPU时,需要更多的数据传输和同步操作,这会导致额外的通信开销,从而降低了推理的性能。
● 内存带宽限制
多卡GPU系统中,每张GPU上的内存是相互独立的,无法直接访问其他GPU上的数据。当进行推理时,如果模型和数据无法完全适应单个GPU的内存容量,就需要将数据分配到不同的GPU上进行计算。在三卡GPU系统中,由于每个GPU要处理的数据更多,可能会导致内存带宽成为瓶颈,从而影响了推理的速度。
● 算力利用率
在某些情况下,模型的规模可能无法充分利用多卡 GPU 系统的并行计算能力。例如,如果模型较小或者推理过程中存在大量串行计算的部分,那么多卡 GPU 系统的优势可能无法充分发挥。在这种情况下,使用三卡GPU可能会增加额外的开销,并不能带来明显的性能提升。
这里出现上述情况可能是 [通信开销] 和 [算力利用率] 导致。
四.总结
这里使用 Baichuan-13B 尝试了不同的量化策略和多卡推理,这里量化并未生效,博主采用 LLaMA-33B 尝试相同配置 8Bit 量化生效,模型可以从 65G 显存占用下降至 33G 附近,具体模型量化效果请参考根据模型与实际业务使用场景。除此之外,多卡推理目前看除了可以在显存实现均匀分配外,在效率上并未取得明显提升,有相关的经验的同学也可以评论区一起交流。