title: Learning Deep Features for Discriminative Localization
authors: Bolei Zhou et.al.
year: 2015-12-13
主要贡献
- 对深度学习实现可解释性分析、显著性分析
- 可扩展性强,后续衍生出各种基于CAM的算法
- 每张图片、每个类别,都能生成CAM热力图
- 弱监督定位︰仅仅使用图像分类的模型解决了定位问题
- 潜在的“注意力机制”
- 使得Machine Teaching成为可能
Abstract
In this work, we revisit the global average pooling layer proposed in [13], and shed light on how it explicitly enables the convolutional neural network to have remarkable localization ability despite being trained on image-level labels. While this technique was previously proposed as a means for regularizing training, we find that it actually builds a generic localizable deep representation that can be applied to a variety of tasks. Despite the apparent simplicity of global average pooling, we are able to achieve 37.1% top-5 error for object localization on ILSVRC 2014, which is remarkably close to the 34.2% top-5 error achieved by a fully supervised CNN approach. We demonstrate that our network is able to localize the discriminative image regions on a variety of tasks despite not being trained for them.
Method
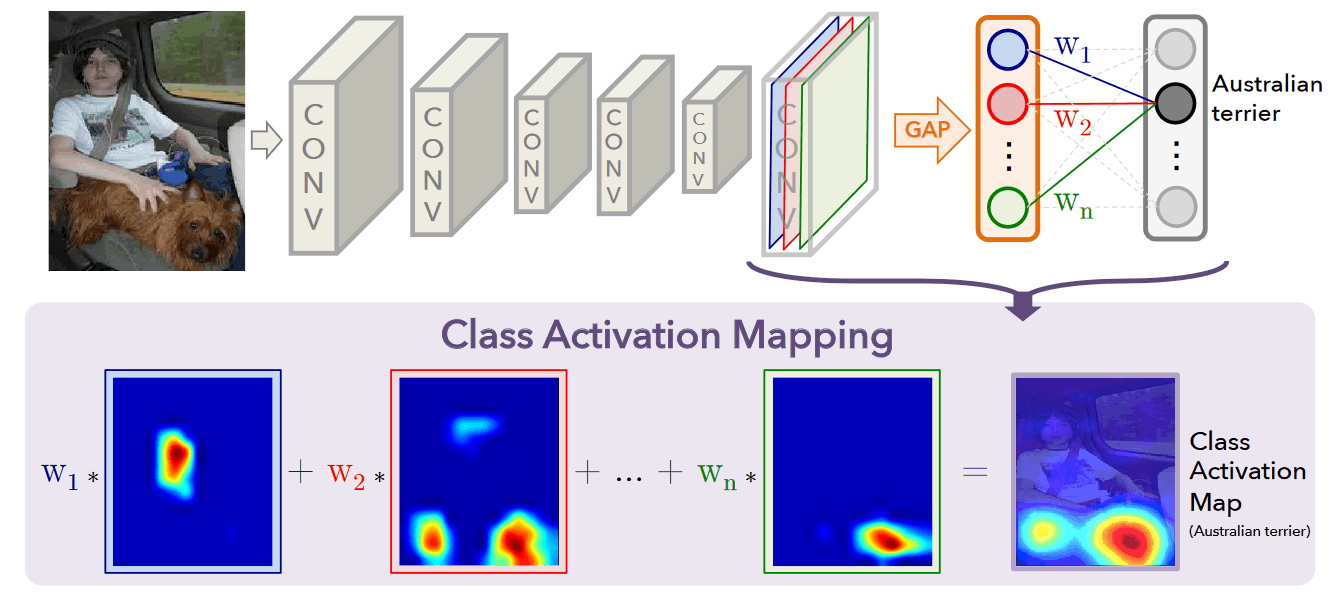
-
上面的这一张图就浓缩了文章的主要工作
-
作者提出了类激活映射(class activation maps ,CAM),可以对指定类别的具有区分性的区域进行可视化
-
CNN网络除了在最后一层的全连接层用了全局平均池化(global pooling,GAP)之外,其余层仅使用了卷积
类别激活的计算
-
对给定的一张图, f k ( x , y ) f_k(x,y) fk(x,y)是最后一层卷积的输出特征图的第 k k k个通道在点 ( x , y ) (x,y) (x,y)的值
-
在对 f k ( x , y ) f_k(x,y) fk(x,y)进行全局平均池化之后,得到的一个标量值
-
F k = ∑ x , y f k ( x , y ) F_k=\sum_{x,y}f_k(x,y) Fk=x,y∑fk(x,y)
-
所有 k k k个通道形成一个 1 ∗ 1 ∗ k 1*1*k 1∗1∗k的特征向量
-
-
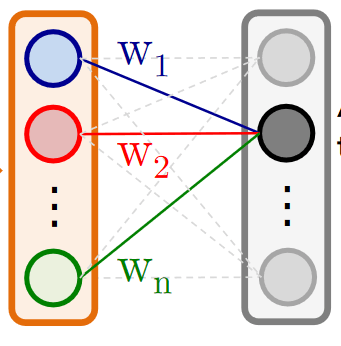
将特征向量过一个全连接层 W ∈ R k × c W\in \mathbf{R}^{k\times c} W∈Rk×c,每一个元素是 w k c w_k^c wkc,表示 F k F_k Fk对于类别 c c c的判定重要度的权重
-
全连接层的输出为未经过归一化的类别概率,第 c c c类的未归一化概率为
-
S c = ∑ k w k c F k = ∑ k w k c ∑ x , y f k ( x , y ) = ∑ x , y ∑ k w k c f k ( x , y ) S_c=\sum_k w_k^c F_k \\ = \sum_k w_k^c \sum_{x,y}f_k(x,y) \\ = \sum_{x,y} \sum_k w_k^c f_k(x,y) Sc=k∑wkcFk=k∑wkcx,y∑fk(x,y)=x,y∑k∑wkcfk(x,y)
-
就是下图右边深灰色节点的值
-
-
-
通过softmax对概率进行归一化
- P c = exp ( S c ) ∑ c exp ( S c ) P_c=\frac{\exp \left(S_{c}\right)}{\sum_{c} \exp \left(S_{c}\right)} Pc=∑cexp(Sc)exp(Sc)
-
第 c c c类的类别激活映射为对最后一层卷积的特征图用 w k c w_k^c wkc进行加权求和
-
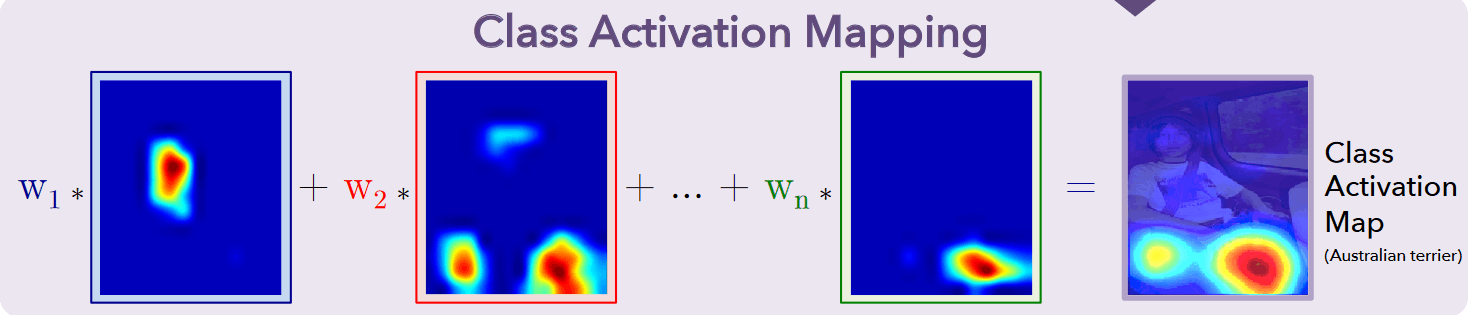
-
原因是前面提到了 w k c w_k^c wkc表示第 k k k个特征图均值对判定为第 c c c的重要程度,因此也可以用这个对特征图进行加权求和(类似PS的图层组合)得到类别激活映射
-
定义类别激活映射 M c M_c Mc是第 c c c类的类别激活映射
-
M c ( x , y ) = ∑ k w k c f k ( x , y ) M_{c}(x, y)=\sum_{k} w_{k}^{c} f_{k}(x, y) Mc(x,y)=k∑wkcfk(x,y)
-
带入到 S c S_c Sc中有
-
S c = ∑ x , y M c ( x , y ) S_c=\sum_{x,y}M_{c}(x, y) Sc=x,y∑Mc(x,y)
-
也说明了 M c M_c Mc直接反映了判别为第 c c c的重要性
-
- 通过将类别激活映射(HW和最后一层卷积的特征图相同)通过上采样(双线性插值)缩放回输入图像大小,通过和原图对比,发现激活值越大的地方在原图中的区域和该类别相关
- 通过CAM可以发现,同一张图片对不同的类别有着不一样的显著性区域

- 白色数值对应着图像分为这一类的置信度
- 比如对于palace(宫廷),其显著性区域集中在图片下方,也就是说网络判断其为palace时更依赖于这一块的特征
- 也就是说如果一张图中含有多个物体时,网络虽然只输出了最大概率的类别 c m a x c_{max} cmax,但是对于其他的类别,在图像选中也会有其对应的激活
