本系列文章是我从《通用源码指导书:MyBatis源码详解》一书中的笔记和总结
本书是基于MyBatis-3.5.2版本,书作者 易哥 链接里是CSDN中易哥的微博。但是翻看了所有文章里只有一篇简单的介绍这本书。并没有过多的展示该书的魅力。接下来我将自己的学习总结记录下来。如果作者认为我侵权请联系删除,再次感谢易哥提供学习素材。本段说明将伴随整个系列文章,尊重原创,本人已在微信读书购买改书。
版权声明:本文为CSDN博主「架构师易哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/onlinedct/article/details/107306041
1.语句处理功能
1.1.MyBatis对多语句类型的支持
在 MyBatis映射文件的编写中,我们常会见到“${}”和“#{}”这两种定义变量的符号,其含义如下。
- ${}:使用这种符号的变量将会以字符串的形式直接插到 SQL片段中。
- #{}:使用这种符号的变量将会以预编译的形式赋值到 SQL片段中。
MyBatis中支持三种语句类型,不同语句类型支持的变量符号不同。MyBatis中的三种语句类型如下。
- STATEMENT:这种语句类型中,只会对 SQL片段进行简单的字符串拼接。因此,只支持使用“${}”定义变量。
- PREPARED:这种语句类型中,会先对 SQL片段进行字符串拼接,然后对 SQL片段进行赋值。因此,支持使用“${}”“#{}”这两种形式定义变量。
- CALLABLE:这种语句类型用来实现执行过程的调用,会先对 SQL 片段进行字符串拼接,然后对 SQL片段进行赋值。因此,支持使用“${}”“#{}”这两种形式定义变量。
<!--直接字符串拼接,必须自己加引号,否则会拼接为下面的语句然后失败::SELECT * FROM `user` WHERE schoolName = Sunny School-->
<select id="queryUserBySchoolName_A" resultType="com.github.yeecode.mybatisdemo.model.User" statementType="STATEMENT">
SELECT * FROM `user` WHERE schoolName = "${schoolName}"
</select>
<!--会把变量转为?后进行填入,不能有引号-->
<select id="queryUserBySchoolName_B" resultType="com.github.yeecode.mybatisdemo.model.User" statementType="PREPARED">
SELECT * FROM `user` WHERE schoolName = #{schoolName}
</select>
<!--使用前需要先到数据库创建以下存储过程:-->
<!--CREATE PROCEDURE `yeecode`(IN `ageMinLimit` int,IN `ageMaxLimit` int,OUT `count` int, OUT `maxAge` int)-->
<!--BEGIN-->
<!--SELECT COUNT(*),MAX(age) INTO count,maxAge FROM user WHERE age >= ageMinLimit AND age <= ageMaxLimit;-->
<!--END $$-->
<select id="runCall" statementType="CALLABLE">
CALL yeecode(
${ageMinLimit},
#{ageMaxLimit,mode=IN,jdbcType=NUMERIC},
#{count,mode=OUT,jdbcType=NUMERIC},
#{maxAge,mode=OUT,jdbcType=NUMERIC}
);
</select>
因为 STATEMENT、PREPARED 形式的 SQL 语句比较常用,不再单独介绍。下面详细介绍 CALLABLE语句的使用。
在对CALLABLE语句进行调用时,可以直接使用Map来设置输入参数。使用MyBatis调用存储过程的操作如下代码所示。
Map<String, Integer> param = new HashMap<>();
param.put("ageMinLimit",10);
param.put("ageMaxLimit",30);
session.selectOne("com.github.yeecode.mybatisdemo.dao.UserMapper.runCall",param);
System.out.println("proceduce param :" + param);
存储过程调用后,MyBatis会根据输出参数设置直接将输出结果写回给定的 Map参数中,键为变量名,值为存储过程结果。
1.2.MyBatis的语句处理功能
statement 子包负责提供语句处理功能,其中StatementHandler 是语句处理功能类的父接口。StatementHandler接口及其子类的类图如图:
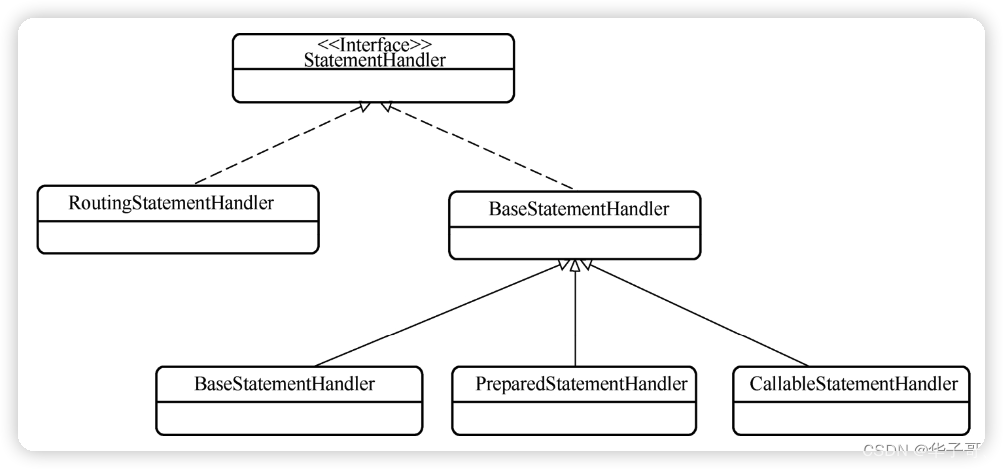
其中 RoutingStatementHandler 类是一个代理类,它能够根据传入的 MappedStatement对象的具体类型选中一个具体的被代理对象,然后将所有实际操作都委托给被代理对象。功能如其名,RoutingStatementHandler 类提供的是路由功能,而路由选择的依据就是语句类型。
// 根据语句类型选取出的被代理类的对象
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 根据语句类型选择被代理对象
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
BaseStatementHandler 作为三个实现类的父类,提供了实现类的公共方法。并且BaseStatementHandler类使用的模板模式在 prepare方法中定义了整个方法的框架,然后将一些与子类相关的操作交给其三个子类处理。
SimpleStatementHandler类、PreparedStatementHandler类和 CallableStatementHandler类是三个真正的 Statement 处理器,分别处理 Statement 对象、PreparedStatement 对象和CallableStatement对象。通过其中的 parameterize方法可以看出三个 Statement处理器的不同。
- SimpleStatementHandler中 parameterize方法的实现为空,因为它只需完成字符串替换即可,不需要进行参数处理。
- PreparedStatementHandler中 parameterize方法最终通过ParameterHandler接口经过多级中转后调用了java.sql.PreparedStatement类中的参数赋值方法。
- CallableStatementHandler中 parameterize方法。它一共完成两步工作:一是通过registerOutputParameters方法中转后调用java.sql.CallableStatement中的输出参数注册方法完成输出参数的注册;二是通过 ParameterHandler接口经过多级中转后调用 java.sql.PreparedStatement类中的参数赋值方法。
/**
* 对语句进行参数处理
* @param statement SQL语句
* @throws SQLException
*/
@Override
public void parameterize(Statement statement) throws SQLException {
// 输出参数的注册
registerOutputParameters((CallableStatement) statement);
// 输入参数的处理
parameterHandler.setParameters((CallableStatement) statement);
}
可见 SimpleStatementHandler类、PreparedStatementHandler类和 CallableStatement-Handler类最终是依靠java.sql包下的 Statement接口及其子接口提供的功能完成具体参数处理操作的。
1.3.参数处理功能
为 SQL语句中的参数赋值是 MyBatis进行语句处理时非常重要的一步,而这一步就是由 parameter子包完成的。
parameter子包中其实只有一个 ParameterHandler接口,它定义了两个方法:
- getParameterObject方法用来获取 SQL语句对应的实参对象。
- setParameters方法用来完成 SQL语句中的变量赋值。
ParameterHandler接口有一个默认的实现类DefaultParameterHandler,DefaultParameterHandler在scripting包的 defaults子包中。
public class DefaultParameterHandler implements ParameterHandler {
// 类型处理器注册表
private final TypeHandlerRegistry typeHandlerRegistry;
// MappedStatement对象(包含完整的增删改查节点信息)
private final MappedStatement mappedStatement;
// 参数对象
private final Object parameterObject;
// BoundSql对象(包含SQL语句、参数、实参信息)
private final BoundSql boundSql;
// 配置信息
private final Configuration configuration;
MyBatis 中支持进行参数设置的语句类型是 PreparedStatement 接口及其子接口(CallableStatement 是 PreparedStatement 的子接口),所以 setParameters 的输入参数是PreparedStatement类型。
/**
* 为语句设置参数
* @param ps 语句
*/
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// 取出参数列表
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// ParameterMode.OUT是CallableStatement的输出参数,已经单独注册。故忽略
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
// 取出属性名称
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
// 从附加参数中读取属性值
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
// 参数对象是基本类型,则参数对象即为参数值
value = parameterObject;
} else {
// 参数对象是复杂类型,取出参数对象的该属性值
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 确定该参数的处理器
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 此方法最终根据参数类型,调用java.sql.PreparedStatement类中的参数赋值方法,对SQL语句中的参数赋值
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
setParameters 方法的实现逻辑也很简单,就是依次取出每个参数的值,然后根据参数类型调用 PreparedStatement中的赋值方法完成赋值。
1.4.结果处理功能
MyBatis查询结果的处理,需要完成的功能有:
- 处理结果映射中的嵌套映射等逻辑;
- 根据映射关系,生成结果对象;
- 根据数据库查询记录对结果对象的属性进行赋值;
- 将结果对象汇总为 List、Map、Cursor等形式。
executor包的 result子包只负责完成“将结果对象汇总为 List、Map、Cursor等形式”这一简单功能中的一部分:将结果对象汇总为 List或 Map的形式。而将结果汇总为 Cursor形式的功能由cursor包实现。
在介绍 result子包之前,我们先介绍位于 session包中的两个接口:ResultContext接口和 ResultHandler接口。
- ResultContext接口表示结果上下文,其中存放了数据库操作的一个结果(对应数据库中的一条记录)。
- ResultHandler 接口表示结果处理器,数据库操作结果会由它处理。因此说,ResultHandler会负责处理 ResultContext。
result 子包中主要有三个类:DefaultResultContext 类、DefaultResultHandler 类和DefaultMapResultHandler类。这三个类中,DefaultResultContext类是 ResultContext接口唯一的实现类,DefaultResultHandler类和DefaultMapResultHandler类是 ResultHandler接口的实现类。
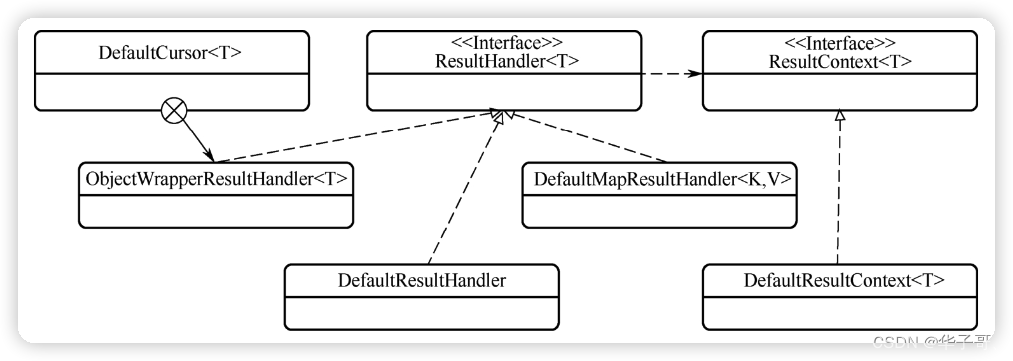
DefaultResultContext 用来存储一个结果对象,对应数据库中的一条记录。
public class DefaultResultContext<T> implements ResultContext<T> {
// 结果对象
private T resultObject;
// 结果计数(表明这是第几个结果对象)
private int resultCount;
// 使用完毕(结果已经被取走)
private boolean stopped;
了解了DefaultResultContext类的各个属性后,对各个ResultHandler类的分析就非常简单了。DefaultResultHandler类负责将 DefaultResultContext类中的结果对象聚合成一个List返回;而 DefaultMapResultHandler类负责将DefaultResultContext类中的结果对象聚合成一个 Map返回。
其中 DefaultMapResultHandler类稍微复杂一些,我们以它为例进行介绍。
public class DefaultMapResultHandler<K, V> implements ResultHandler<V> {
// Map形式的映射结果
private final Map<K, V> mappedResults;
// Map的键。由用户指定,是结果对象中的某个属性名
private final String mapKey;
// 对象工厂
private final ObjectFactory objectFactory;
// 对象包装工厂
private final ObjectWrapperFactory objectWrapperFactory;
// 反射工厂
private final ReflectorFactory reflectorFactory;
/**
* 处理一个结果
* @param context 一个结果
*/
@Override
public void handleResult(ResultContext<? extends V> context) {
// 从结果上下文中取出结果对象
final V value = context.getResultObject();
// 获得结果对象的元对象
final MetaObject mo = MetaObject.forObject(value, objectFactory, objectWrapperFactory, reflectorFactory);
// 基于元对象取出key对应的值
final K key = (K) mo.getValue(mapKey);
mappedResults.put(key, value);
}
DefaultMapResultHandler类中的 handleResult方法用来完成Map的组装。
这样,我们对单个结果对象如何被聚合为 List、Map、Cursor 形式返回进行了了解。DefaultResultContext作为默认的ResultContext实现类,存储了一个结果对象,对应着数据库中的一条记录。而 ResultHandler有三个实现类能够处理DefaultResultContext对象,这三个实现类的功能如下。
- DefaultResultHandler类负责将多个 ResultContext聚合为一个 List返回。
- DefaultMapResultHandler类负责将多个 ResultContext聚合为一个 Map返回。
- DefaultCursor 类中的 ObjectWrapperResultHandler 内部类负责将多个 ResultContext聚合为一个 Cursor返回。
1.5.结果集处理功能
1.4节对 MyBatis将单个结果对象聚合为 List、Map、Cursor的机制进行了介绍。但那只是结果处理流程中非常小的一个环节。在结果处理流程中,尚未完成的功能还有:
- 处理结果映射中的嵌套映射等逻辑;
- 根据映射关系,生成结果对象;
- 根据数据库查询记录对结果对象的属性进行赋值。
以上这些功能均由 resultset子包提供。resultset子包提供的功能虽多,但是只有三个类。
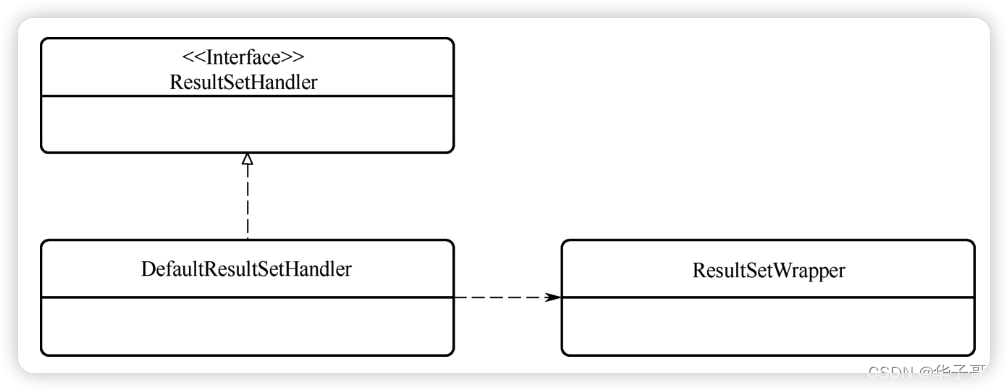
ResultSetWrapper是结果封装类,ResultSetHandler和DefaultResultSetHandler分别是结果集处理器的接口和实现类。
在介绍以上三个类之前,我们先了解 MyBatis的结果集。
1.5.1.MyBatis中多结果集的处理
为了介绍 MyBatis中的结果集处理功能,我们先明确以下概念。
- 结果:从数据库中查询出的一条记录就是一个结果,它可以映射为一个 Java对象。
- 结果集:指结果的集合,从数据库中查询出的多个记录就是一个结果集。结果集可以以 List、Map、Cursor的形式返回。
- 多结果集:即结果集的集合,其中包含了多个结果集。
说到多结果集,大家可能会产生一个疑问:平时每一次数据库查询操作都只会返回一个结果集,怎么会有多结果集的概念?例如,如下代码的 union操作,其实就是把两个结果集进行了合并,但最终两个结果集还是会合并为一个结果集。

虽然结果集中的结果可以明显地被分为两类,但是它们仍然属于一个结果集。在这个结果集中,每条结果都包含 id和 name这两个属性。
但其实,一次数据库查询确实可以返回一个多结果集。

MyBatis也支持处理多结果集,
<resultMap id="userMap" type="User" autoMapping="true">
<collection property="taskList" resultSet="taskRecord" resultMap="taskMap" />
</resultMap>
<resultMap id="taskMap" type="Task">
<result property="id" column="id" />
<result property="userId" column="userId" />
<result property="taskName" column="taskName" />
</resultMap>
<!--返回两个结果组成的结果集-->
<select id="query" resultMap="userMap,taskMap" resultSets="userRecord,taskRecord" statementType="CALLABLE">
CALL multiResults()
</select>
语句会接受两个结果集,并将两个结果集分别命名为 userRecord和taskRecord。然后使用 userMap来对结果集 userRecord进行映射,使用 taskMap来对结果集 taskRecord进行映射。
最终可以得到result变量中存储的多结果集,其中的两个结果集均使用 List存储。第一个结果集为使用userMap映射出的 User对象列表,第二个结果集为使用taskMap映射出的 Task对象列表。
1.5.2.结果集封装类
java.sql.Statement进行完数据库操作之后,对应的操作结果是由 java.sql.ResultSet返回的。java.sql.ResultSet接口中定义的方法,它主要分为几大类:
- 切换到下一结果,读取本结果是否为第一个结果、最后一个结果等结果间切换相关的方法;
- 读取当前结果某列的值;
- 修改当前结果某列的值(修改不会影响数据库中的真实值);
- 一些其他的辅助功能,如读取所有列的类型信息等。
以上这几类方法已经能够满足数据库结果的查询操作。
而 MyBatis中的 ResultSetWrapper类是对 java.sql.ResultSet的进一步封装,这里用到了装饰器模式。ResultSetWrapper类在 java.sql.ResultSet接口的基础上扩展出了更多的功能,这些功能包括获取所有列名的列表、获取所有列的类型的列表、获取某列的 JDBC类型、获取某列对应的类型处理器等。
/*
* ResultSet的封装,包含了ResultSet的一些元数据
* 类似于装饰器模式,但是比较简单。只是在原有类的外部再封装一些属性、方法
*/
public class ResultSetWrapper {
// 被装饰的resultSet对象
private final ResultSet resultSet;
// 类型处理器注册表
private final TypeHandlerRegistry typeHandlerRegistry;
// resultSet中各个列对应的列名列表
private final List<String> columnNames = new ArrayList<>();
// resultSet中各个列对应的Java类型名列表
private final List<String> classNames = new ArrayList<>();
// resultSet中各个列对应的JDBC类型列表
private final List<JdbcType> jdbcTypes = new ArrayList<>();
// <列名,< java类型,TypeHandler>>
// 这里的数据是不断组建起来的。java类型传入,然后去全局handlerMap索引java类型的handler放入map,然后在赋给列名。
// 每个列后面的java类型不应该是唯一的么?不是的
// <resultMap id="userMapFull" type="com.example.demo.UserBean">
// <result property="id" column="id"/>
// <result property="schoolName" column="id"/>
// </resultMap>
// 上面就可能不唯一,同一个列可以给不同的java属性
// 类型与类型处理器的映射表。结构为:Map<列名,Map<Java类型,类型处理器>>
private final Map<String, Map<Class<?>, TypeHandler<?>>> typeHandlerMap = new HashMap<>();
// 记录了所有的有映射关系的列。
// key为resultMap的id,后面的List为该resultMap中有映射的列的列表
// <resultMap的id,List<对象映射的列名>>
// 记录了所有的有映射关系的列。结构为:Map<resultMap的id,List<对象映射的列名>>
private final Map<String, List<String>> mappedColumnNamesMap = new HashMap<>();
// 记录了所有的无映射关系的列。
// key为resultMap的id,后面的List为该resultMap中无映射的列的列表
// // <resultMap的id : List<对象映射的列名>>
// 记录了所有的无映射关系的列。结构为:Map<resultMap的id,List<对象映射的列名>>
private final Map<String, List<String>> unMappedColumnNamesMap = new HashMap<>();
1.5.2.结果集处理类
ResultSetHandler是结果集处理器接口,它定义了结果集处理器的三个抽象方法。
- <E> List<E> handleResultSets(Statement stmt):将Statement的执行结果处理为 List。
- <E> Cursor<E> handleCursorResultSets(Statement stmt):将 Statement的执行结果处理为 Map。
- void handleOutputParameters(CallableStatement cs):处理存储过程的输出结果。
DefaultResultSetHandler类作为 ResultSetHandler接口的默认也是唯一的实现类,实现了上述的抽象方法。下面以 DefaultResultSetHandler类中的 handleResultSets方法为例,介绍 MyBatis如何完成结果集的处理。
通过 handleResultSets方法的名称(Sets为复数形式)也能看出,它能够处理多结果集。在处理多结果集时,我们得到的是两层列表,即结果集列表和嵌套在其中的结果列表,而在处理单结果集时,我们可以直接得到结果列表。

/**
* 处理Statement得到的多结果集(也可能是单结果集,这是多结果集的一种简化形式),最终得到结果列表
* @param stmt Statement语句
* @return 结果列表
* @throws SQLException
*/
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
// 用以存储处理结果的列表
final List<Object> multipleResults = new ArrayList<>();
// 可能会有多个结果集,该变量用来对结果集进行计数
int resultSetCount = 0;
// 可能会有多个结果集,先取出第一个结果集
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 查询语句对应的resultMap节点,可能含有多个
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// 合法性校验(存在输出结果集的情况下,resultMapCount不能为0)
validateResultMapsCount(rsw, resultMapCount);
// 循环遍历每一个设置了resultMap的结果集
while (rsw != null && resultMapCount > resultSetCount) {
// 获得当前结果集对应的resultMap
ResultMap resultMap = resultMaps.get(resultSetCount);
// 进行结果集的处理
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一结果集
rsw = getNextResultSet(stmt);
// 清理上一条结果集的环境
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
// 获取多结果集中所有结果集的名称
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
// 循环遍历每一个没有设置resultMap的结果集
while (rsw != null && resultSetCount < resultSets.length) {
// 获取该结果集对应的父级resultMap中的resultMapping(注:resultMapping用来描述对象属性的映射关系)
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
// 获取被嵌套的resultMap的编号
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
// 处理嵌套映射
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
// 判断是否是单结果集:如果是则返回结果列表;如果否则返回结果集列表
return collapseSingleResultList(multipleResults);
}
handleResultSets 方法完成了对多结果集的处理。但是对于每一个结果集的处理是由handleResultSet子方法实现的
/**
* 处理单一的结果集
* @param rsw ResultSet的包装
* @param resultMap resultMap节点的信息
* @param multipleResults 用来存储处理结果的list
* @param parentMapping
* @throws SQLException
*/
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
// 嵌套的结果
// 向子方法传入parentMapping。处理结果中的记录。
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
// 非嵌套的结果
if (resultHandler == null) {
// defaultResultHandler能够将结果对象聚合成一个List返回
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
// 处理结果中的记录。
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
} else {
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
closeResultSet(rsw.getResultSet());
}
}
传入 handleResultSet 方法的已经是单结果集,handleResultSet 方法调用了handleRowValues方法进行进一步的处理。
在handleRowValues方法中,会以当前映射中是否存在嵌套为依据再次进行分类,分别调用handleRowValuesForNestedResultMap方法和handleRowValuesForSimpleResultMap方法。
/**
* 处理单结果集中的属性
* @param rsw 单结果集的包装
* @param resultMap 结果映射
* @param resultHandler 结果处理器
* @param rowBounds 翻页限制条件
* @param parentMapping 父级结果映射
* @throws SQLException
*/
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler,
RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) {
// 前置校验
ensureNoRowBounds();
checkResultHandler();
// 处理嵌套映射
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
// 处理单层映射
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
以 handleRowValuesForSimpleResultMap 方法为例,继续查看整体的处理流程
/**
* 处理非嵌套映射的结果集
* @param rsw 结果集包装
* @param resultMap 结果映射
* @param resultHandler 结果处理器
* @param rowBounds 翻页限制条件
* @param parentMapping 父级结果映射
* @throws SQLException
*/
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
// 当前要处理的结果集
ResultSet resultSet = rsw.getResultSet();
// 根据翻页配置,跳过指定的行
skipRows(resultSet, rowBounds);
// 持续处理下一条结果,判断条件为:还有结果需要处理 && 结果集没有关闭 && 还有下一条结果
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
// 经过鉴别器鉴别,确定经过鉴别器分析的最终要使用的resultMap
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
// 拿到了一行记录,并且将其转化为一个对象
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
// 把这一行记录转化出的对象存起来
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
在handleRowValuesForSimpleResultMap方法中,真正完成了对结果集中结果的处理。对每一条结果进行处理时,包括以下几个功能。
- 基于鉴别器获取该条记录对应的 resultMap,该功能调用resolveDiscriminatedResult-Map子方法实现。
- 根据 resultMap,将这条记录转化为一个对象,该功能调用getRowValue子方法实现。
- 把由这一行记录转化得到的对象存起来,该功能调用storeObject子方法实现。
getRowValue方法
该方法使用反射创建了记录对应的对象,并给对象的属性进行了赋值。创建对象的操作过程大家可以通过 createResultObject子方法继续追踪,为对象属性赋值的操作过程可以通过applyAutomaticMappings 子方法和applyPropertyMappings子方法继续追踪。
/**
* 将一条记录转化为一个对象
* @param rsw 结果集包装
* @param resultMap 结果映射
* @param columnPrefix 列前缀
* @return 转化得到的对象
* @throws SQLException
*/
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建这一行记录对应的对象
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
// 根据对象得到其MetaObject
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
// 是否允许自动映射未明示的字段
if (shouldApplyAutomaticMappings(resultMap, false)) {
// 自动映射未明示的字段
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 按照明示的字段进行重新映射
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
storeObject方法
在storeObject方法中,会根据当前对象的不同分别进行处理:
- 如果当前对象属于父级映射,则将该对象绑定到父级对象上;
- 如果当前对象属于独立映射,则使用 ResultHandler聚合该对象。
/**
* 存储当前结果对象
* @param resultHandler 结果处理器
* @param resultContext 结果上下文
* @param rowValue 结果对象
* @param parentMapping 父级结果映射
* @param rs 结果集
* @throws SQLException
*/
private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) {
// 存在父级,则将这一行记录对应的结果对象绑定到父级结果上
linkToParents(rs, parentMapping, rowValue);
} else {
// 使用resultHandler聚合该对象
callResultHandler(resultHandler, resultContext, rowValue);
}
}
这样经过层层子方法调用后便完成了 handleResultSets 方法的源码阅读。可见在handleResultSets方法中,完成了生成结果对象、为结果对象的属性赋值、将结果对象进行聚合或绑定等重要操作。
2.执行器
每个子包都为执行器提供了一些子功能。但是最终这些子功能均由 Executor接口及其实现类串接了起来,共同向外提供服务。
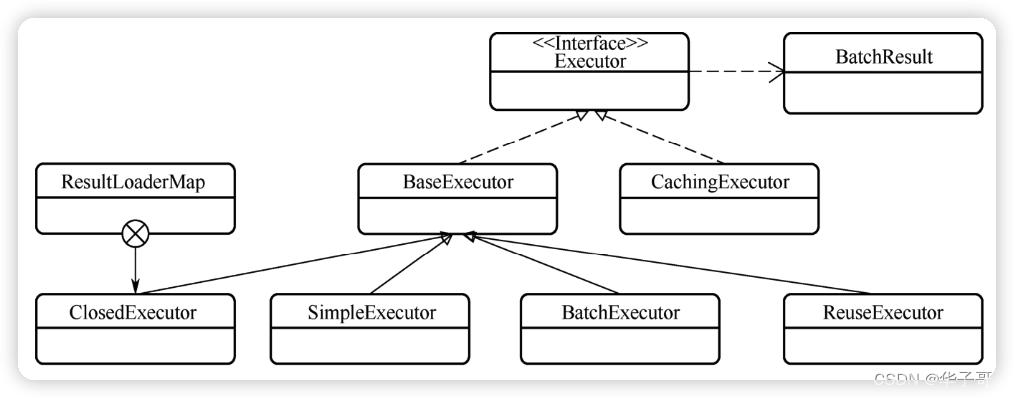
2.1.执行器接口
首先看一下 Executor接口中定义的方法。
public interface Executor {
ResultHandler NO_RESULT_HANDLER = null;
// 数据更新操作,其中数据的增加、删除、更新均可由该方法实现
int update(MappedStatement ms, Object parameter) throws SQLException;
// 数据查询操作,返回结果为列表形式
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
// 数据查询操作,返回结果为列表形式
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
// 数据查询操作,返回结果为游标形式
<E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException;
// 清理缓存
List<BatchResult> flushStatements() throws SQLException;
// 提交事务
void commit(boolean required) throws SQLException;
// 回滚事务
void rollback(boolean required) throws SQLException;
// 创建当前查询的缓存键值
CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql);
// 本地缓存是否有指定值
boolean isCached(MappedStatement ms, CacheKey key);
// 清理本地缓存
void clearLocalCache();
// 懒加载
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
// 获取事务
Transaction getTransaction();
// 关闭执行器
void close(boolean forceRollback);
// 判断执行器是否关闭
boolean isClosed();
// 设置执行器包装
void setExecutorWrapper(Executor executor);
}
基于以上方法可以完成数据的增、删、改、查,以及事务处理等操作。而事实上,MyBatis的所有数据库操作也确实是通过调用这些方法实现的。
2.1.执行器基类与实现类
Executor接口的各个实现类中,CachingExecutor并没有包含具体的数据库操作,而是在其他数据库操作的基础上封装了一层缓存,因此它没有继承BaseExecutor。而其他的各个实现类都继承了BaseExecutor。
BaseExecutor 是一个抽象类,并用到了模板模式。它实现了其子类的一些共有的基础功能,而将与子类直接相关的操作交给子类处理。
/**
* 查询数据库中的数据
* @param ms 映射语句
* @param parameter 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param <E> 结果类型
* @return 结果列表
* @throws SQLException
*/
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 新的查询栈且要求清除缓存
// 清除一级缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 尝试从本地缓存获取结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 本地缓存中有结果,则对于CALLABLE语句还需要绑定到IN/INOUT参数上
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 本地缓存没有结果,故需要查询数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 懒加载操作的处理
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
// 如果本地缓存的作用域为STATEMENT,则立刻清除本地缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
在 query方法的核心方法中,会尝试读取一级缓存,而在缓存中无结果时,则会调用queryFromDatabase方法进行数据库中结果的查询。
/**
* 从数据库中查询结果
* @param ms 映射语句
* @param parameter 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param <E> 结果类型
* @return 结果列表
* @throws SQLException
*/
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 向缓存中增加占位符,表示正在查询
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 删除占位符
localCache.removeObject(key);
}
// 将查询结果写入缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
doQuery子方法的具体实现则交由BaseExecutor的子类实现,因此这是典型的模板模式。
接下来不妨再分析一下 BaseExecutor中 update方法的源码
/**
* 更新数据库数据,INSERT/UPDATE/DELETE三种操作都会调用该方法
* @param ms 映射语句
* @param parameter 参数对象
* @return 数据库操作结果
* @throws SQLException
*/
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource())
.activity("executing an update").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
// 清理本地缓存
clearLocalCache();
// 返回调用子类进行操作
return doUpdate(ms, parameter);
}
可以很明显地看出,update 方法的源码要比 query 方法的源码简单很多。查询操作的源码往往比增加、删除、修改操作的源码复杂的原因是:
- 查询操作的输入参数相对比较复杂,而增加、删除、修改等操作的参数通常比较简单。
- 查询操作的输出结果相对比较复杂,结果通常会被映射成对象,甚至还会包括嵌套、结果集操作、懒加载、对象类型鉴别等复杂操作;而增加、删除、修改等操作的输出结果通常比较简单,仅包含影响的条数。
- 查询操作的输出结果形式比较复杂,如支持列表List、映射表Map、游标 Cursor等形式的输出;而增加、删除、修改等操作的结果形式通常比较简单,仅包含一个数字。
- 查询操作的实现比较复杂,例如需要进行缓存处理、懒加载处理、嵌套映射处理等;而增加、删除、修改等操作则往往不需要这些复杂的处理。
正因为查询操作比其他操作更为复杂,所以在本书的源码阅读中经常以查询操作为例进行源码解析。在源码阅读时,往往会遇到很多分支。这些分支在实现思路上是相似的,我们没有必要将它们的源码全部进行阅读,只需选取其中一些有代表性的分支深入阅读即可。在选择分支的过程中,有以下两个思路。
- 可以考虑选择最为复杂的分支,这样当这个分支的代码被我们分析清楚时,其他分支的代码自然也就清楚了
- 也可以考虑选择最为简单的分支,这样能让我们快速读懂代码的思路,再去分析其他复杂分支也会更加容易。
具体遵循哪个思路进行分支的选择要根据具体情况来分析。通常来说,对于重要的代码选择复杂的分支;对于次要的代码选择简单的分支;对于简单的代码选择复杂的分支;对于复杂的代码选择简单的分支。
对于 MyBatis而言,输入/输出参数的处理、缓存的处理、懒加载的处理等都是一些非常重要的功能。因此,我们会选择包含这些功能的查询操作分支展开源码阅读。
BaseExecutor有四个实现类,其功能分别如下。
- ClosedExecutor:一个仅能表征自身已经关闭的执行器,没有其他实际功能。
- SimpleExecutor:一个最为简单的执行器。
- BatchExecutor:支持批量执行功能的执行器。
- ReuseExecutor:支持 Statement对象复用的执行器。
SimpleExecutor、BatchExecutor、ReuseExecutor 这三个执行器的选择是在MyBatis的配置文件中进行的,可选的值由session包中的枚举类 ExecutorType定义。这三个执行器主要基于 StatementHandler完成创建 Statement对象、绑定参数等工作。
BatchResult也是 executor中的一个类,它可以保存批量操作的参数对象列表和影响条数列表。
3.错误上下文
在很多方法的开始阶段都会调用 ErrorContext 类的相关方法。
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
其中的 ErrorContext 类是一个错误上下文,它能够提前将一些背景信息保存下来。这样在真正发生错误时,便能将这些背景信息提供出来,进而给我们的错误排查带来便利。
public class ErrorContext {
// 获得当前操作系统的换行符
private static final String LINE_SEPARATOR = System.getProperty("line.separator","\n");
// 将自身存储进ThreadLocal,从而进行线程间的隔离
private static final ThreadLocal<ErrorContext> LOCAL = new ThreadLocal<>();
// 存储上一版本的自身,从而组成错误链
private ErrorContext stored;
// 下面几条为错误的详细信息,可以写入一项或者多项
private String resource;
private String activity;
private String object;
private String message;
private String sql;
private Throwable cause;
ErrorContext 类的属性设置非常简单,但是整个类却设计得非常巧妙。首先,
/**
* 从ThreadLocal取出已经实例化的ErrorContext,或者实例化一个ErrorContext放入ThreadLocal
* @return ErrorContext实例
*/
public static ErrorContext instance() {
ErrorContext context = LOCAL.get();
if (context == null) {
context = new ErrorContext();
LOCAL.set(context);
}
return context;
}
ErrorContext类实现了单例模式,而它的单例是绑定到 ThreadLocal上的。这保证了每个线程都有唯一的一个错误上下文 ErrorContext。
ErrorContext 类还有一种包装机制,即每个 ErrorContext 对象内可以包装一个ErrorContext对象。这样,错误上下文就可以组成一条错误链,这和前面介绍的异常链十分类似。该包装功能由 store方法实现:
/**
* 创建一个包装了原有ErrorContext的新ErrorContext
* @return 新的ErrorContext
*/
public ErrorContext store() {
ErrorContext newContext = new ErrorContext();
newContext.stored = this;
LOCAL.set(newContext);
return LOCAL.get();
}
当然,除了能够创建一个包装了原有 ErrorContext 对象的新ErrorContext 对象外,ErrorContext类还支持这种操作的逆操作——将某个 ErrorContext对象的内部 ErrorContext对象剥离出来。该剥离功能由 recall方法实现:
/**
* 剥离出当前ErrorContext的内部ErrorContext
* @return 剥离出的ErrorContext对象
*/
public ErrorContext recall() {
if (stored != null) {
LOCAL.set(stored);
stored = null;
}
return LOCAL.get();
}
除此之外,ErrorContext类中还有用来清除所有信息的 reset方法、用来转化为字符串输出的 toString方法,以及用来设置各个详细信息的 instance、resource、activity、store等方法。这些方法的使用场景如下。
- 当需要获得当前线程的 ErrorContext对象时,调用 instance方法。
- 当线程执行到某一阶段产生了新的上下文信息时,调用resource、activity等方法向ErrorContext对象补充上下文信息。
- 当线程进入下一级操作并处于一个全新的环境时,调用 store 方法获得一个包装了原有 ErrorContext对象的新 ErrorContext对象。
- 当线程从下一级操作返回上一级时,调用 recall方法剥离上一级的 ErrorContext对象。
- 当线程进入一个与之前操作无关的新环境时,调用 reset方法清除 ErrorContext对象的所有信息。
- 当线程需要打印异常信息时,调用 toString方法输出错误发生时的环境信息。
通过这些操作,线程的 ErrorContext 类中时刻保存着当前时刻的上下文信息,一旦真正发生异常便可以把这些信息提供出来。

wrapException方法(该方法包含在 exceptions包的 ExceptionFactory类中),只是显式地更新了 ErrorContext对象中的 message属性和 cause属性,但toString方法输出的结果中可能包含更为丰富的属性信息。而那些属性信息是随着线程执行环境的变化而实时更新的。