本系列文章是我从《通用源码指导书:MyBatis源码详解》一书中的笔记和总结
本书是基于MyBatis-3.5.2版本,书作者 易哥 链接里是CSDN中易哥的微博。但是翻看了所有文章里只有一篇简单的介绍这本书。并没有过多的展示该书的魅力。接下来我将自己的学习总结记录下来。如果作者认为我侵权请联系删除,再次感谢易哥提供学习素材。本段说明将伴随整个系列文章,尊重原创,本人已在微信读书购买改书。
版权声明:本文为CSDN博主「架构师易哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/onlinedct/article/details/107306041
1.jdbc包
jdbc包是 MyBatis中一个十分独立的包,该包提供了数据库操作语句的执行能力和脚本运行能力。
jdbc包看起来非常简单,除即将废弃的 SelectBuilder和SqlBuilder类外,只剩下六个类。但是,整个包的源码有很多地方值得揣摩。
我们首先给出以下两点疑问,然后带着这两点疑问继续后面的源码分析。
- AbstractSQL类中的很多方法名是大写。例如,UPDATE应该写作 update才对,为什么会出现这样的情况?
- 整个 jdbc包中的所有类都没有被外部引用过,那该包有什么存在的意义?
1.1 AbstractSQL类与SQL类
AbstractSQL 类是一个抽象类,它含有一个抽象方法 getSelf。而 SQL 类作为AbstractSQL类的子类实现了该抽象方法。
AbstractSQL类包含两个静态内部类:SafeAppendable类和SQLStatement类。
- SafeAppendable是一个拼接器,它的 append方法也能实现串的拼接功能。其功能实现比较简单。
// Appendable接口:StringBuilder/StringBuffer等都是它的子类,表征具有可拼接性,字符等可以拼接在后面。
// 一个安全的拼接器,安全是因为外部调用不到。而内部又通过实例化调用
private static class SafeAppendable {
// 主串
private final Appendable a;
// 主串是否为空
private boolean empty = true;
public SafeAppendable(Appendable a) {
super();
this.a = a;
}
/**
* 向主串拼接一段字符串
* @param s 被拼接的字符串
* @return SafeAppendable内部类自身
*/
public SafeAppendable append(CharSequence s) {
try {
// 要拼接的串长度不为零,则拼完后主串也不是空了
if (empty && s.length() > 0) {
empty = false;
}
// 拼接
a.append(s);
} catch (IOException e) {
throw new RuntimeException(e);
}
return this;
}
/**
* 判断当前主串是否为空
* @return 当前主串是否为空
*/
public boolean isEmpty() {
return empty;
}
}
- SQLStatement内部类可以完整地表述出一条 SQL语句。这些属性完整地表述了一条 SQL语句所需要的各种片段信息。
// 当前语句的语句类型
StatementType statementType;
// 语句片段信息
List<String> sets = new ArrayList<>();
List<String> select = new ArrayList<>();
List<String> tables = new ArrayList<>();
List<String> join = new ArrayList<>();
List<String> innerJoin = new ArrayList<>();
List<String> outerJoin = new ArrayList<>();
List<String> leftOuterJoin = new ArrayList<>();
List<String> rightOuterJoin = new ArrayList<>();
List<String> where = new ArrayList<>();
List<String> having = new ArrayList<>();
List<String> groupBy = new ArrayList<>();
List<String> orderBy = new ArrayList<>();
List<String> lastList = new ArrayList<>();
List<String> columns = new ArrayList<>();
List<List<String>> valuesList = new ArrayList<>();
// 表征是否去重,该字段仅仅对于SELECT操作有效,它决定是SELECT还是SELECT DISTINCT
boolean distinct;
// 结果偏移量
String offset;
// 结果总数约束
String limit;
// 结果约束策略
LimitingRowsStrategy limitingRowsStrategy = LimitingRowsStrategy.NOP;
并且 SQLStatement中确实存在一个 sql方法,能够根据不同的语句类型调用相应的子方法将语句片段信息拼接成一个完整的SQL语句。
/**
* 根据语句类型,调用不同的语句拼接器拼接SQL语句
* @param a 起始字符串
* @return 拼接完成后的结果
*/
public String sql(Appendable a) {
SafeAppendable builder = new SafeAppendable(a);
if (statementType == null) {
return null;
}
String answer;
switch (statementType) {
case DELETE:
answer = deleteSQL(builder);
break;
case INSERT:
answer = insertSQL(builder);
break;
case SELECT:
answer = selectSQL(builder);
break;
case UPDATE:
answer = updateSQL(builder);
break;
default:
answer = null;
}
return answer;
}
// SELECT 操作的拼接
// 因为SELECT操作(其他操作也是)的字符拼接是固定的,因此只要给定各个keyword的list即可按照顺序完成拼接
/**
* 将SQL语句片段信息拼接为一个完整的SELECT语句
* @param builder 语句拼接器
* @return 拼接完成的SQL语句字符串
*/
private String selectSQL(SafeAppendable builder) {
if (distinct) {
sqlClause(builder, "SELECT DISTINCT", select, "", "", ", ");
} else {
sqlClause(builder, "SELECT", select, "", "", ", ");
}
sqlClause(builder, "FROM", tables, "", "", ", ");
joins(builder); // JOIN操作相对复杂,调用单独的joins子方法进行操作
sqlClause(builder, "WHERE", where, "(", ")", " AND ");
sqlClause(builder, "GROUP BY", groupBy, "", "", ", ");
sqlClause(builder, "HAVING", having, "(", ")", " AND ");
sqlClause(builder, "ORDER BY", orderBy, "", "", ", ");
limitingRowsStrategy.appendClause(builder, offset, limit);
return builder.toString();
}
- AbstractSQL类
有了SQLStatement和 SafeAppendable这两个内部类之后,外部类 AbstractSQL就能不依赖其他类而实现 SQL语句的拼接工作了。
public String queryUsersBySchoolName() {
return new SQL()
.SELECT("*")
.FROM("user")
.WHERE("schoolName = #{schoolName}")
.toString();
}
基于 AbstractSQL类的子类SQL类进行的将字符串片段拼接为 SQL语句的工作。
解答了我们本章开始时给出的一个疑问:AbstractSQL类中存在大量的全大写字母命名的方法,如UPDATE、SET等,这是为了照顾用户的使用习惯。因为通常我们在书写 SQL语句时会将 UPDATE、SET等关键字大写。
知道了AbstractSQL类的结构后,就可以分析整个AbstractSQL类的使用了。
- 首先,用户使用类似“SELECT(“*”).FROM(“user”).WHERE(“schoolName=#{schoolName}”)”的语句设置 SQL 语句片段,这些片段被保存在 AbstractSQL 中SQLStatement内部类的 ArrayList中。
- 用户调用 toString()操作时,触发了 SQL片段的拼接工作。在 SQLStatement内部类中按照一定规则拼接成完整的SQL语句。
拼接函数的整个拼接操作的模板是固定的。
/**
* 将SQL语句片段信息拼接为一个完整的INSERT语句
* @param builder 语句拼接器
* @return 拼接完成的SQL语句字符串
*/
private String insertSQL(SafeAppendable builder) {
sqlClause(builder, "INSERT INTO", tables, "", "", "");
sqlClause(builder, "", columns, "(", ")", ", ");
for (int i = 0; i < valuesList.size(); i++) {
sqlClause(builder, i > 0 ? "," : "VALUES", valuesList.get(i), "(", ")", ", ");
}
return builder.toString();
}
那这是不是意味着用户在组建 SQL语句时的语句顺序是可以打乱的呢?事实确实如此。顺序打乱后完全不会影响代码的执行。
public String queryUsersBySchoolName() {
return new SQL()
.SELECT("*")
.WHERE("schoolName = #{schoolName}")
.FROM("user")
.toString();
}
- SQL类是 AbstractSQL的子类,仅仅重写了其中的一个 getSelf方法。
@Override
public SQL getSelf() {
return this;
}
那 AbstractSQL为什么要留存一个抽象方法,然后再创建一个SQL类来实现呢?这一切的意义是什么呢?
将AbstractSQL作为抽象方法独立出来,使得我们可以继承AbstractSQL实现其他的子类,保证了 AbstractSQL类更容易被扩展。
例如:我们可以创建一个继承了 AbstractSQL类的ExplainSQL类。然后在 ExplainSQL类中增加一个行为,例如,在所有的操作前都增加 EXPLAIN前缀以实现 SQL运行性能的分析。
1.2 SqlRunner
SqlRunner类是 MyBatis提供的可以直接执行 SQL语句的工具类。可以直接调用 SqlRunner执行SQL语句。
// SqlRunner类的使用
String sql = "SELECT * FROM user WHERE age = ?;";
SqlRunner sqlRunner = new SqlRunner(connection);
List<Map<String, Object>> result = sqlRunner.selectAll(sql,15);
System.out.println(result);
// SqlRunner类的使用,email变量值为null
sql = "UPDATE user SET email = ? WHERE id = 2;";
Integer out = sqlRunner.update(sql,Null.STRING);
System.out.println(out);
在使用 SqlRunner时有一点要注意,那就是如果参数为 null,则需要引用枚举类型 Null中的枚举值。这是因为 Null中的枚举类型包含了类型信息和类型处理器信息。
public enum Null {
BOOLEAN(new BooleanTypeHandler(), JdbcType.BOOLEAN),
BYTE(new ByteTypeHandler(), JdbcType.TINYINT),
SHORT(new ShortTypeHandler(), JdbcType.SMALLINT),
INTEGER(new IntegerTypeHandler(), JdbcType.INTEGER),
LONG(new LongTypeHandler(), JdbcType.BIGINT),
FLOAT(new FloatTypeHandler(), JdbcType.FLOAT),
DOUBLE(new DoubleTypeHandler(), JdbcType.DOUBLE),
BIGDECIMAL(new BigDecimalTypeHandler(), JdbcType.DECIMAL),
STRING(new StringTypeHandler(), JdbcType.VARCHAR),
CLOB(new ClobTypeHandler(), JdbcType.CLOB),
LONGVARCHAR(new ClobTypeHandler(), JdbcType.LONGVARCHAR),
BYTEARRAY(new ByteArrayTypeHandler(), JdbcType.LONGVARBINARY),
BLOB(new BlobTypeHandler(), JdbcType.BLOB),
LONGVARBINARY(new BlobTypeHandler(), JdbcType.LONGVARBINARY),
OBJECT(new ObjectTypeHandler(), JdbcType.OTHER),
OTHER(new ObjectTypeHandler(), JdbcType.OTHER),
TIMESTAMP(new DateTypeHandler(), JdbcType.TIMESTAMP),
DATE(new DateOnlyTypeHandler(), JdbcType.DATE),
TIME(new TimeOnlyTypeHandler(), JdbcType.TIME),
SQLTIMESTAMP(new SqlTimestampTypeHandler(), JdbcType.TIMESTAMP),
SQLDATE(new SqlDateTypeHandler(), JdbcType.DATE),
SQLTIME(new SqlTimeTypeHandler(), JdbcType.TIME);
// 参数的类型处理器
private TypeHandler<?> typeHandler;
// 参数的JDBC类型
private JdbcType jdbcType;
使用 Null的枚举值进行参数设置,确保了参数值虽然为 null,但参数的类型是明确的。而具有明确的参数类型在PreparedStatement的setNull函数中是必需的,SqlRunner类为参数赋null值时最终调用了下面的setNull函数:
void setNull(int parameterIndex, int sqlType) throws SQLException;
SqlRunner中的相关方法都比较简单:
/**
* 执行多个数据的查询操作,即SELECT操作
* @param sql 要查询的SQL语句
* @param args SQL语句的参数
* @return 查询结果
* @throws SQLException
*/
public List<Map<String, Object>> selectAll(String sql, Object... args) throws SQLException {
PreparedStatement ps = connection.prepareStatement(sql);
try {
setParameters(ps, args);
ResultSet rs = ps.executeQuery();
return getResults(rs);
} finally {
try {
ps.close();
} catch (SQLException e) {
//ignore
}
}
}
在获得查询结果之后,SqlRunner还使用结果处理函数getResults对结果进行进一步的处理。该函数负责将数据库操作返回的结果提取出来,用列表的形式来返回。
/**
* 处理数据库操作的返回结果
* @param rs 返回的结果
* @return 处理后的结果列表
* @throws SQLException
*/
private List<Map<String, Object>> getResults(ResultSet rs) throws SQLException {
try {
List<Map<String, Object>> list = new ArrayList<>();
// 返回结果的字段名列表,按照字段顺序排列
List<String> columns = new ArrayList<>();
// 返回结果的类型处理器列表,按照字段顺序排列
List<TypeHandler<?>> typeHandlers = new ArrayList<>();
// 获取返回结果的表信息、字段信息等
ResultSetMetaData rsmd = rs.getMetaData();
for (int i = 0, n = rsmd.getColumnCount(); i < n; i++) {
// 记录字段名
columns.add(rsmd.getColumnLabel(i + 1));
// 记录字段的对应类型处理器
try {
Class<?> type = Resources.classForName(rsmd.getColumnClassName(i + 1));
TypeHandler<?> typeHandler = typeHandlerRegistry.getTypeHandler(type);
if (typeHandler == null) {
typeHandler = typeHandlerRegistry.getTypeHandler(Object.class);
}
typeHandlers.add(typeHandler);
} catch (Exception e) {
// 默认的类型处理器是Object处理器
typeHandlers.add(typeHandlerRegistry.getTypeHandler(Object.class));
}
}
// 循环处理结果
while (rs.next()) {
Map<String, Object> row = new HashMap<>();
for (int i = 0, n = columns.size(); i < n; i++) {
// 字段名
String name = columns.get(i);
// 对应处理器
TypeHandler<?> handler = typeHandlers.get(i);
// 放入结果中,key为字段名大写,value为取出的结果值
row.put(name.toUpperCase(Locale.ENGLISH), handler.getResult(rs, name));
}
list.add(row);
}
return list;
} finally {
if (rs != null) {
try {
rs.close();
} catch (Exception e) {
// ignore
}
}
}
}
SqlRunner类能接受 SQL语句和参数,然后执行数据库操作。不过,SqlRunner并不能完成对象和 SQL参数的映射、SQL结果和对象的映射等复杂的操作。
1.3 ScriptRunner类
ScriptRunner是 MyBatis提供的直接执行 SQL脚本的工具类,这使得开发者可以直接将整个脚本文件提交给 MyBatis 执行。例如:
// ScriptRunner类的使用
ScriptRunner scriptRunner = new ScriptRunner(connection);
scriptRunner.runScript(Resources.getResourceAsReader("demoScript.sql"));
代码便直接将demoScript.sql中的SQL脚本全部执行了。
ScriptRunner处理的是 SQL脚本,不涉及变量赋值问题,相比SqlRunner而言更为简单。ScriptRunner还提供了全脚本执行和逐行执行两种模式:
/**
* 执行脚本
* @param reader 脚本
*/
public void runScript(Reader reader) {
// 设置为自动提交
setAutoCommit();
try {
if (sendFullScript) {
// 全脚本执行
executeFullScript(reader);
} else {
// 逐行执行
executeLineByLine(reader);
}
} finally {
rollbackConnection();
}
}
/**
* 全脚本执行
* @param reader 脚本
*/
private void executeFullScript(Reader reader) {
// 脚本全文
StringBuilder script = new StringBuilder();
try {
BufferedReader lineReader = new BufferedReader(reader);
String line;
while ((line = lineReader.readLine()) != null) {
// 逐行读入脚本全文
script.append(line);
script.append(LINE_SEPARATOR);
}
// 拼接为一条命令
String command = script.toString();
println(command);
// 执行命令
executeStatement(command);
// 如果没有启用自动提交,则进行提交操作(脚本中可能修改了自动提交设置)
commitConnection();
} catch (Exception e) {
String message = "Error executing: " + script + ". Cause: " + e;
printlnError(message);
throw new RuntimeSqlException(message, e);
}
}
private void executeLineByLine(Reader reader) {
StringBuilder command = new StringBuilder();
try {
BufferedReader lineReader = new BufferedReader(reader);
String line;
// 逐行依次执行
while ((line = lineReader.readLine()) != null) {
handleLine(command, line);
}
// 提交执行
commitConnection();
// 是否存在多余的行
checkForMissingLineTerminator(command);
} catch (Exception e) {
String message = "Error executing: " + command + ". Cause: " + e;
printlnError(message);
throw new RuntimeSqlException(message, e);
}
}
1.4jdbc包的独立性
现在,我们的心头还有一个疑问:整个 jdbc包中的所有类都没有被外部引用过,那该包有什么存在的意义?
那是因为 jdbc包是 MyBatis提供的一个功能独立的工具包,留给用户自行使用而不是由 MyBatis调用。
例如,在很多场合下,用户可以选择自行拼接SQL语句,也可以选择借助 jdbc包的工具拼接SQL语句。
//自行拼接SQL语句
public String queryUsersBySchoolName() {
return " select * user where schoolName = #{schoolName}"
}
//借助 jdbc包的工具拼接SQL语句
public String queryUsersBySchoolName() {
return new SQL()
.SELECT("*")
.FROM("user")
.WHERE("schoolName = #{schoolName}")
.toString();
}
SqlRunner类和ScriptRunner类则为用户提供了执行SQL语句和脚本的能力。有些情况下,我们要对数据库进行一些设置操作(如运行一些DDL操作),这时并不需要通过MyBatis提供ORM功能,那么SqlRunner类和 ScriptRunner类将是非常好的选择。
其实,该包还有一个特点:对外界依赖极小。jdbc 包除了SqlRunner 类之外,其他类都没有依赖 jdbc包外的类。甚至RuntimeSqlException成了唯一一个没有继承 exception包中的PersistenceException类的异常类。
这种设计使得 jdbc包的独立性极高,可以方便地拆解出来使用。
在源码阅读中,大多数类的功能都可以通过项目内的依赖关系推导出来。但是也会遇到一些同 jdbc包中的类相似的一些类,它们与项目中其他类的耦合极小。这些类的功能的确定则需要我们对项目的使用有较为清晰的了解。
2.cache包
MyBatis 每秒可能要处理数万条数据库查询请求,而这些请求可能是重复的。缓存能够显著降低数据库查询次数,提升整个MyBatis的性能。
MyBatis 缓存使得每次数据库查询请求都会先经过缓存系统的过滤,只有在没有命中缓存的情况下才会去查询物理数据库。cache包就是 MyBatis缓存能力的提供者。不过要注意的是,cache包只是提供了缓存能力,不涉及具体缓存功能的使用。因此在本章的最后,我们将从缓存功能的角度出发对各个包中与缓存机制相关的源码进行阅读与汇总。
2.1 背景知识
2.1.1java对象的引用级别
在 Java程序的运行过程中,JVM会自动地帮我们进行垃圾回收操作以避免无用的对象占用内存空间。
这个过程主要分为两步:
- 找出所有的垃圾对象;
- 清理找出的垃圾对象。
我们重点关注第一步,即如何找出垃圾对象。这里的关键问题在于如何判断一个对象是否为垃圾对象。判断一个对象是否为垃圾对象的方法主要有引用计数法和可达性分析法,JVM采用的是可达性分析法。可达性分析法是指 JVM会以从垃圾回收的根对象(Garbage Collection Root,简称 GC Root)为起点,沿着对象之间的引用关系不断遍历。最终能够遍历的对象都是有用的对象,而无法遍历的对象便是垃圾对象。

上图中对象 c不再引用对象 d,则通过 GC Root便无法到达对象 d和对象 f,那么对象 d和 f便成了垃圾对象。有一点要说明,在图中我们只绘制了一个 GC Root,实际在 JVM中有多个 GC Root。当一个对象无法通过任何一个 GC Root遍历时,它才是垃圾对象。
不过上图展示的这种引用关系是有局限性的。试想存在一个非必需的大对象,我们希望系统在内存不紧张时可以保留它,而在内存紧张时释放它以为更重要的对象让渡内存空间。这时应该怎么做呢?
Java已经考虑到了这种情况,Java的引用中并不是只有“引用”“不引用”这两种情况,而是有四种情况:
- 强引用(SoftReference):即我们平时所说的引用。只要一个对象能够被 GC Root强引用到,那它就不是垃圾对象。当内存不足时,JVM 会抛出OutOfMemoryError错误而不是清除被强引用的对象。
- 软引用(SoftReference):如果一个对象只能被 GC Root软引用到,则说明它是非必需的。当内存空间不足时,JVM会回收该对象。
- 弱引用(WeakReference):如果一个对象只能被 GC Root弱引用到,则说明它是多余的。JVM只要发现它,不管内存空间是否充足都会回收该对象。与软引用相比,弱引用的引用强度更低,被弱引用的对象存在时间相对更短。
- 虚引用(PhantomReference):如果一个对象只能被 GC Root虚引用到,则和无法被GC Root引用到时一样。因此,就垃圾回收过程而言,虚引用就像不存在一样,并不会决定对象的生命周期。虚引用主要用来跟踪对象被垃圾回收器回收的活动。
private static void simpleRef() {
// 通过等号直接建立的引用都是强引用
User user = new User();
// 通过SoftReference建立的引用是软引用
SoftReference<User> softRefUser =new SoftReference<>(new User());
// 通过WeakReference建立的引用是弱引用
WeakReference<User> weakRefUser = new WeakReference<>(new User());
}
2.1.2ReferenceQueue类
如果一个对象只有软引用或者弱引用,则它随时可能会被 JVM垃圾回收掉。于是它就成了薛定谔的猫,在我们读取它之前,根本无法知道它是否还存在。
可是,有时我们需要知道被软引用或者弱引用的对象在何时被回收,以便进行一些后续的处理工作。ReferenceQueue类便提供了这样的功能。ReferenceQueue本身是一个列表,我们可以在创建软引用或者弱引用的包装对象时传入该列表。这样,当 JVM 回收被包装的对象时,会将其包装类加入 ReferenceQueue类中。
我们可以通过一个可能并不恰当的例子来理解这些概念。假设我们的目标对象是雪糕,软引用或者弱引用的包装对象就是雪糕棒。我们虽然持有了雪糕棒,但是雪糕棒上的雪糕却随时可能融化后掉在地上(也可能是被我们偷吃了,总之是没有了,相当于被 JVM销毁了)。ReferenceQueue是我们收集雪糕棒的小木桶,当我们发现某根雪糕棒上的雪糕消失时,就会把雪糕棒放到小木桶中。这样一来,我们只要观察小木桶,就能知道哪些雪糕已经消失了。
public class User {
private long id;
public User() {
}
public User(long id) {
this.id = id;
}
@Override
public String toString() {
return "User:" + id;
}
}
private static void refWithReferenceQueue() {
// 创建ReferenceQueue
// 即我们的小木桶
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
// 用来存储弱引用的目标对象
// 即我们用来抓带有雪糕的雪糕棒的手
List<WeakReference> weakRefUserList = new ArrayList<>();
// 创建大量的弱引用对象,交给weakRefUserList引用
// 即创建许多带有雪糕的雪糕棒,并且拿到手里
for (int i =0 ; i< 1000000; i++) {
// 创建这么多的目的是为了让内存空间紧张
// 创建弱引用对象,并在此过程中传入ReferenceQueue
// 即将雪糕放到雪糕棒上,并且确定用来收集雪糕棒的小木桶
WeakReference<User> weakReference = new WeakReference(new User(Math.round(Math.random() * 1000)),referenceQueue);
// 引用弱引用对象
// 即抓起这个带有雪糕的雪糕棒
weakRefUserList.add(weakReference);
}
WeakReference weakReference;
Integer count = 0;
// 处理被回收的弱引用
// 即通过检查小木桶,处理没有了雪糕的雪糕棒
while ((weakReference = (WeakReference) referenceQueue.poll()) != null) {
// 虽然弱引用存在,但是引用的目标对象已经为空
// 即虽然雪糕棒在木桶中,但是雪糕棒上却没有了雪糕
System.out.println("JVM 清理了:" + weakReference + ", 从WeakReference中取出对象值为:" + weakReference.get());
count ++;
}
// 被回收的弱引用总数
// 即小木桶中雪糕棒的数目,也是融化的雪糕的数目
System.out.println("weakReference中的元素数目为:" + count);
// 在弱引用的目标对象不被清理时,可以引用到目标对象
// 即在雪糕还没有融化掉到地上时,雪糕棒上是有雪糕的
System.out.println("在不被清理的情况下,可以从WeakReference中取出对象值为:" +
new WeakReference(new User(Math.round(Math.random() * 1000)),referenceQueue).get());
}
/*
JVM 清理了:java.lang.ref.WeakReference@4b1d273a, 从WeakReference中取出对象值为:null
JVM 清理了:java.lang.ref.WeakReference@6d26e756, 从WeakReference中取出对象值为:null
JVM 清理了:java.lang.ref.WeakReference@1015009f, 从WeakReference中取出对象值为:null
weakReference中的元素数目为:230759
在不被清理的情况下,可以从WeakReference中取出对象值为:User:561
*/
被清理的 User对象(相当于雪糕)的包装对象 WeakReference(相当于雪糕棒)都被写入了ReferenceQueue(相当于小木桶)中,也正因为它们包装的 User对象已经被清理,因此从 ReferenceQueue取出的结果必定是 null。
2.2 cache包结构与Cache接口
cache包是典型的装饰器模式应用案例,在 imple子包中存放了实现类,在decorators子包中存放了众多装饰器类。而 Cache接口是实现类和装饰器类的共同接口。
在 Cache接口的子类中,只有一个实现类,但却有十个装饰器类。通过使用不同的装饰器装饰实现类可以让实现类有着不同的功能。

public interface Cache {
/**
* 获取缓存id
* @return 缓存id
*/
String getId();
/**
* 向缓存写入一条信息
* @param key 信息的键
* @param value 信息的值
*/
void putObject(Object key, Object value);
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
Object getObject(Object key);
/**
* 从缓存中删除一条信息
* @param key 信息的键
* @return 原来的信息值
*/
Object removeObject(Object key);
/**
* 清空缓存
*/
void clear();
/**
* 读取缓存中信息的数目
* @return 信息的数目
*/
int getSize();
/**
* 获取读写锁,该方法已经废弃
* @return 读写锁
*/
default ReadWriteLock getReadWriteLock() {
return null;
}
2.3 缓存键
2.3.1 缓存键的原理
MyBatis 每秒过滤众多数据库查询操作,这对 MyBatis 缓存键的设计提出了很高的要求。MyBatis缓存键要满足以下几点。
- 无碰撞:必须保证两条不同的查询请求生成的键不一致,这是最重要也是必须满足的要求。否则会引发查询操作命中错误的缓存,并返回错误的结果。
- 高效比较:每次缓存查询操作都可能会引发键之间的多次比较,因此该操作必须是高效的。
- 高效生成:每次缓存查询和写入操作前都需要生成缓存的键,因此该操作也必须是高效的。
在编程中,我们常使用数值、字符串等简单类型作为键,然而,这类键容易产生碰撞。为了防止碰撞的发生,需要将键的生成机制设计得非常复杂,这又降低了键的比较效率和生成效率。因此,准确度和效率之间往往是相互制约的。
为了解决以上问题,MyBatis设计了一个 CacheKey类作为缓存键。整个CacheKey设计得并不复杂,但又非常精巧。
// 乘数,用来计算hashcode时使用
private final int multiplier;
// 哈希值,整个CacheKey的哈希值。如果两个CacheKey该值不同,则两个CacheKey一定不同
private int hashcode;
// 求和校验值,整个CacheKey的求和校验值。如果两个CacheKey该值不同,则两个CacheKey一定不同
private long checksum;
// 更新次数,整个CacheKey的更新次数
private int count;
// 更新历史
private List<Object> updateList;
/**
* 更新CacheKey
* @param object 此次更新的参数
*/
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
update 方法了解以上几个属性的作用。每一次update操作都会引发 count、checksum、hashcode值的变化,并把更新值放入updateList。
在比较 CacheKey对象是否相等时,会先进行类型判断,然后进行 hashcode、checksum、count的比较,只要有一项不相同则表明两个对象不同。以上操作都比较简单,能在很短的时间内完成。如果上面的各项属性完全一致,则会详细比较两个 CacheKey 对象的变动历史 updateList,这一步操作相对复杂,但是能保证绝对不会出现碰撞问题。
/**
* 比较当前对象和入参对象(通常也是CacheKey对象)是否相等
* @param object 入参对象
* @return 是否相等
*/
@Override
public boolean equals(Object object) {
// 如果地址一样,是一个对象,肯定相等
if (this == object) {
return true;
}
// 如果入参不是CacheKey对象,肯定不相等
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
// 依次通过hashcode、checksum、count判断。必须完全一致才相等
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
// 详细比较变更历史中的每次变更
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
这样,通过 count、checksum、hashcode这三个值实现了快速比较,而通过updateList值又确保了不会发生碰撞。这种设计较好地在准确度和效率之间取得了平衡。
MyBatis 还准备了一个 NullCacheKey,该类用来充当一个空键使用。在缓存查询中,如果发现某个 CacheKey信息不全,则会返回 NullCacheKey对象,类似于返回一个 null值。但是 NullCacheKey毕竟是 CacheKey的子类,在接下来的处理中不会引发空指针异常。这种设计方式也非常值得我们借鉴。
2.3.2 缓存的实现类
impl子包中 Cache接口的实现类是 PerpetualCache。PerpetualCache的实现非常简单只有两个属性:
- id:用来唯一标识一个缓存。一般使用映射文件的 namespace值作为缓存的id,这样就能保证不同的映射文件的缓存是不同的。
- cache:是一个 HashMap,采用键值对的形式来存储数据。
// Cache的id,一般为所在的namespace
private final String id;
// 用来存储要缓存的信息
private Map<Object, Object> cache = new HashMap<>();
所以缓存的实现类就是一个附带 id的 HashMap,并没有什么特别之处。
2.3.3 缓存装饰器
缓存实现类 PerpetualCache的实现非常简单,但可以通过装饰器来为其增加更多的功能。decorators子包中存在许多装饰器,根据装饰器的功能可以将它们分为以下几个大类:
- 同步装饰器:为缓存增加同步功能,如 SynchronizedCache类。
- 日志装饰器:为缓存增加日志功能,如 LoggingCache类。
- 清理装饰器:为缓存中的数据增加清理功能,如 FifoCache 类、LruCache 类、WeakCache类、SoftCache类。
- 阻塞装饰器:为缓存增加阻塞功能,如 BlockingCache类。
- 定时清理装饰器:为缓存增加定时刷新功能,如 ScheduledCache类。
- 序列化装饰器:为缓存增加序列化功能,如 SerializedCache类。
- 事务装饰器:用于支持事务操作的装饰器,如 TransactionalCache类。
2.3.3.1 同步装饰器
在使用 MyBatis的过程中,可能会出现多个线程同时访问一个缓存的情况。例如,在下面代码的映射文件中,如果多个线程同时调用 selectUsers方法,则这两个线程会同时访问 id为“com.github.yeecode.mybatisdemo.dao.UserDao”的这个缓存。
<mapper namespace="com.github.yeecode.mybatisdemo.dao.UserDao">
<select id="selectUser" resultMap="userMapByConstructor">
SELECT * FROM `user` WHERE `id` = #{id}
</select>
</mapper>
而缓存实现类 PerpetualCache 并没有增加任何保证多线程安全的措施,这会引发多线程安全问题。
MyBatis 将保证缓存多线程安全这项工作交给了 SynchronizedCache 装饰器来完成。SynchronizedCache 装饰器的实现非常简单,它直接在被包装对象的操作方法外围增加了synchronized关键字,将被包装对象的方法转变为了同步方法。
2.3.3.2 日志装饰器
为数据库操作增加缓存的目的是减少数据库的查询操作从而提高运行效率。而缓存的配置也非常重要,如果配置过大则浪费内存空间,如果配置过小则无法更好地发挥作用。因此,需要依据一些运行指标来设置合适的缓存大小。
日志装饰器可以为缓存增加日志统计的功能,而需要统计的数据主要是缓存命中率。所谓缓存命中率是指在多次访问缓存的过程中,能够在缓存中查询到数据的比率。
日志装饰器的实现非常简单,即在缓存查询时记录查询的总次数与命中次数。
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
@Override
public Object getObject(Object key) {
// 请求缓存次数+1
requests++;
final Object value = delegate.getObject(key);
if (value != null) {
// 命中缓存
// 命中缓存次数+1
hits++;
}
if (log.isDebugEnabled()) {
log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio());
}
return value;
}
2.3.3.3 清理装饰器
虽然缓存能够极大地提升数据查询的效率,但这是以消耗内存空间为代价的。缓存空间总是有限的,因此为缓存增加合适的清理策略以最大化地利用这些缓存空间十分重要。缓存装饰器中有四种清理装饰器可以完成缓存清理功能,这四种清理装饰器也对应了MyBatis的四种缓存清理策略。
- FifoCache装饰器
FifoCache装饰器采用先进先出的策略来清理缓存,它内部使用了 keyList属性存储了缓存数据的写入顺序,并且使用 size属性存储了缓存数据的数量限制。当缓存中的数据达到限制时,FifoCache装饰器会将最先放入缓存中的数据删除。
// 被装饰对象
private final Cache delegate;
// 按照写入顺序保存了缓存数据的键
private final Deque<Object> keyList;
// 缓存空间的大小
private int size;
/**
* 向缓存写入一条数据
* @param key 数据的键
* @param value 数据的值
*/
@Override
public void putObject(Object key, Object value) {
cycleKeyList(key);
delegate.putObject(key, value);
}
/**
* 记录当前放入的数据的键,同时根据空间设置清除超出的数据
* @param key 当前放入的数据的键
*/
private void cycleKeyList(Object key) {
keyList.addLast(key);
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}
- LruCache装饰器
LRU(Least Recently Used)即近期最少使用算法,该算法会在缓存数据数量达到设置的上限时将近期未使用的数据删除。LruCache 装饰器便可以为缓存增加这些功能。
// 被装饰对象
private final Cache delegate;
// 使用LinkedHashMap保存的缓存数据的键
private Map<Object, Object> keyMap;
// 最近最少使用的数据的键
private Object eldestKey;
/**
* LruCache构造方法
* @param delegate 被装饰对象
*/
public LruCache(Cache delegate) {
this.delegate = delegate;
setSize(1024);
}
/**
* 设置缓存空间大小
* @param size 缓存空间大小
*/
public void setSize(final int size) {
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
/**
* 每次向LinkedHashMap放入数据时触发
* @param eldest 最久未被访问的数据
* @return 最久未必访问的元素是否应该被删除
*/
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
在 LruCache类的构造方法中,会调用 setSize方法来设置缓存的空间大小。在setSize方法中创建了用以存储缓存数据键的 LinkedHashMap 对象,并重写了LinkedHashMap 的removeEldestEntry方法。
removeEldestEntry是 LinkedHashMap的方法,该方法会在每次向LinkedHashMap中放入数据(put方法和 putAll方法)后被自动触发。其输入参数为最久未访问的元素。LruCache 会在超出缓存空间的情况下将最久未访问的键放入eldestKey属性中。
为了删除最久未使用的数据,LruCache类还做了以下两项工作。
- 在每次进行缓存查询操作时更新 keyMap中键的排序,将当前被查询的键排到最前面;
- 是在每次进行缓存写入操作时向 keyMap写入新的键,并且在当前缓存中数据量超过设置的数据量时删除最久未访问的数据。
/**
* 向缓存写入一条信息
* @param key 信息的键
* @param value 信息的值
*/
@Override
public void putObject(Object key, Object value) {
// 真正的查询操作
delegate.putObject(key, value);
// 向keyMap中也放入该键,并根据空间情况决定是否要删除最久未访问的数据
cycleKeyList(key);
}
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
@Override
public Object getObject(Object key) {
// 触及一下当前被访问的键,表明它被访问了
keyMap.get(key);
// 真正的查询操作
return delegate.getObject(key);
}
/**
* 向keyMap中存入当前的键,并删除最久未被访问的数据
* @param key 当前的键
*/
private void cycleKeyList(Object key) {
keyMap.put(key, key);
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
真正的缓存数据都存储在被装饰对象中。LruCache类中的keyMap虽是一个 LinkedHashMap,但是它内部存储的键和值都是缓存数据的键,而没有存储缓存数据的值。这是因为引入 LinkedHashMap的目的仅仅是用它来保存缓存数据被访问的情况,而不是参与具体数据的保存。
- WeakCache装饰器
WeakCache装饰器通过将缓存数据包装成弱引用的数据,从而使得JVM可以清理掉缓存数据。
// 强引用的对象列表
private final Deque<Object> hardLinksToAvoidGarbageCollection;
// 弱引用的对象列表
private final ReferenceQueue<Object> queueOfGarbageCollectedEntries;
// 被装饰对象
private final Cache delegate;
// 强引用对象的数目限制
private int numberOfHardLinks;
WeakCache类也准备了一个hardLinksToAvoidGarbageCollection属性来对缓存对象进行强引用,只不过该属性提供的空间是有限的。经过 WeakCache 类包装后,在向缓存中存入数据时,存入的是该数据的弱引用包装类。
/**
* 向缓存写入一条信息
* @param key 信息的键
* @param value 信息的值
*/
@Override
public void putObject(Object key, Object value) {
// 清除垃圾回收队列中的元素
removeGarbageCollectedItems();
// 向被装饰对象中放入的值是弱引用的句柄
delegate.putObject(key, new WeakEntry(key, value, queueOfGarbageCollectedEntries));
}
而从缓存中取出数据时,取出的也是数据的弱引用包装类。数据本身可能已经被 JVM清理掉了,因此在取出数据时要对这种情况进行判断。
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
@Override
public Object getObject(Object key) {
Object result = null;
// 假定被装饰对象只被该装饰器完全控制
WeakReference<Object> weakReference = (WeakReference<Object>) delegate.getObject(key);
if (weakReference != null) {
// 取到了弱引用的句柄
// 读取弱引用的对象
result = weakReference.get();
if (result == null) {
// 弱引用的对象已经被清理
// 直接删除该缓存
delegate.removeObject(key);
} else {
// 弱引用的对象还存在
// 将缓存的信息写入到强引用列表中,防止其被清理
hardLinksToAvoidGarbageCollection.addFirst(result);
if (hardLinksToAvoidGarbageCollection.size() > numberOfHardLinks) {
// 强引用的对象数目超出限制
// 从强引用的列表中删除该数据
hardLinksToAvoidGarbageCollection.removeLast();
}
}
}
return result;
}
缓存中存储的数据是“数据键:数据值”的形式,而经过WeakCache包装后,缓存中存储的数据是“数据键:弱引用包装<数据值>”的形式。那么当弱引用的数据值被 JVM回收后,缓存中的数据会变成“数据键:弱引用包装<null>”的形式。
如果缓存数据值被JVM回收了,则整个缓存数据“数据键:弱引用包装<null>”也便没有了意义,应该直接清理掉。
为此,WeakCache设计了 WeakEntry内部类。WeakEntry类作为弱引用包装类直接增加了 key属性并在其中保存了数据的键,而这个属性是强引用的,不会被 JVM随意清理掉。
private static class WeakEntry extends WeakReference<Object> {
// 该变量不会被JVM清理掉,这里存储了目标对象的键
private final Object key;
private WeakEntry(Object key, Object value, ReferenceQueue<Object> garbageCollectionQueue) {
super(value, garbageCollectionQueue);
this.key = key;
}
}
- SoftCache装饰器
SoftCache 装饰器和 WeakCache 装饰器在结构、功能上高度一致,只是从弱引用变成了软引用。
2.3.3.4 阻塞装饰器
当 MyBatis 接收到一条数据库查询请求,而对应的查询结果在缓存中不存在时,MyBatis会通过数据库进行查询。试想如果在数据库查询尚未结束时,MyBatis又收到一条完全相同的数据库查询请求,那应该怎样处理呢?常见的有以下两种方案。
- 因为缓存中没有对应的缓存结果,因此再发起一条数据库查询请求,这会导致数据库短时间内收到两条完全相同的查询请求。
- 虽然缓存中没有对应的缓存结果,但是已经向数据库发起过一次请求,因此缓存应该先阻塞住第二次查询请求。等待数据库查询结束后,将数据库的查询结果返回给两次查询请求即可。
显然,后一种方案更为合理。
阻塞装饰器 BlockingCache 为缓存提供了上述功能。在使用阻塞装饰器装饰缓存后,缓存在收到多条相同的查询请求时会暂时阻塞住后面的查询,等待数据库结果返回时将所有的请求一并返回。
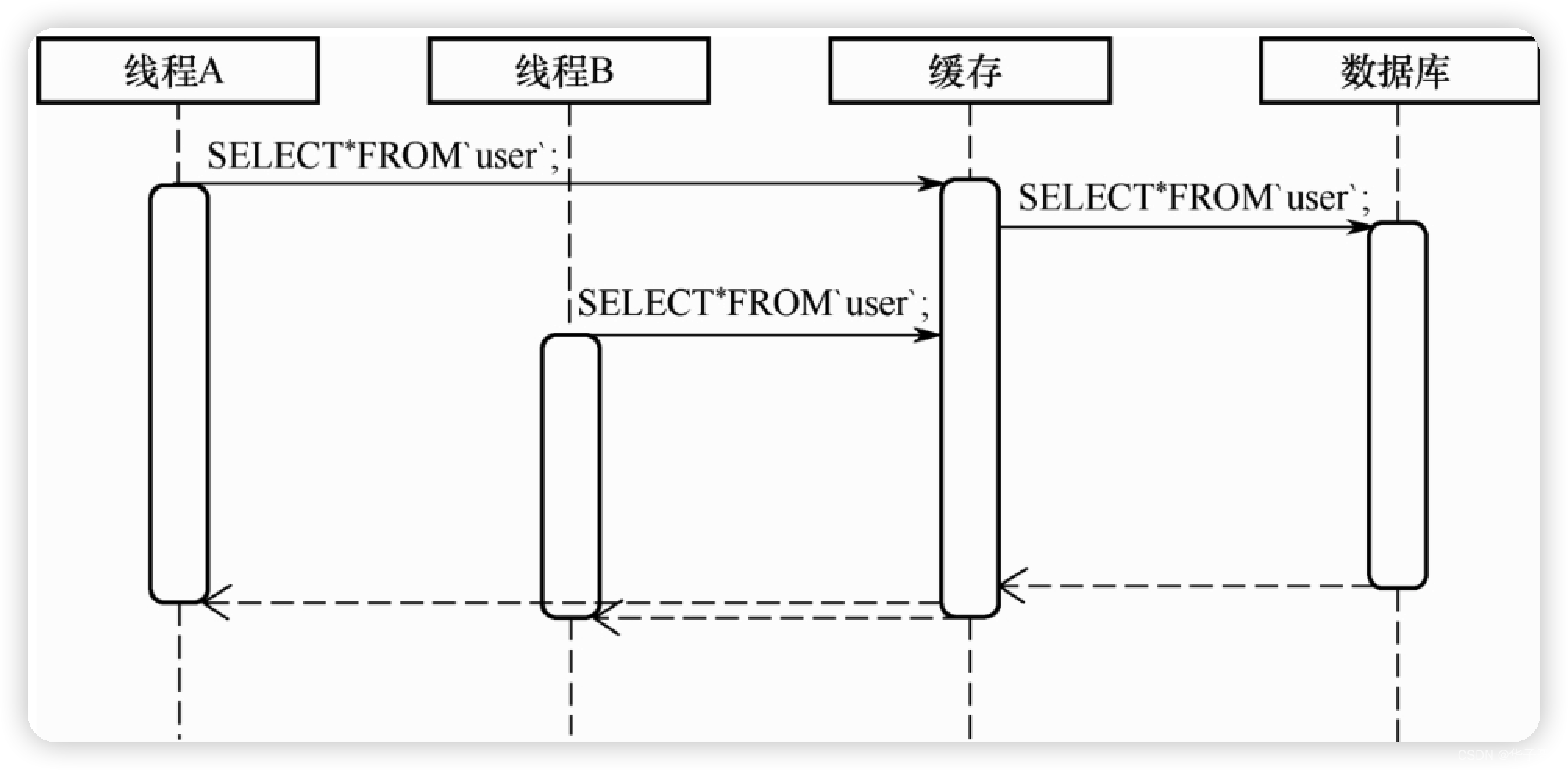
BlockingCache类的属性。其中在 locks属性中用 ConcurrentHashMap存储了所有缓存的键与对应的锁,这样,只有当取得对应的锁后才能进行相应数据的查询操作,否则就会被阻塞。
// 获取锁时的运行等待时间
private long timeout;
// 被装饰对象
private final Cache delegate;
// 锁的映射表。键为缓存记录的键,值为对应的锁。
private final ConcurrentHashMap<Object, ReentrantLock> locks;
下面代码展示了与锁的获取和释放相关的方法。要注意的是,每一条记录的键都有一个对应的锁,所以阻塞装饰器锁住的不是整个缓存,而是缓存中的某条记录。
/**
* 找出指定键的锁
* @param key 指定的键
* @return 该键对应的锁
*/
private ReentrantLock getLockForKey(Object key) {
return locks.computeIfAbsent(key, k -> new ReentrantLock());
}
/**
* 获取某个键的锁
* @param key 数据的键
*/
private void acquireLock(Object key) {
// 找出指定对象的锁
Lock lock = getLockForKey(key);
if (timeout > 0) {
try {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
// 锁住
lock.lock();
}
}
/**
* 向缓存写入一条信息
* @param key 信息的键
* @param value 信息的值
*/
@Override
public void putObject(Object key, Object value) {
try {
// 向缓存中放入数据
delegate.putObject(key, value);
} finally {
// 因为已经放入了数据,因此释放锁
releaseLock(key);
}
}
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
@Override
public Object getObject(Object key) {
// 获取锁
acquireLock(key);
// 读取结果
Object value = delegate.getObject(key);
if (value != null) {
// 读取到结果后释放锁
releaseLock(key);
}
// 如果缓存中没有读到结果,则不会释放锁。对应的锁会在从数据库读取了结果并写入到缓存后,在putObject中释放。
// 返回查询到的缓存结果
return value;
}
BlockingCache中的缓存数据读写方法。在读取缓存中的数据前需要获取该数据对应的锁,如果从缓存中读取到了对应的数据,则立刻释放该锁;如果从缓存中没有读取到对应的数据,则意味着接下来会进行数据库查询,直到数据库查询结束向缓存中写入该数据时,才会释放该数据的锁。
2.3.3.5 定时清理装饰器
当调用缓存的 clear方法时,会清理缓存中的数据。但是该操作不会自动执行。定时清理装饰器 ScheduledCache则可以按照一定的时间间隔来清理缓存中的数据,即按照一定的时间间隔调用 clear方法。
// 被装饰的对象
private final Cache delegate;
// 清理的时间间隔
protected long clearInterval;
// 上次清理的时刻
protected long lastClear;
/**
* 根据清理时间间隔设置清理缓存
* @return 是否发生了缓存清理
*/
private boolean clearWhenStale() {
if (System.currentTimeMillis() - lastClear > clearInterval) {
clear();
return true;
}
return false;
}
ScheduledCache类的清理方法clearWhenStale,该方法会在getSize、putObject、getObject、removeObject中被调用。
我们要知道,ScheduledCache 提供的定时清理功能并非是实时的。也就是说,即使已经满足了清理时间间隔的要求,只要getSize、putObject、getObject、removeObject 这四个方法没有被调用,则 clearWhenStale方法也不会被触发,也就不会发生缓存清理操作。
这种非实时的设计方式也是值得参考的,因为实时操作需要增加单独的计时线程,会消耗大量的资源;而这种非实时的方式节约了资源,但同时也不会造成太大的误差。
2.3.3.6 序列化装饰器
我们知道,对象(也就是数据)放入缓存后,如果被多次读取出来,则多次读取的是同一个对象的引用。也就是说,缓存中的对象是在多个引用之间共享的。这意味着,如果读取后修改了该对象的属性,会直接导致缓存中的对象也发生变化。
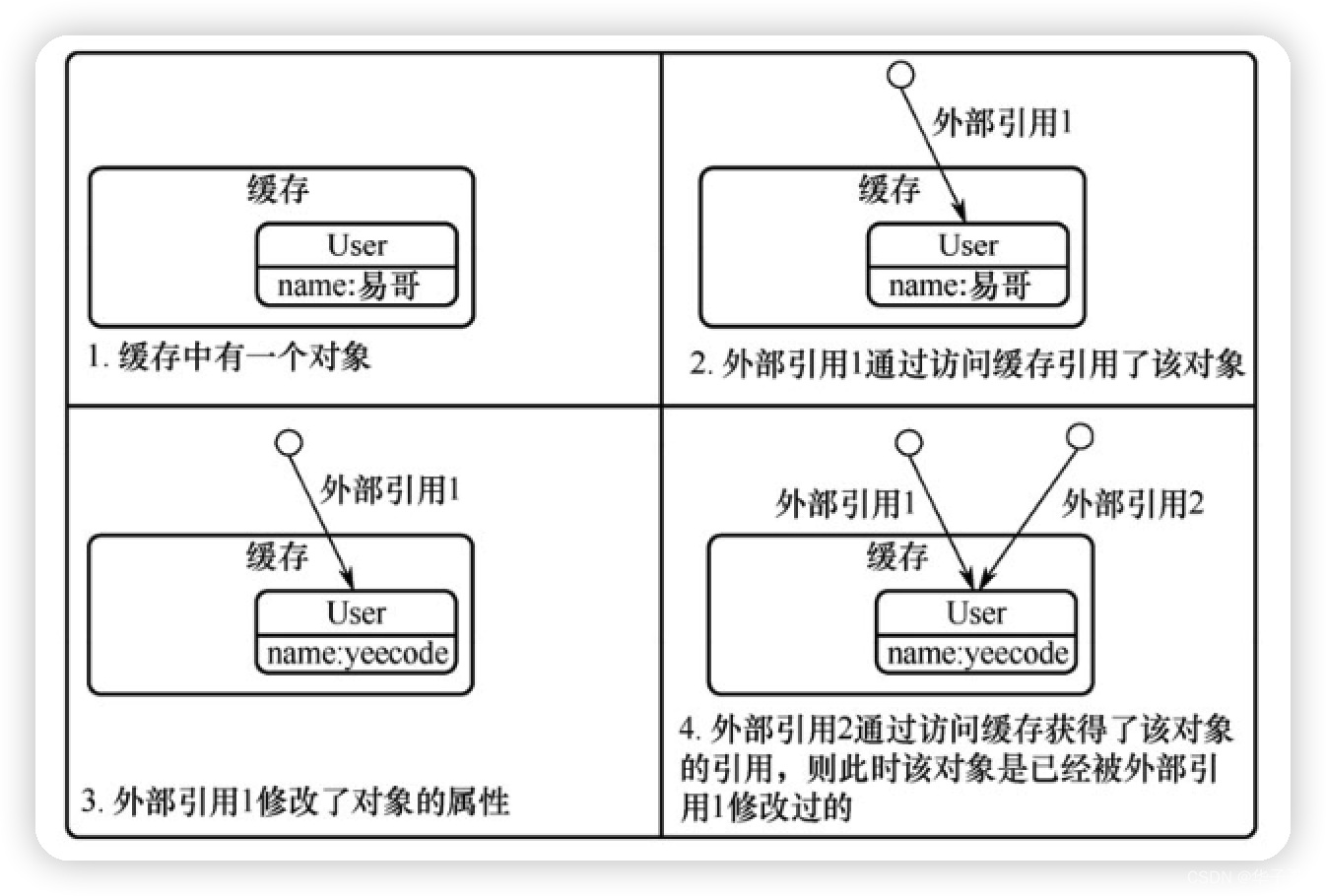
有些场景下,我们不想让外部的引用污染缓存中的对象。这时必须保证外部读取缓存中的对象时,每次读取的都是一个全新的拷贝而不是引用。序列化装饰器 SerializedCache为缓存增加了这一功能。
在使用 SerializedCache后,每次向缓存中写入对象时,实际写入的是对象的序列化串;而每次读取对象时,会将序列化串反序列化后再返回。通过序列化和反序列化的过程保证了每一次缓存给出的对象都是一个全新的对象,对该对象的修改不会影响缓存中的对象。当然,这要求被缓存的数据必须是可序列化的,否则 SerializedCache会抛出异常。
/**
* 向缓存写入一条信息
* @param key 信息的键
* @param object 信息的值
*/
@Override
public void putObject(Object key, Object object) {
if (object == null || object instanceof Serializable) {
// 要缓存的数据必须是可以序列化的
// 将数据序列化后写入缓存
delegate.putObject(key, serialize((Serializable) object));
} else {
// 要缓存的数据不可序列化
// 抛出异常
throw new CacheException("SharedCache failed to make a copy of a non-serializable object: " + object);
}
}
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
@Override
public Object getObject(Object key) {
// 读取缓存中的序列化串
Object object = delegate.getObject(key);
// 反序列化后返回
return object == null ? null : deserialize((byte[]) object);
}
2.4 缓存的组建
组建缓存的过程就是根据需求为缓存的基本实现增加各种装饰的过程,该过程在CacheBuilder中完成。下面通过CacheBuilder的源码了解 MyBatis如何组建缓存。
组建缓存的入口方法是 CacheBuilder中的 build方法:
/**
* 组建缓存
* @return 缓存对象
*/
public Cache build() {
// 设置缓存的默认实现、默认装饰器(仅设置,并未装配)
setDefaultImplementations();
// 创建默认的缓存
Cache cache = newBaseCacheInstance(implementation, id);
// 设置缓存的属性
setCacheProperties(cache);
if (PerpetualCache.class.equals(cache.getClass())) {
// 缓存实现是PerpetualCache,即不是用户自定义的缓存实现
// 为缓存逐级嵌套自定义的装饰器
for (Class<? extends Cache> decorator : decorators) {
// 生成装饰器实例,并装配。入参依次是装饰器类、被装饰的缓存
cache = newCacheDecoratorInstance(decorator, cache);
// 为装饰器设置属性
setCacheProperties(cache);
}
// 为缓存增加标准的装饰器
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
// 增加日志装饰器
cache = new LoggingCache(cache);
}
// 返回被包装好的缓存
return cache;
}
/**
* 设置缓存的默认实现和默认装饰器
*/
private void setDefaultImplementations() {
if (implementation == null) {
implementation = PerpetualCache.class;
if (decorators.isEmpty()) {
decorators.add(LruCache.class);
}
}
}
其中的setDefaultImplementations子方法负责设置缓存的默认实现和默认装饰器。可以看出在外部没有指定实现类的情况下,缓存默认的实现类是PerpetualCache 类,默认的清理装饰器是 LruCache。要注意的是,该方法只是把默认的实现类放入了 implementation属性,把 LruCache放入了 decorators属性,并没有实际生产和装配缓存。
接下来会通过 newBaseCacheInstance方法生成缓存的实现,并逐级包装用户自定义的装饰器。最后还会通过setStandardDecorators方法为缓存增加标准的装饰器。在映射文件中,我们可以通过指定缓存的特性。
<cache type="PERPETUAL"
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"
blocking="true">
<property name="timeout" value="20"/> <!--可以加入property节点,将用来直接修改Cache对象的属性-->
</cache>
setStandardDecorators方法设置的缓存特性来确定对缓存增加哪些装饰器的。
/**
* 为缓存增加标准的装饰器
* @param cache 被装饰的缓存
* @return 装饰结束的缓存
*/
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
// 设置缓存大小
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
// 如果定义了清理间隔,则使用定时清理装饰器装饰缓存
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
// 如果允许读写,则使用序列化装饰器装饰缓存
if (readWrite) {
cache = new SerializedCache(cache);
}
// 使用日志装饰器装饰缓存
cache = new LoggingCache(cache);
// 使用同步装饰器装饰缓存
cache = new SynchronizedCache(cache);
// 如果启用了阻塞功能,则使用阻塞装饰器装饰缓存
if (blocking) {
cache = new BlockingCache(cache);
}
// 返回被层层装饰的缓存
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
} /**
* 为缓存增加标准的装饰器
* @param cache 被装饰的缓存
* @return 装饰结束的缓存
*/
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
// 设置缓存大小
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
// 如果定义了清理间隔,则使用定时清理装饰器装饰缓存
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
// 如果允许读写,则使用序列化装饰器装饰缓存
if (readWrite) {
cache = new SerializedCache(cache);
}
// 使用日志装饰器装饰缓存
cache = new LoggingCache(cache);
// 使用同步装饰器装饰缓存
cache = new SynchronizedCache(cache);
// 如果启用了阻塞功能,则使用阻塞装饰器装饰缓存
if (blocking) {
cache = new BlockingCache(cache);
}
// 返回被层层装饰的缓存
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
通过阅读 CacheBuilder类的源码,我们知道为缓存增加功能的过程就是增加装饰器的过程。同时,也能感受到装饰器模式的强大与灵活。
2.5 事务缓存
在数据库操作中,如果没有显式地声明事务,则一条语句本身就是一个事务。在查询语句进行数据库查询操作之后,相应的查询结果可以立刻放入缓存中备用。
那么,事务中的语句进行数据库查询操作之后,相应的查询结果可以立刻放入缓存备用吗?
显然不可以。例如下面所示的事务操作中,SELECT 操作得到的查询结果中其实包含了前面 INSERT语句插入的信息。如果 SELECT查询结束后立刻将查询结果放入缓存,则在事务提交前缓存中就包含了事务中的信息,这是违背事务定义的。而如果之后该事务进行了回滚,则缓存中的数据就会和数据库中的数据不一致。
start transaction ;
insert into `user`(`name`,`email`,`age`,`sex`) values (`hzg`,`[email protected]`,`18`,`男`);
select * from `user`;
commit;
因此,事务操作中产生的数据需要在事务提交时写入缓存,而在事务回滚时直接销毁。TransactionalCache装饰器就为缓存提供了这一功能。
TransactionalCache类的属性entriesToAddOnCommit属性将事务中产生的数据暂时保存起来,在事务提交时一并提交给缓存,而在事务回滚时直接销毁。TransactionalCache类也支持将缓存的范围限制在事务以内,只要将 clearOnCommit属性置为 true即可。这样,只要事务结束,就会直接将暂时保存的数据销毁掉,而不是写入缓存中。
// 被装饰的对象
private final Cache delegate;
// 事务提交后是否直接清理缓存
private boolean clearOnCommit;
// 事务提交时需要写入缓存的数据
private final Map<Object, Object> entriesToAddOnCommit;
// 缓存查询未命中的数据
private final Set<Object> entriesMissedInCache;
TransactionalCache类中的缓存读取和写入操作。可见读取缓存时是真正从缓存中读取,而写入缓存时却只是暂存在 TransactionalCache对象内部。
/**
* 从缓存中读取一条信息
* @param key 信息的键
* @return 信息的值
*/
@Override
public Object getObject(Object key) {
// 从缓存中读取对应的数据
Object object = delegate.getObject(key);
if (object == null) {
// 缓存未命中
// 记录该缓存未命中
entriesMissedInCache.add(key);
}
if (clearOnCommit) {
// 如果设置了提交时立马清除,则直接返回null
return null;
} else {
// 返回查询的结果
return object;
}
}
而在事务进行提交或回滚时,TransactionalCache会根据设置将自身保存的数据写入缓存或者直接销毁。
/**
* 提交事务
*/
public void commit() {
if (clearOnCommit) {
// 如果设置了事务提交后清理缓存
// 清理缓存
delegate.clear();
}
// 将为写入缓存的操作写入缓存
flushPendingEntries();
// 清理环境
reset();
}
/**
* 回滚事务
*/
public void rollback() {
// 删除缓存未命中的数据
unlockMissedEntries();
reset();
}
至此,对事务缓存 TransactionalCache,尤其是其中用来暂存事务内数据的entriesToAddOnCommit属性有了清晰的认识。然而,entriesMissedInCache属性的作用是什么?为什么要在其中保存查询缓存未命中的数据?
这就要结合阻塞装饰器 BlockingCache 来思考了。事务缓存中使用的缓存可能是被BlockingCache装饰过的,这意味着,如果缓存查询得到的结果为 null,会导致对该数据上锁,从而阻塞后续对该数据的查询。而事务提交或者回滚后,应该对缓存中的这些数据全部解锁才对。entriesMissedInCache就保存了这些数据的键,在事务结束时对这些数据进行解锁。
在一个事务中,可能会涉及多个缓存。TransactionalCacheManager 就是用来管理一个事务中的多个缓存的,其中的 transactionalCaches属性中保存了多个缓存和对应的经过缓存装饰器装饰后的缓存。
// 管理多个缓存的映射
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
/**
* 事务提交
*/
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
/**
* 事务回滚
*/
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
TransactionalCacheManager 会在事务提交和回滚时触发所有相关事务缓存的提交和回滚
2.6 MyBatis缓存机制
在进行源码阅读时,通常可以以包为单位进行,因为包本身就是具有一定结构、功能的类的集合。但是,也总会有一些功能相对复杂,会横跨多个包。因此,以功能为主线一次阅读多个包中的源码也是必要的,它能帮助我们厘清一个功能实现的前因后果。
这一次,我们将横跨多个包,详细了解 MyBatis的缓存机制。
前面已经详细介绍了 cache包的全部源码,了解了 MyBatis如何使用不同的装饰器装饰以得到不同功能的缓存。但是,cache包中却没有涉及缓存的具体使用。
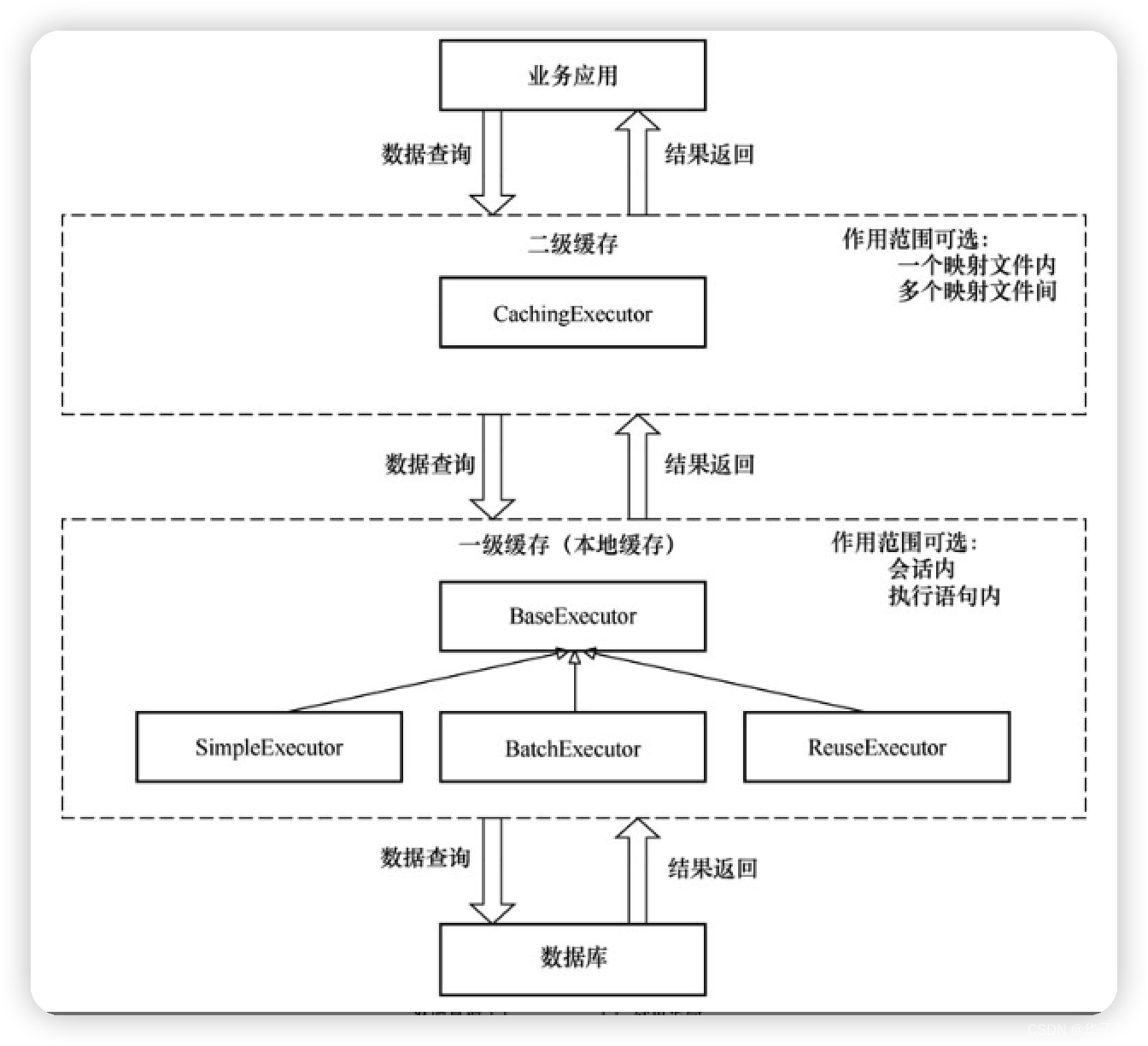
在 executor包中,MyBatis基于 cache包中提供的缓存实现了两级缓存。接下来我们将详细了解 MyBatis的缓存机制。在介绍 MyBatis的缓存机制之前,先提前了解 Executor接口的概况。
Executor 接口是执行器接口,它负责进行数据库查询等操作。它有两个直接子类,CachingExecutor类和 BaseExecutor类。
- CachingExecutor是一个装饰器类,它能够为执行器实现类增加缓存功能。
- BaseExecutor类是所有实际执行器类的基类,它有SimpleExecutor、BatchExecutor、ReuseExecutor、ClosedExecutor 四个子类。而其中的ClosedExecutor子类本身没有实际功能,我们暂时忽略它。
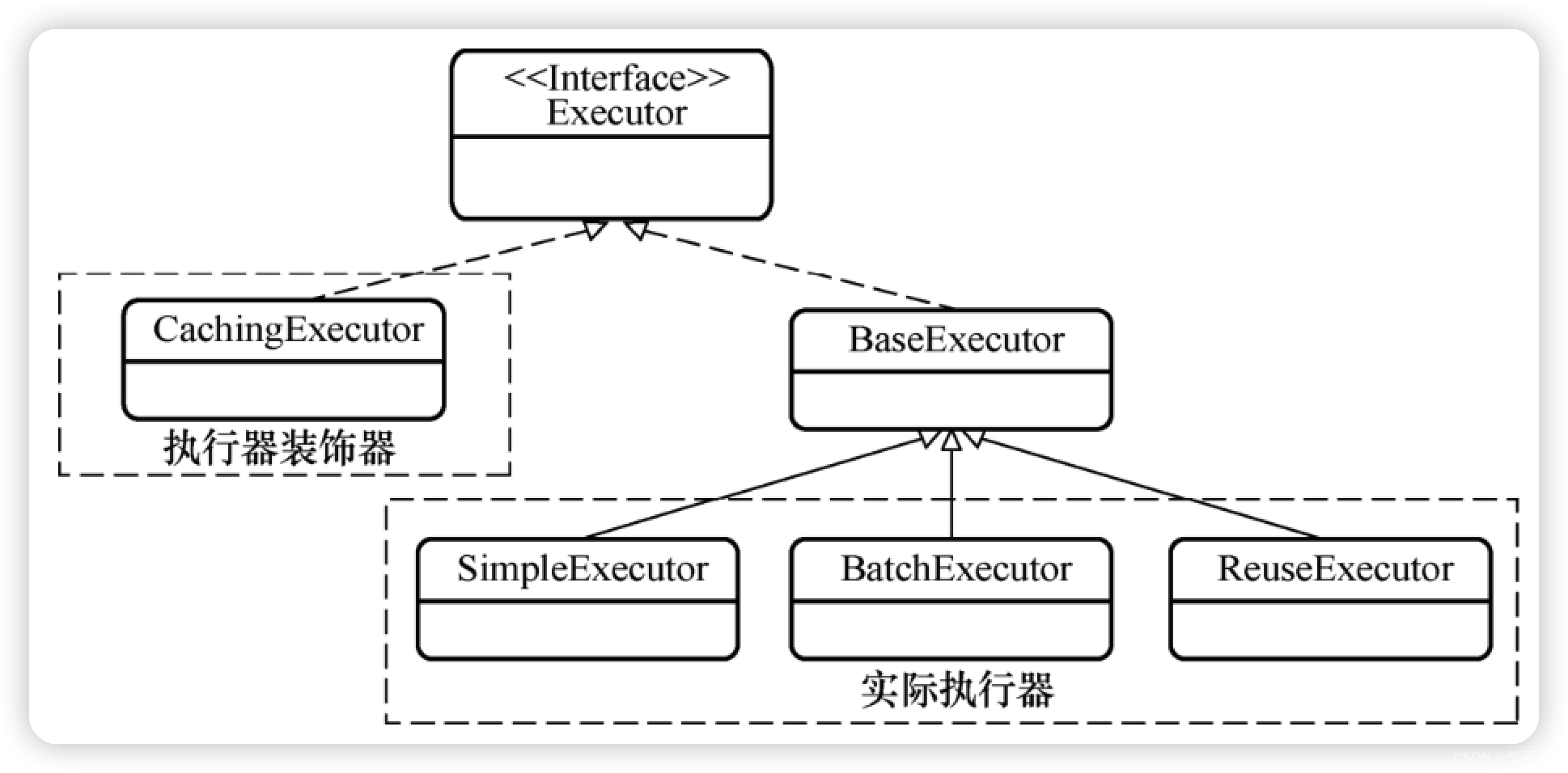
2.6.1 一级缓存
MyBatis 的一级缓存又叫本地缓存,其结构和使用都比较简单,与它相关的配置项有两个。一个是在配置文件的 settings节点下,我们可以增加以下的配置语句来改变一级缓存的作用范围。配置值的可选项有 SESSION与 STATEMENT,分别对应了一次会话和一条语句。一级缓存的默认作用范围是 SESSION。
<setting name="localCacheScope" value="SESSION"/>
二是可以在映射文件的数据库操作节点内增加 flushCache属性项,该属性可以设置为 true或 false。当设置为 true时,MyBatis会在该数据库操作执行前清空一、二级缓存。该属性的默认值为 false。
<select id="queryUserBySchoolName" resultType="com.github.yeecode.mybatisdemo.User" flushCache="false">
SELECT * FROM `user`
<if test="schoolName != null">
WHERE schoolName = #{schoolName}
</if>
</select>
一级缓存功能由 BaseExecutor类实现。BaseExecutor类作为实际执行器的基类,为所有实际执行器提供一些通用的基本功能,在这里增加缓存也就意味着每个实际执行器都具有这一级缓存。
在 BaseExecutor 内,可以看到与一级缓存相关的两个属性,分别是 localCache 和localOutputParameterCache,这两个属性使用的都是没有经过任何装饰器装饰的PerpetualCache对象。
// 查询操作的结果缓存
protected PerpetualCache localCache;
// Callable查询的输出参数缓存
protected PerpetualCache localOutputParameterCache;
这两个变量中,localCache缓存的是数据库查询操作的结果。对于CALLABLE形式的语句,因为最终向上返回的是输出参数,便使用 localOutputParameterCache 直接缓存的输出参数。
BaseExecutor中 query操作的源码,通过它我们可以详细了解一级缓存的作用原理,以及localCacheScope配置、flushCache配置如何生效。
/**
* 查询数据库中的数据
* @param ms 映射语句
* @param parameter 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param <E> 结果类型
* @return 结果列表
* @throws SQLException
*/
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 新的查询栈且要求清除缓存
// 清除一级缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 尝试从本地缓存获取结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 本地缓存中有结果,则对于CALLABLE语句还需要绑定到IN/INOUT参数上
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 本地缓存没有结果,故需要查询数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 懒加载操作的处理
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
// 如果本地缓存的作用域为STATEMENT,则立刻清除本地缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
数据库操作中的 INSERT、UPDATE、DELETE操作都对应了BaseExecutor中的 update方法。在update方法中,会引发一级缓存的更新。
/**
* 更新数据库数据,INSERT/UPDATE/DELETE三种操作都会调用该方法
* @param ms 映射语句
* @param parameter 参数对象
* @return 数据库操作结果
* @throws SQLException
*/
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource())
.activity("executing an update").object(ms.getId());
if (closed) {
// 执行器已经关闭
throw new ExecutorException("Executor was closed.");
}
// 清理本地缓存
clearLocalCache();
// 返回调用子类进行操作
return doUpdate(ms, parameter);
}
可见一级缓存就是 BaseExecutor中的两个 PerpetualCache类型的属性,其作用范围很有限,不支持各种装饰器的修饰,因此不能进行容量配置、清理策略设置及阻塞设置等。
2.6.2 二级缓存
二级缓存的作用范围是一个命名空间(即一个映射文件),而且可以实现多个命名空间共享一个缓存。因此与一级缓存相比其作用范围更广,且选择更为灵活。
与二级缓存相关的配置项有四项。
- 第一个配置项在配置文件的 settings节点下,我们可以增加如下的配置语句来启用和关闭二级缓存。该配置项的默认值为 true,即默认启用二级缓存。
<setting name="cacheEnabled" value="true"/>
- 第二个配置项在映射文件内。可以使用如下所示的cache标签来开启并配置本命名空间的缓存,也可以使用
所示的标签来声明本命名空间使用其他命名空间的缓存,如果两项都不配置则表示命名空间没有缓存。该项配置只有在第一项配置中选择启用二级缓存时才有效。
<cache type="PERPETUAL"
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"
blocking="true">
<property name="timeout" value="20"/> <!--可以加入property节点,将用来直接修改Cache对象的属性-->
</cache>
- 第三个配置项为数据库操作节点内的 useCache属性,如下代码所示。通过它可以配置该数据库操作节点是否使用二级缓存。只有当第一、二项配置均启用了缓存时,该项配置才有效。对于 SELECT类型的语句而言,useCache属性的默认值为true,对于其他类型的语句而言则没有意义。
<select id="queryUserBySchoolName" resultType="com.github.yeecode.mybatisdemo.User" flushCache="false" useCache="true">
SELECT * FROM `user`
<if test="schoolName != null">
WHERE schoolName = #{schoolName}
</if>
</select>
- 第四个配置项为数据库操作节点内的 flushCache 属性项,该配置属性与一级缓存共用,表示是否要在该语句执行前清除一、二级缓存。
二级缓存功能由 CachingExecutor类实现,它是一个装饰器类,能通过装饰实际执行器为它们增加二级缓存功能。如下代码所示,在 Configuration的 newExecutor方法中,MyBatis会根据配置文件中的二级缓存开关配置用CachingExecutor类装饰实际执行器。
/**
* 创建一个执行器
* @param transaction 事务
* @param executorType 数据库操作类型
* @return 执行器
*/
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 根据数据操作类型创建实际执行器
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 根据配置文件中settings节点cacheEnabled配置项确定是否启用缓存
if (cacheEnabled) {
// 如果配置启用缓存
// 使用CachingExecutor装饰实际执行器
executor = new CachingExecutor(executor);
}
// 为执行器增加拦截器(插件),以启用各个拦截器的功能
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
在阅读 CachingExecutor类的源码之前,先讨论另外一个概念:事务。我们知道,在数据库操作中,可以将多条语句封装为一个事务;而在我们没有显式地声明事务时,数据库会为每条语句开启一个事务。于是,事务不仅可以代指封装在一起的多条语句,也可以用来代指一条普通的语句。
CachingExecutor类中有两个属性,其中delegate是被装饰的实际执行器,tcm 是事务缓存管理器。既然一条语句也是一个事务,那事务缓存管理器可以应用在有事务的场景,也可以应用在无事务的场景。
// 被装饰的执行器
private final Executor delegate;
// 事务缓存管理器
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
/**
* 查询数据库中的数据
* @param ms 映射语句
* @param parameterObject 参数对象
* @param rowBounds 翻页限制条件
* @param resultHandler 结果处理器
* @param key 缓存的键
* @param boundSql 查询语句
* @param <E> 结果类型
* @return 结果列表
* @throws SQLException
*/
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取MappedStatement对应的缓存,可能的结果有:该命名空间的缓存、共享的其它命名空间的缓存、无缓存
Cache cache = ms.getCache();
// 如果映射文件未设置<cache>或<cache-ref>则,此处cache变量为null
if (cache != null) {
// 存在缓存
// 根据要求判断语句执行前是否要清除二级缓存,如果需要,清除二级缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 该语句使用缓存且没有输出结果处理器
// 二级缓存不支持含有输出参数的CALLABLE语句,故在这里进行判断
ensureNoOutParams(ms, boundSql);
// 从缓存中读取结果
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 缓存中没有结果
// 交给被包装的执行器执行
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 缓存被包装执行器返回的结果
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 交由被包装的实际执行器执行
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
/**
* 根据要求判断语句执行前是否要清除二级缓存,如果需要,清除二级缓存
* 注意:默认情况下,非SELECT语句的isFlushCacheRequired方法会返回true
* @param ms MappedStatement
*/
private void flushCacheIfRequired(MappedStatement ms) {
// 获取MappedStatement对应的缓存
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
// 存在缓存且该操作语句要求执行前清除缓存
// 清除事务中的缓存
tcm.clear(cache);
}
}
而 CachingExecutor的 update方法(对应 INSERT、UPDATE、DELETE三种数据库操作)也会调用flushCacheIfRequired方法,而对于这些语句isFlushCacheRequired子方法恒返回 true。因此,总会导致二级缓存的清除。
2.6.3 两级缓存机制
现在我们已经清楚 MyBatis 存在两级缓存,其中一级缓存由BaseExecutor 通过两个PerpetualCache类型的属性提供,而二级缓存由 CachingExecutor包装类提供。
那么在数据库查询操作中,是先访问一级缓存还是先访问二级缓存呢?为了便于讨论,我们再来看一下图
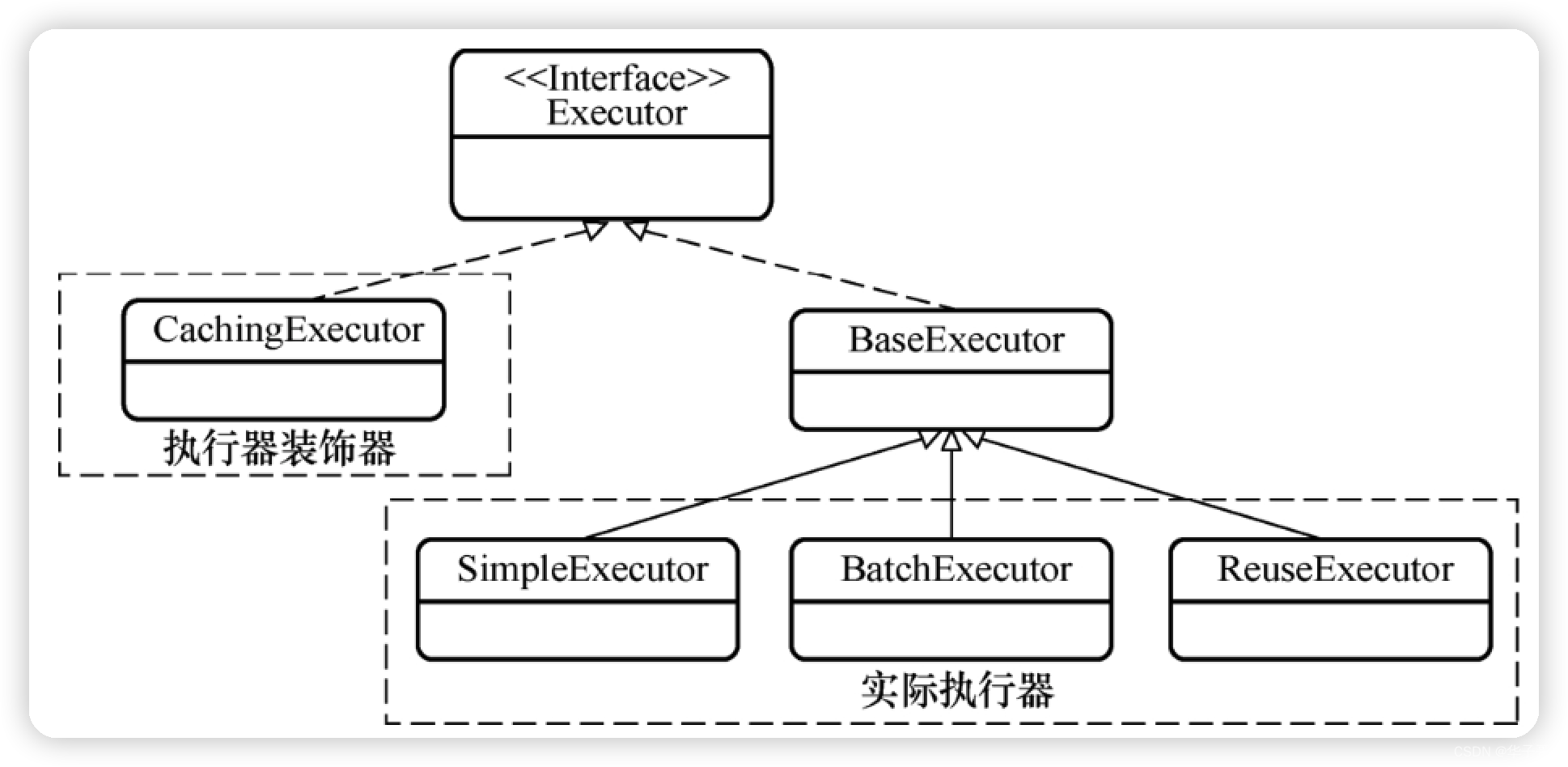
Executor接口的简化类图。
答案并不复杂,CachingExecutor作为装饰器会先运行,然后才会调用实际执行器,这时 BaseExecutor 中的方法才会执行。因此,在数据库查询操作中,MyBatis 会先访问二级缓存再访问一级缓存。
这样,我们便可以得到如下图所示的 MyBatis两级缓存示意图。