【人脸识别6】用haar+adaboost训练自己的人脸检测器
【1. 准备样本】
1.将ORL数据库中的400张人脸储存到一个文件夹下positive_samples
2.生成索引文件posdata.dat
3.生成vec文件
【2.训练分类器】
【3.测试自己的分类器是否好用】
已训练好的cascade.xml文件以及正负样本集,有需要的可戳此处下载:https://download.csdn.net/download/u012679707/10462869
这是人脸识别系列的第六节,之前的小节分别为:
5. 【opencv人脸识别5】通过建立模型(.xml文件)识别出你的脸
在应用了opencv自带的人脸检测器之后,为了加深对haar+adaboost+CART(决策二叉树)的理解,也为了以后能自己训练检测器来进行物体检测,所以利用opencv自带的训练器opencv_createsamples.exe和opencv_haartraining.exe来训练自己的人脸检测器。我电脑上安装了opencv2.4.9和opencv3.4,但在opencv3.4中未发现这两个程序,如若哪位发现了这两个程序在opencv3.4中的哪个位置,麻烦告知,非常感谢!
【注意】
1.本实验平台为windows+VS2012+opencv2.4.9
2.opencv_createsamples.exe和opencv_haartraining.exe所在位置为:
opencv安装位置\Opencv\opencv\build\x86\vc11\bin(VS2012对应的是vc11,其他版本的VS对应不同的vc版本)
如果你系统环境变量中的path添加的是64位的opencv\build\x64\vc11,则去该路径下找opencv_createsamples
.exe和opencv_haartraining.exe。
首先,训练一个检测器,要准备哪些数据呢?
先来看一下opencv_haartraining.exe需要的参数:首先是正样本和负样本。然后是样本数量、迭代数、击中率和误检率(虚警概率)等。
【opencv_haartraining.exe需要的参数】
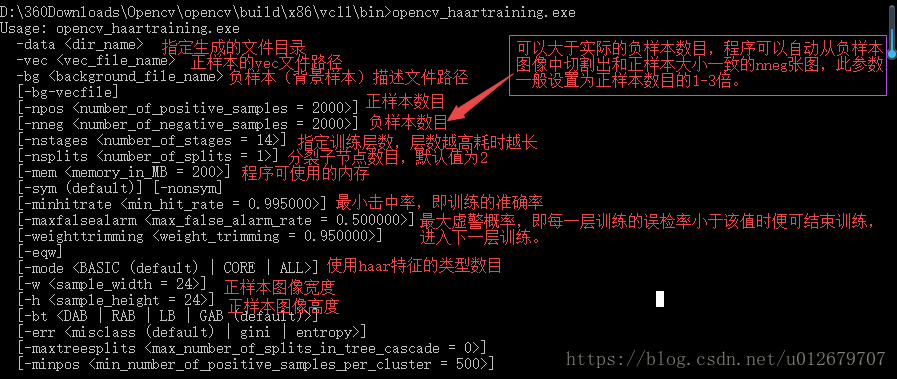
注意:haar所需的vec文件,需要用opencv_createsamples.exe来生成。opencv_createsamples.exe的所需参数如下:
【opencv_createsamples.exe需要的参数】

【1. 准备样本】
haar训练器需要正样本和负样本。正样本是人脸图片,负样本为不含人脸的图片。
正样本:
本实验所用的正样本,我选取的是ORL数据库中的400张人脸,将其reshape成20*20的大小。

1.将ORL数据库中的400张人脸储存到一个文件夹下positive_samples
需先将其设置成统一尺寸的,例如20*20,30*30,较常用。我用的是20*20。
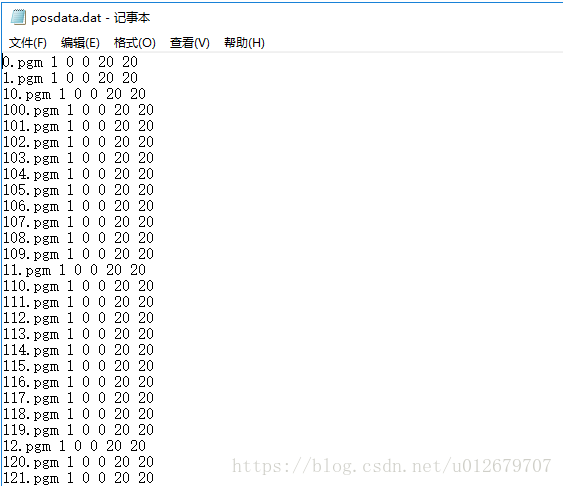
2.生成索引文件posdata.dat
dos命令下执行: cd ..\positive_samples //cd 进入正样本图像所在的文件夹
dir /b > posdata.dat
生成文件posdata.dat。然后,用txt的替换工具将“pgm”全部替换成“pgm 1 0 0 20 20”。便变成如下图所示的形式。
【注意】我把描述文件放在你的 positive_samples路径(即正样本路径)下,这样就不需要加前面的相对路径了。
3.生成vec文件
因为opencv_haartraing.exe需要正样本的vec文件,所以需用到opencv_createsamples.exe程序,来生成正样本的vec文件。具体的opencv_createsamples.exe的参数介绍见【附录1】。
在dos命令行下执行:
D:\360Downloads\Opencv\opencv\build\x86\vc11\bin>opencv_createsamples.exe -info "F:\opencv_project\positive_samples\posdata.dat" -vec F:\opencv_project\positive_samples\pos.vec -num 400 -w 20 -h 20

运行完了会在F:\opencv_project\positive_samples\下生成一个*.vec的文件。该文件包含正样本数目,宽高以及所有样本图像数据。具体的opencv_createsamples.exe的参数解释请见附录1。
负样本:
负样本我用的是 PASCAL VOC库中的JPEGImages数据集从中选取540个样本 ,放在..\negitive_samples文件夹下。
PASCAL VOC库里边包含多类样本,可做为负样本,链接为:http://pjreddie.com/projects/pascal-voc-dataset-mirror/
负样本的可描述文件 negdata.dat的生成:
在dos下执行: cd ..\negitive_samples //cd 进入负样本图像所在的文件夹
dir /b > negdata.dat

注意:把negdata.dat文件末尾的“negdata.dat”以及空行去掉,只保留有用的jpg路径。
好了,现在正负样本及相应的描述文件都准备好了。可以训练了。
【2.训练分类器】
opencv_haartraing.exe登场了。它来实现分类器(人脸检测器)的训练。
具体的opencv_haartraing.exe的参数见【附录2】.
在dos下执行:
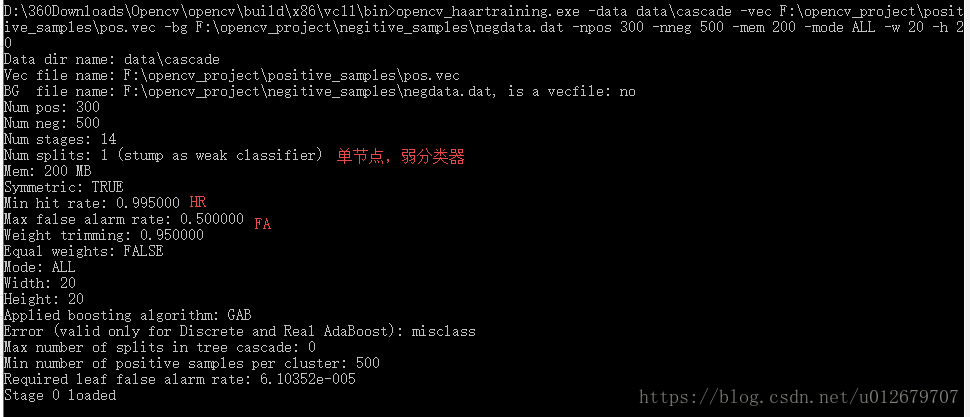
D:\360Downloads\Opencv\opencv\build\x86\vc11\bin>opencv_haartraining.exe-data data\cascade -vec F:\opencv_project\positive_samples\pos.vec -bgF:\opencv_project\negitive_samples\negdata.dat -npos 300 -nneg 500 -mem 200 -modeALL -w 20 -h 20

训练结束后,会在目录data下生成一些子目录,即为训练好的分类器。

打开cascade.xml,可见级联分类器的具体参数,如下:

具体的训练过程以及cascade.xml详解,请见【附录3】。
现在就可以拿着cascade.xml来检测人脸啦。
【3.测试自己的分类器是否好用】
具体从图片中检测人脸的程序可见:
// face_recog_from_picture.cpp: 定义控制台应用程序的入口点。
#include "stdafx.h"
#include<opencv2/opencv.hpp>
#include<iostream>
using namespace std;
using namespace cv;
int main(int argc,char *argv[])
{
Mat img = imread("1.jpg");
namedWindow("display");
imshow("display", img);
/*********************************** 1.加载人脸检测器 ******************************/
// 建立级联分类器
CascadeClassifier cascade;
// 加载训练好的 人脸检测器(.xml)
const string path = "./xml/cascade.xml";//自己训练的人脸检测器
if ( ! cascade.load(path))
{
cout << "cascade load failed!\n";
}
//计时
double t = 0;
t = (double)getTickCount();
/*********************************** 2.人脸检测 ******************************/
vector<Rect> faces(0);
cascade.detectMultiScale(img, faces, 1.1, 2, 0 ,Size(30,30));
cout << "detect face number is :" << faces.size() << endl;
/******************************** 3.显示人脸矩形框 ******************************/
if (faces.size() > 0)
{
for (size_t i = 0;i < faces.size();i++)
{
rectangle(img, faces[i], Scalar(150, 0, 0), 3, 8, 0);
}
}
else cout << "未检测到人脸" << endl;
t = (double)getTickCount() - t; //getTickCount(): Returns the number of ticks per second.
cout << "检测人脸用时:" << t * 1000 / getTickFrequency() << "ms (不计算加载模型的时间)" << endl;
namedWindow("face_detect");
imshow("face_detect", img);
while(waitKey(0)!='k') ;
destroyWindow("display");
destroyWindow("face_detect");
return 0;
}
检测结果:

检测结果不是很理想,但毕竟这么小的样本能训练出来已经很不错了,具体的正负样本以及cascade.xml文件,有需要的,可戳此处下载:https://download.csdn.net/download/u012679707/10462869
-------------------------------------- 附录 -------------------------------------------------------------
【附录1】
【opencv_createsamples.exe需要的参数】
-bgcolor<background_color> 背景色(假定当前图片为灰度图)。背景色制定了透明色。对于压缩图片,颜色方差量由bgthresh参数来指定。则在bgcolor-bgthresh和bgcolor+bgthresh中间的像素被认为是透明的。
-bgthresh<background_color_threshold>-inv 如果指定,颜色会反色-randinv 如果指定,颜色会任意反色-maxidev<max_intensity_deviation> 背景色最大的偏离度。-maxangel<max_x_rotation_angle>-maxangle<max_y_rotation_angle>,-maxzangle<max_x_rotation_angle> 最大旋转角度,以弧度为单位。-show 如果指定,每个样本会被显示出来,按下"esc"会关闭这一开关,即不显示样本图片,而创建过程继续。这是个有用的debug选项。-w<sample_width> 输出样本的宽度(以像素为单位)-h《sample_height》 输出样本的高度,以像素为单位。
【附录2】
【opencv_haartraining.exe需要的参数】
-nsplits<number_of_splits>决定用于阶段分类器的弱分类器。如果1,则一个简单的stump classifier被使用。如果是2或者更多,则带有number_of_splits个内部节点的CART分类器被使用。默认=2表示弱分类器二叉决策树的分裂数; 1表示使用简单stump 分类(只有一个树桩)
-mem<memory_in_MB>预先计算的以MB为单位的可用内存。内存越大则训练的速度越快。
-sym(default)-nonsym指定训练的目标对象是否垂直对称。垂直对称提高目标的训练速度。例如,正面部是垂直对称的。
-weighttrimming<weight_trimming>指定是否使用权修正和使用多大的权修正。一个基本的选择是0.9
-eqw-mode<basic(default)|core|all>选择用来训练的haar特征集的种类。basic仅仅使用垂直特征。all使用垂直和45度角旋转特征。
- nstages不要设置太小,不然到时候拿去检测速度会很慢
- minhitrate(HR)设的越高,需要的样本数目越多
- minhitrate 每个阶段分类器需要的最小的命中率,总的命中率为min_hit_rate的number_of_stages次方。
- maxfalsealarm 没有阶段分类器的最大错误报警率,总的错误警告率为max_false_alarm_rate的number_of_stages次方。
【附录3】具体的训练过程
data文件夹下:
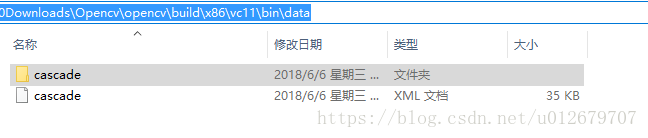
cascade文件夹下:有10个分类器
stage 0:
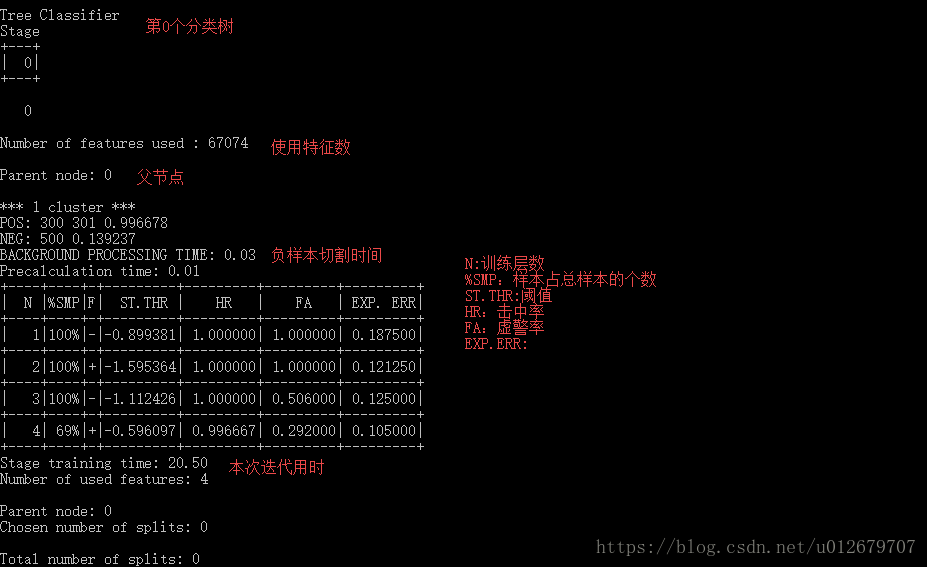
EXP.ERR: 为经验错误率。
stage 9:
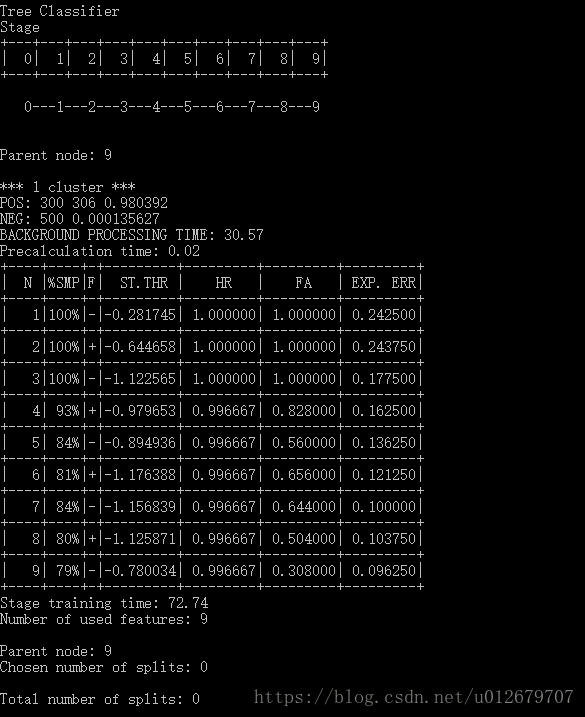
------------------------------------------- END -------------------------------------
【参考】:
1. opencv haar+adaboost使用心得
https://blog.csdn.net/liulina603/article/details/8197889
2. 人脸识别之人脸检测(二)--人脸识别样本制作及训练测试
https://blog.csdn.net/app_12062011/article/details/51422604
3. AdaBoost 人脸检测介绍(6) : 使用OpenCV自带的 AdaBoost程序训练并检测目标
https://blog.csdn.net/nk_wavelet/article/details/52626907