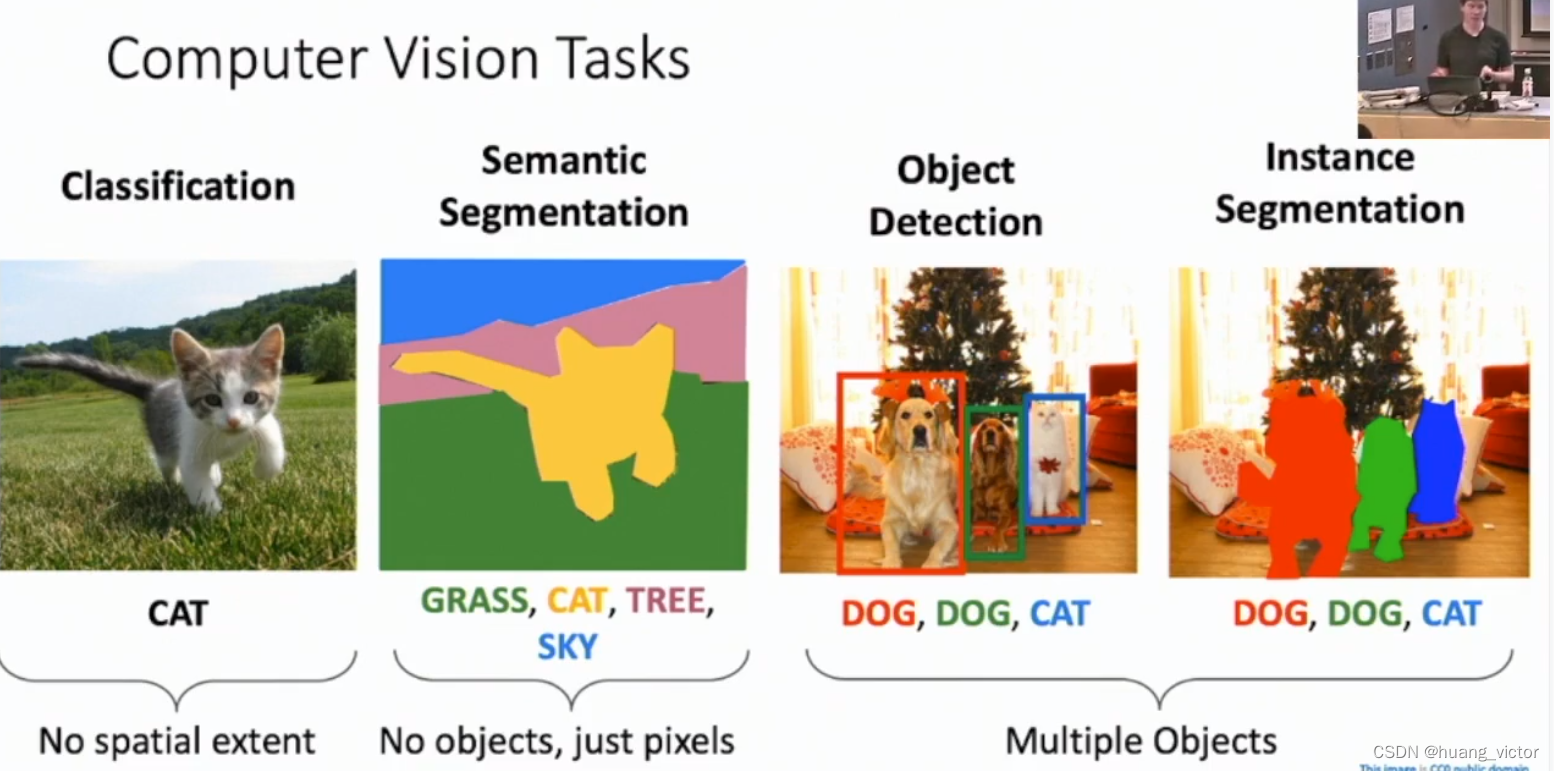
1. 图像任务:
分类、语义分割、目标检测、 实例分割
2. 目标检测任务:
在2D的图像中,画框,框出目标物体。因此既有分类任务,也有定位的任务。
输入:图像 HxWx3
输出:带类别的2D框,cx,cy,width,height, class
挑战:1. 输出不定数量的bbox
2. 需要输出类别和定位尺寸
3. 输入图像尺寸分辨率一般会比较大(相对于纯分类任务)
2.1 单目标检测任务
如果确定某个样本中只有一个目标,那就直接分别预测类别,回归bbox的位置和尺寸,通过multi task的加权loss去优化网络。
分类用ce/loss
定位用 l1/l2 loss

2.2 多目标检测任务_滑动窗口
滑动的提取图像的小的区域,然后针对这个小区域做图像分类任务。
待检测区域数量太多,可能性的尺寸太多,每一个都要输入分类网络进行计算,不现实。
2.3 Region-Based CNN
通过图像传统算法,获得一定数量的推荐区域;
然后在这些推荐区域上进行分类任务;
推荐的区域尺寸不是很准,同时进行一个regression任务,调整推荐区域的尺寸。

2.4 Fast-RCNN
RCNN的优化,特征提取通过backbone实现,selective search和之前一样在raw image上获得区域,这些区域会提取backbone的feature,然后在这些带feature的区域通过轻量级的convnet进行后续的任务。

如何区域性的提取feature
可以通过简单的pooling,把region对应的特征塞到对应的grid里

通过插值的方式,不是通过pooling的方式

2.5 Faster-RCNN
Fast-RCNN的进一步优化,去除了selective search的工作,利用网络获取roi区域。
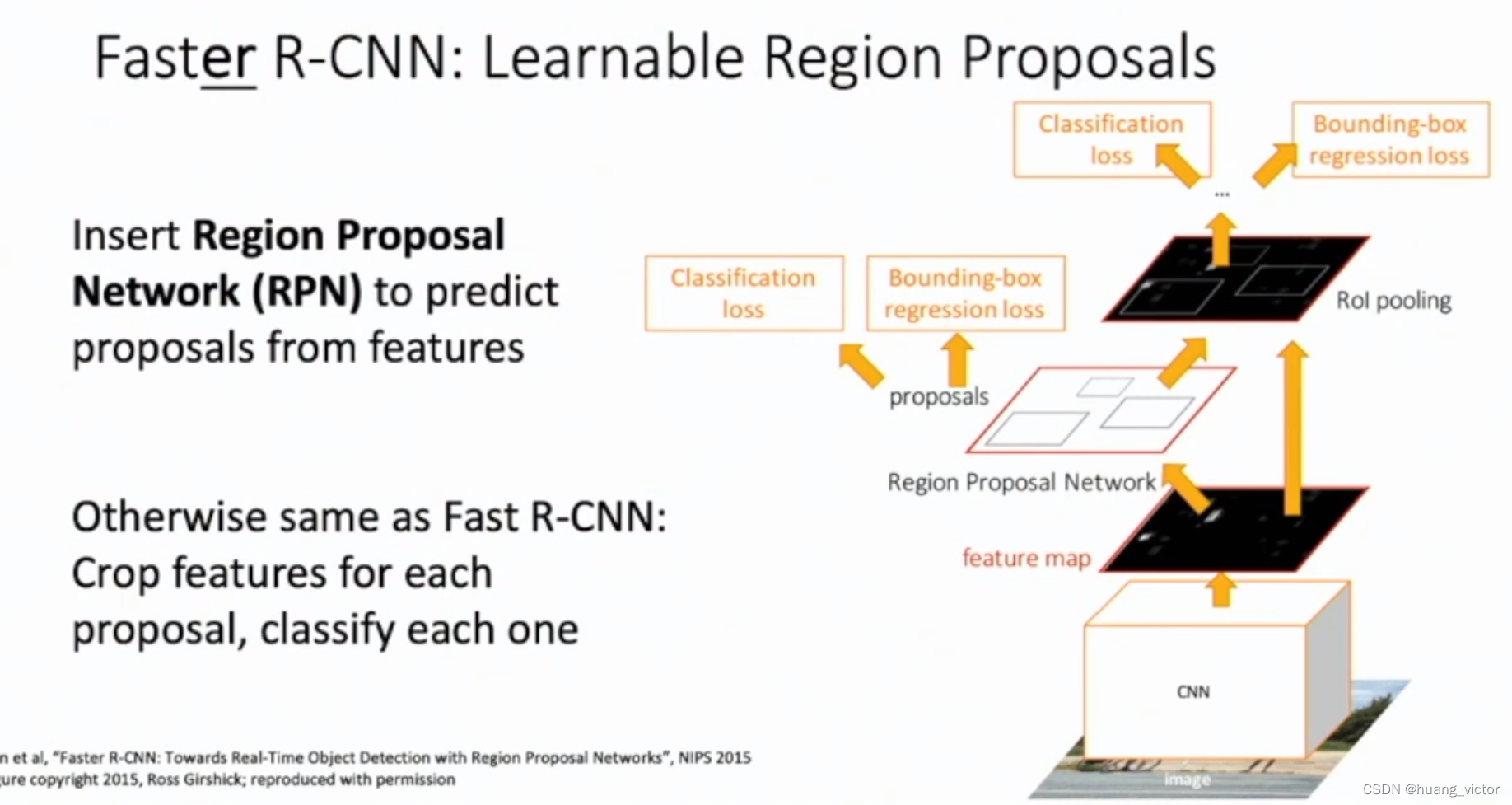
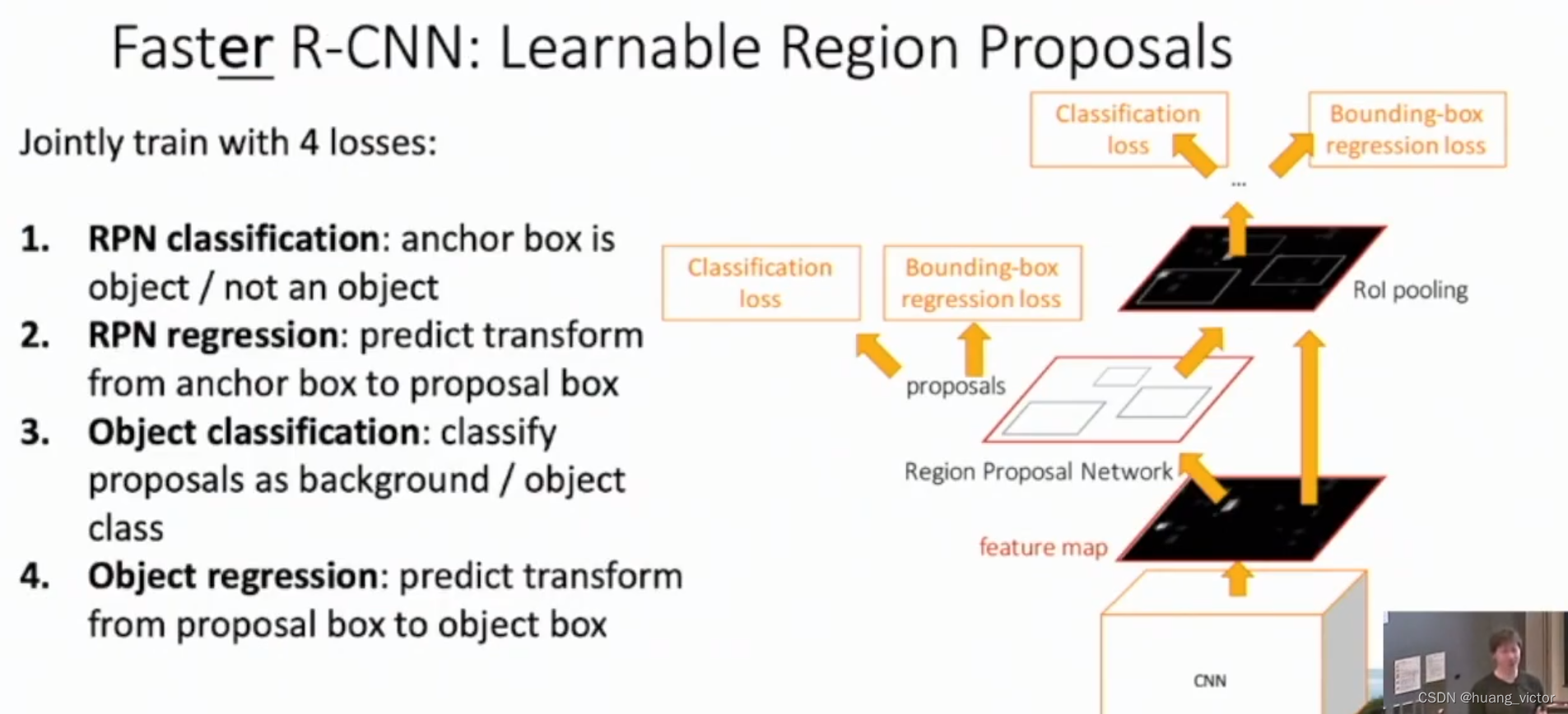

RPN,region propose network
通过anchor的方式生成结果,每个位置放置预设的,不同大小、不同比例的anchor。
anchor是否是object。通过focal loss来约束。
gt box相对于anchor的偏移。通过l1/l2来约束。
2.6 single stage detector

大趋势

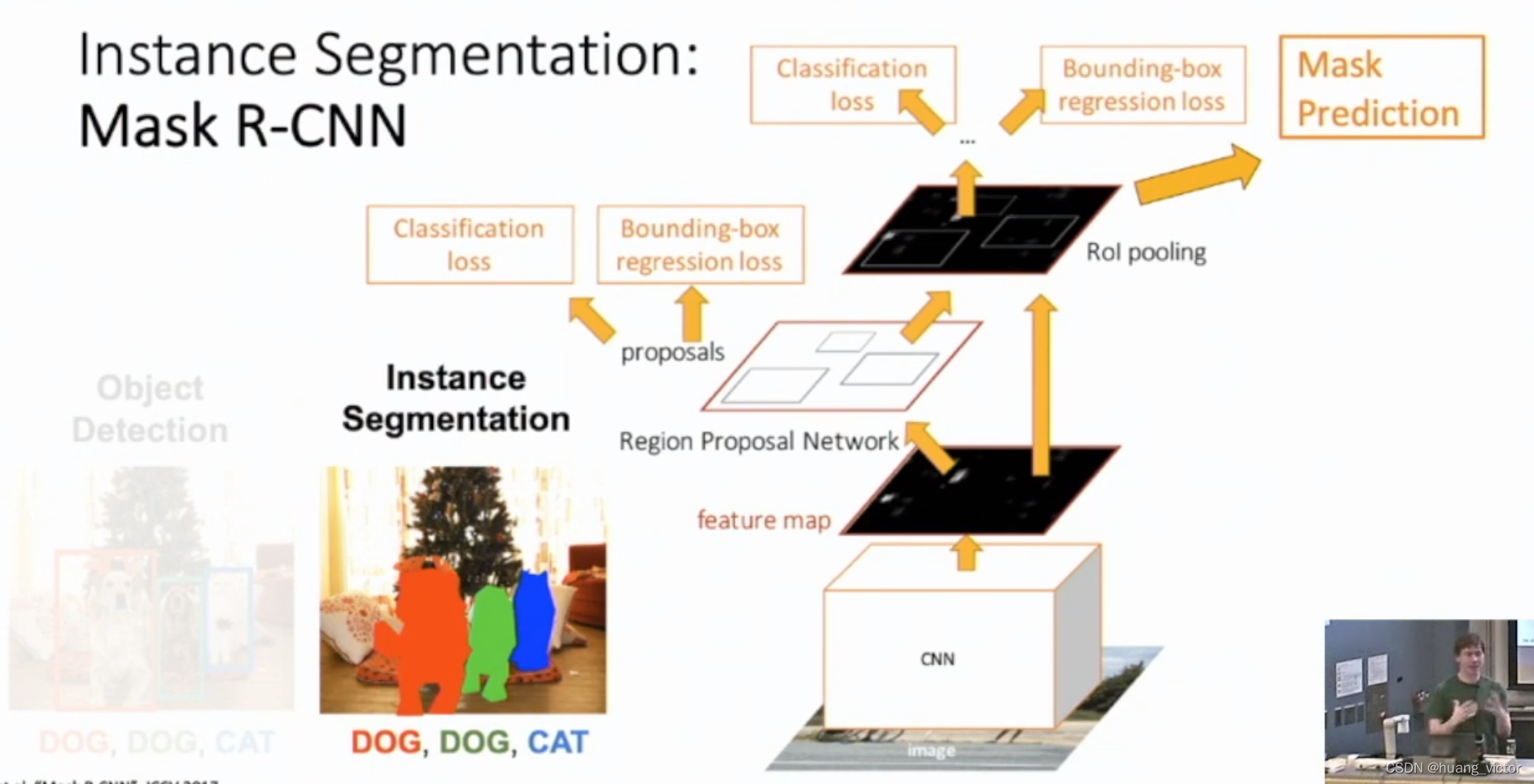
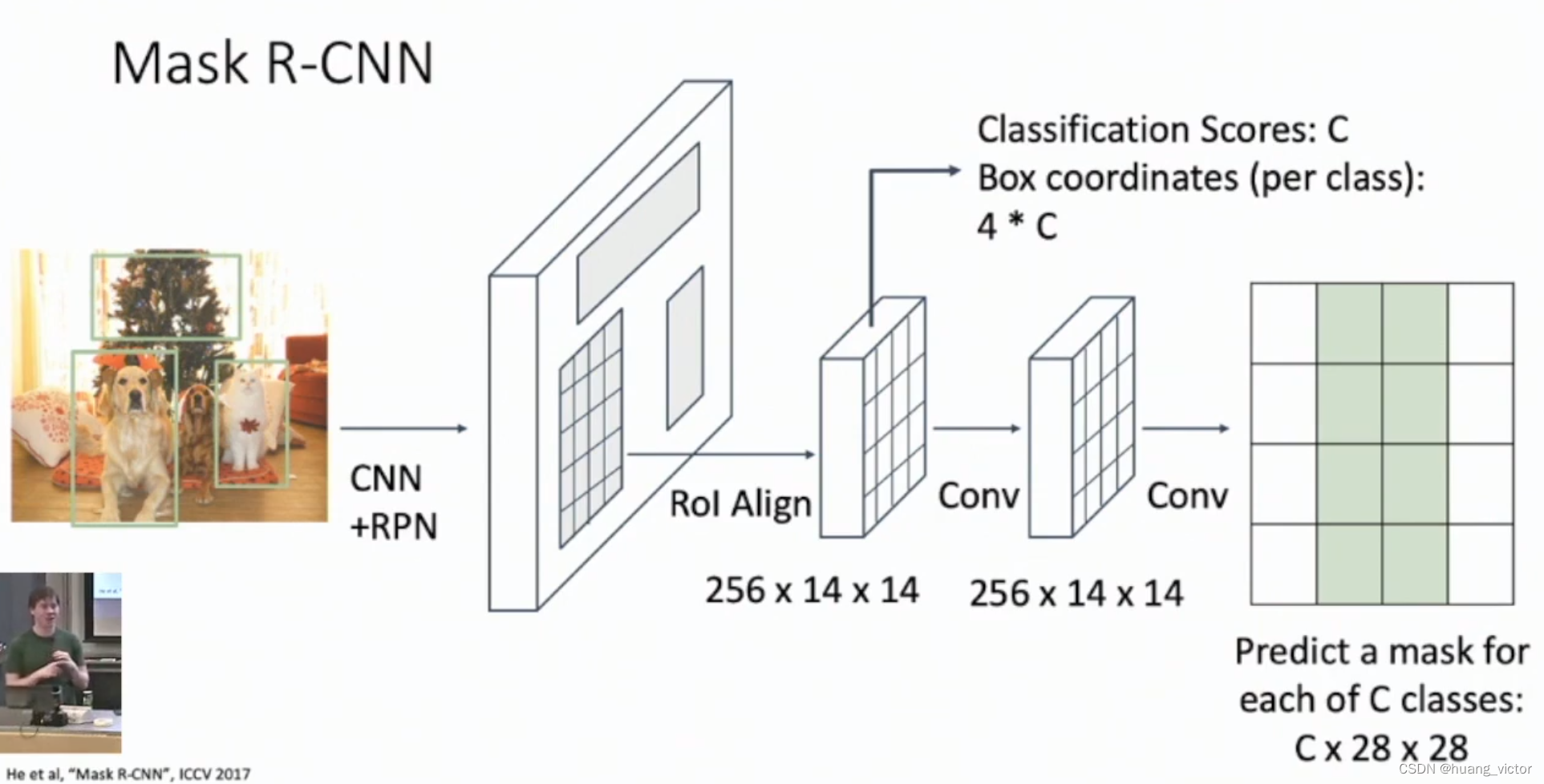
2.7 Mask-RCNN
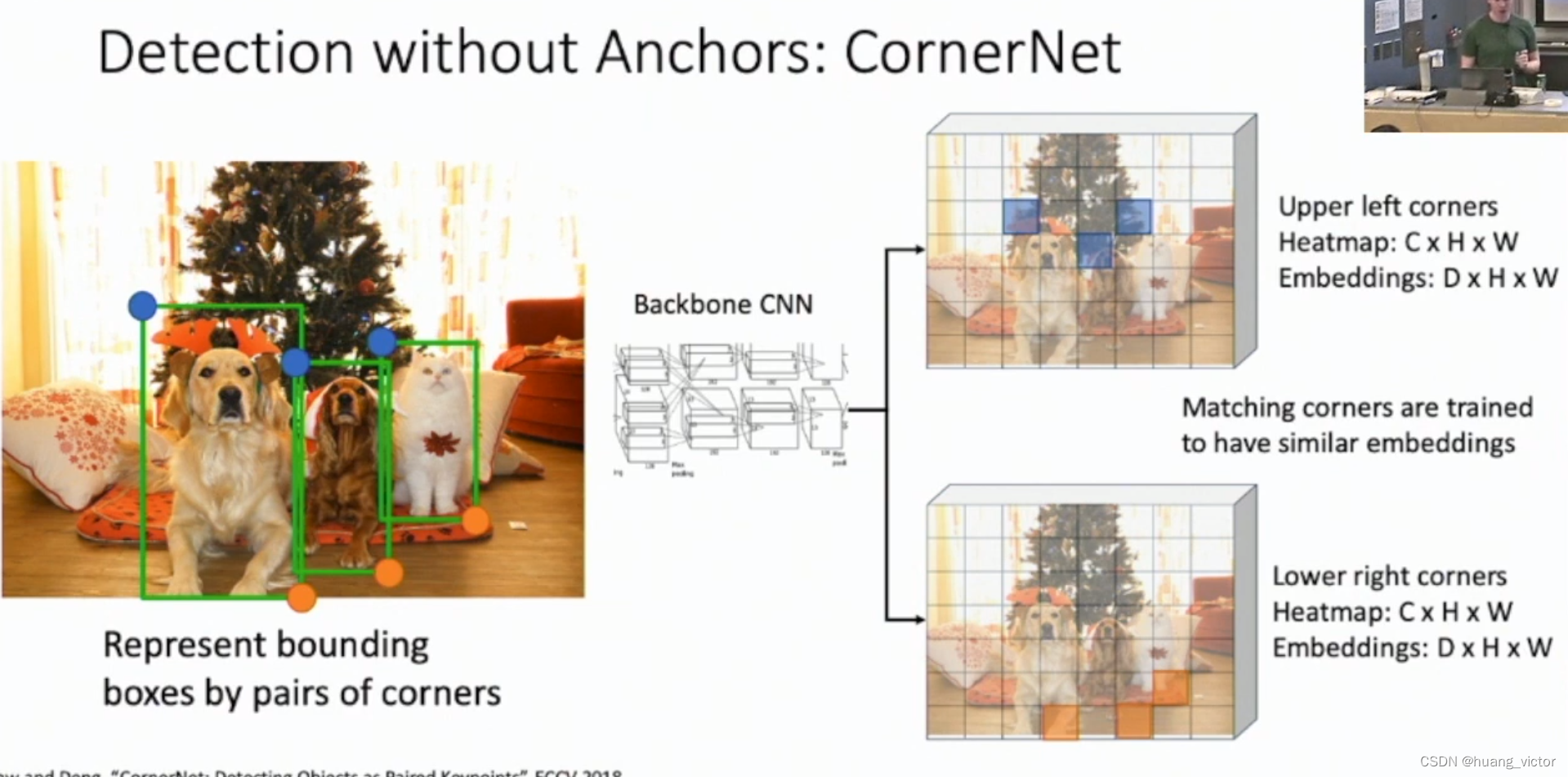
2.8 CornetNet
2.9 CenterNet
2.9 Yolo series
3. 常用辅助算法
3.1 IOU for axis aligned bbox

from collections import namedtuple
import numpy as np
import cv2
def bb_intersection_over_union(boxA, boxB):
# determine the (x, y)-coordinates of the intersection rectangle
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# compute the area of intersection rectangle
# 交集
interArea = (xB - xA + 1) * (yB - yA + 1)
# compute the area of both the prediction and ground-truth rectangles
# 并集
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
# compute the intersection over union by taking the intersection
# area and dividing it by the sum of prediction + ground-truth
# areas - the interesection area
iou = interArea / float(boxAArea + boxBArea - interArea)
# return the intersection over union value
return iou
# define the `Detection` object
Detection = namedtuple("Detection", ["image_path", "gt", "pred"])
# define the list of example detections
examples = [
Detection("dog.png", [39, 63, 203, 112], [54, 66, 198, 114]),
Detection("dog.png", [49, 75, 203, 125], [42, 78, 186, 126]),
Detection("dog.png", [31, 69, 201, 125], [18, 63, 235, 135]),
Detection("dog.png", [50, 72, 197, 121], [54, 72, 198, 120]),
Detection("dog.png", [35, 51, 196, 110], [36, 60, 180, 108])]
# loop over the example detections
for detection in examples:
# load the image
image = cv2.imread(detection.image_path)
# draw the ground-truth bounding box along with the predicted
# bounding box
cv2.rectangle(image, tuple(detection.gt[:2]),
tuple(detection.gt[2:]), (0, 255, 0), 2)
cv2.rectangle(image, tuple(detection.pred[:2]),
tuple(detection.pred[2:]), (0, 0, 255), 2)
# compute the intersection over union and display it
iou = bb_intersection_over_union(detection.gt, detection.pred)
cv2.putText(image, "IoU: {:.4f}".format(iou), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
print("{}: {:.4f}".format(detection.image_path, iou))
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
3.2 IOU for rotated bbox
Rotated IoU 计算_旋转iou_THE@JOKER的博客-CSDN博客
问了chatgpt,
import math
from shapely.geometry import Polygon
def get_corners(rbbox):
x, y, w, h, theta = rbbox
xmin = x - w/2
xmax = x + w/2
ymin = y - h/2
ymax = y + h/2
cos_theta = math.cos(theta)
sin_theta = math.sin(theta)
x1 = x + (xmin - x) * cos_theta + (ymin - y) * sin_theta
y1 = y - (xmin - x) * sin_theta + (ymin - y) * cos_theta
x2 = x + (xmax - x) * cos_theta + (ymin - y) * sin_theta
y2 = y - (xmax - x) * sin_theta + (ymin - y) * cos_theta
x3 = x + (xmax - x) * cos_theta + (ymax - y) * sin_theta
y3 = y - (xmax - x) * sin_theta + (ymax - y) * cos_theta
x4 = x + (xmin - x) * cos_theta + (ymax - y) * sin_theta
y4 = y - (xmin - x) * sin_theta + (ymax - y) * cos_theta
return [(x1, y1), (x2, y2), (x3, y3), (x4, y4)]
def intersection_area(rbbox1, rbbox2):
corners1 = get_corners(rbbox1)
corners2 = get_corners(rbbox2)
poly1 = Polygon(corners1)
poly2 = Polygon(corners2)
intersection = poly1.intersection(poly2)
if intersection.is_empty:
return 0
else:
return intersection.area
def union_area(rbbox1, rbbox2):
corners1 = get_corners(rbbox1)
corners2 = get_corners(rbbox2)
poly1 = Polygon(corners1)
poly2 = Polygon(corners2)
union = poly1.union(poly2)
return union.area - intersection_area(rbbox1, rbbox2)
def iou(rbbox1, rbbox2):
return intersection_area(rbbox1, rbbox2) / union_area(rbbox1, rbbox2)
rbbox1 = (100, 100, 200, 100, math.pi/4)
rbbox2 = (120, 120, 150, 80, math.pi/6)
iou_value = iou(rbbox1, rbbox2)
print(iou_value)
3.3 NMS
因为有很多的重叠的bbox,很多都是冗余的,需要去除,大体的思路怎么做?
选取某个类别,所有类别下bbox排序,
计算所有bbox之间的iou,
从最大的score,开始遍历bbox,去除和这个bbox的iou大于某个nms threshold的bbox
直到所有的都遍历完成
问题:实际场景目标很多,的确有很多的bbox,会去除正确的bbox

python code from chatgpt
def nms(boxes, scores, threshold):
"""Apply Non-Maximum Suppression (NMS) to a set of boxes given their corresponding scores.
Args:
boxes (numpy.ndarray): A numpy array of shape `(N, 4)` containing the coordinates of N bounding boxes.
Each row is of the form `[x1, y1, x2, y2]` where `(x1, y1)` and `(x2, y2)` are the top-left and
bottom-right corners of the bounding box, respectively.
scores (numpy.ndarray): A numpy array of shape `(N,)` containing the corresponding confidence scores
for each bounding box.
threshold (float): A float value specifying the overlap threshold for suppression.
Returns:
numpy.ndarray: A numpy array of indices of the selected bounding boxes after NMS.
"""
# 1. Initialize an empty list to store the selected bounding boxes
selected_boxes = []
# 2. Sort the bounding boxes by their corresponding scores in descending order
order = np.argsort(scores)[::-1]
# 3. Loop over the sorted indices while there are still indices left in the order array
while order.size > 0:
# 4. Get the index of the box with the highest score (i.e., the first index in the order array)
index = order[0]
# 5. Add the corresponding box to the selected boxes list
selected_boxes.append(index)
# 6. Compute the overlap of the remaining boxes with the selected box using the compute_overlap function
overlap = compute_overlap(boxes[index], boxes[order[1:]])
# 7. Get the indices of the boxes that overlap with the selected box more than the threshold
indices = np.where(overlap > threshold)[0] + 1
# 8. Remove the selected box and the overlapping boxes from the order array
order = np.delete(order, indices)
# 9. Return the indices of the selected boxes after NMS
return np.array(selected_boxes)
3.4 mAP计算
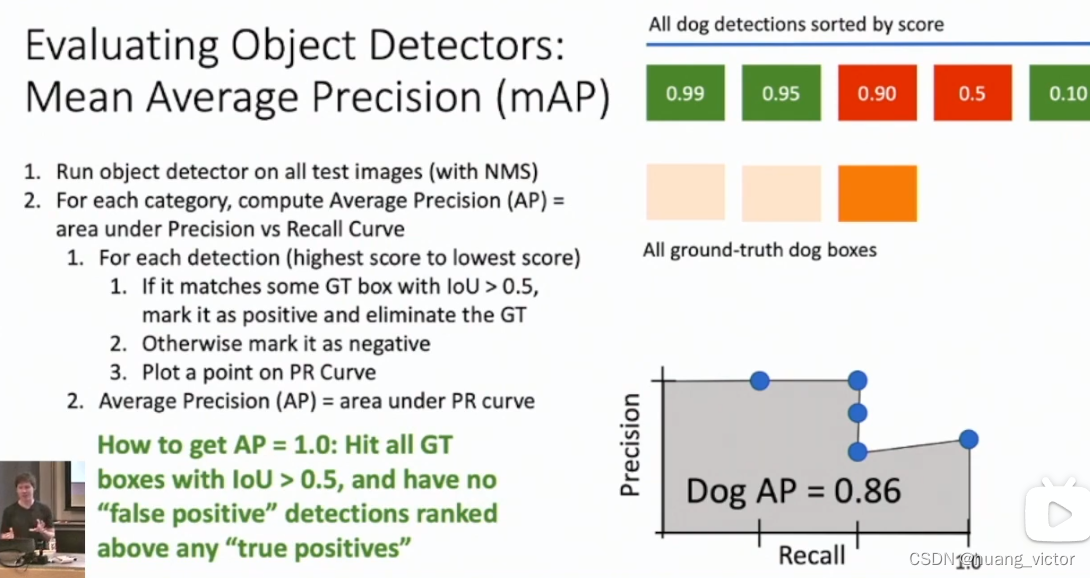

1. 预测目标检测结果
2. 根据score,对结果进行排序
3. 从score最大的box开始遍历,计算当前的precision和recall,保存到list中
4. 计算AP
5. 计算mAP水电费
def calculate_precision_recall(gt_boxes, pred_boxes, iou_thresh=0.5):
# Initialize true positives, false positives, and false negatives
tp = 0
fp = 0
fn = len(gt_boxes)
# Match predictions to ground truth
for pred_box in pred_boxes:
best_iou = 0
best_gt_box = None
for gt_box in gt_boxes:
iou = calculate_iou(gt_box, pred_box)
if iou > best_iou:
best_iou = iou
best_gt_box = gt_box
if best_iou >= iou_thresh:
# Match found
tp += 1
fp -= 1
fn -= 1
gt_boxes.remove(best_gt_box)
else:
# No match found
fp += 1
# Calculate precision and recall
precision = tp / (tp + fp)
recall = tp / (tp + fn)
return precision, recall
def calculate_ap(gt_boxes, pred_boxes, iou_thresh=0.5):
# Sort predictions by confidence score in descending order
pred_boxes = sorted(pred_boxes, key=lambda x: x[4], reverse=True)
# Calculate precision and recall for each prediction
precisions = []
recalls = []
for i, pred_box in enumerate(pred_boxes):
precision, recall = calculate_precision_recall(gt_boxes.copy(), pred_boxes[:i+1], iou_thresh=iou_thresh)
precisions.append(precision)
recalls.append(recall)
# Calculate average precision using the 11-point method
ap = 0
for t in np.arange(0, 1.1, 0.1):
if len([recall for recall in recalls if recall >= t]) == 0:
p = 0
else:
p = max([precision for precision, recall in zip(precisions, recalls) if recall >= t])
ap += p / 11
return ap
def calculate_mAP(gt_boxes_list, pred_boxes_list, iou_thresh=0.5):
# Calculate AP for each class
aps = []
for c in range(len(gt_boxes_list)):
gt_boxes = gt_boxes_list[c]
pred_boxes = pred_boxes_list[c]
ap = calculate_ap(gt_boxes, pred_boxes, iou_thresh=iou_thresh)
aps.append(ap)
3.5 Focal Loss
在目标检测任务中,分类分支用于判定某个anchor和这center是否是前景,是哪种前景色。如果简单的使用cross entropy loss,会导致模型更偏向去学习数量众多的简单的背景任务,反而在数量少的前景任务上表现不佳。为了平衡这种难易、数量少多的样本分布,引入focal loss。
FL(p_t) = - (1 - p_t)^gamma * log(p_t)
where p_t is the predicted probability of the true class (either foreground or background), and gamma is the focusing parameter. When gamma is set to 0, the focal loss becomes equivalent to the standard cross-entropy loss.
class FocalLoss(nn.Module):
def __init__(self, gamma=2, alpha=None, reduction='mean'):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.alpha = alpha
self.reduction = reduction
def forward(self, inputs, targets):
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
pt = torch.exp(-BCE_loss)
focal_loss = ((1-pt)**self.gamma * BCE_loss)
if self.alpha is not None:
alpha = self.alpha.to(inputs.device)
focal_loss = alpha * focal_loss
if self.reduction == 'mean':
return torch.mean(focal_loss)
elif self.reduction == 'sum':
return torch.sum(focal_loss)
else:
return focal_loss