
一、背景
当备库回放事务时,多个互相不依赖的事务可以并发回放,本方法主要用于解决多个可并发回放的事务的并发回放问题。通过并发的多个扫描线程实现并发对事物回放队列进行扫描,生成多个可以并发回放的事物,并且通知回放线程进行并发的回放。
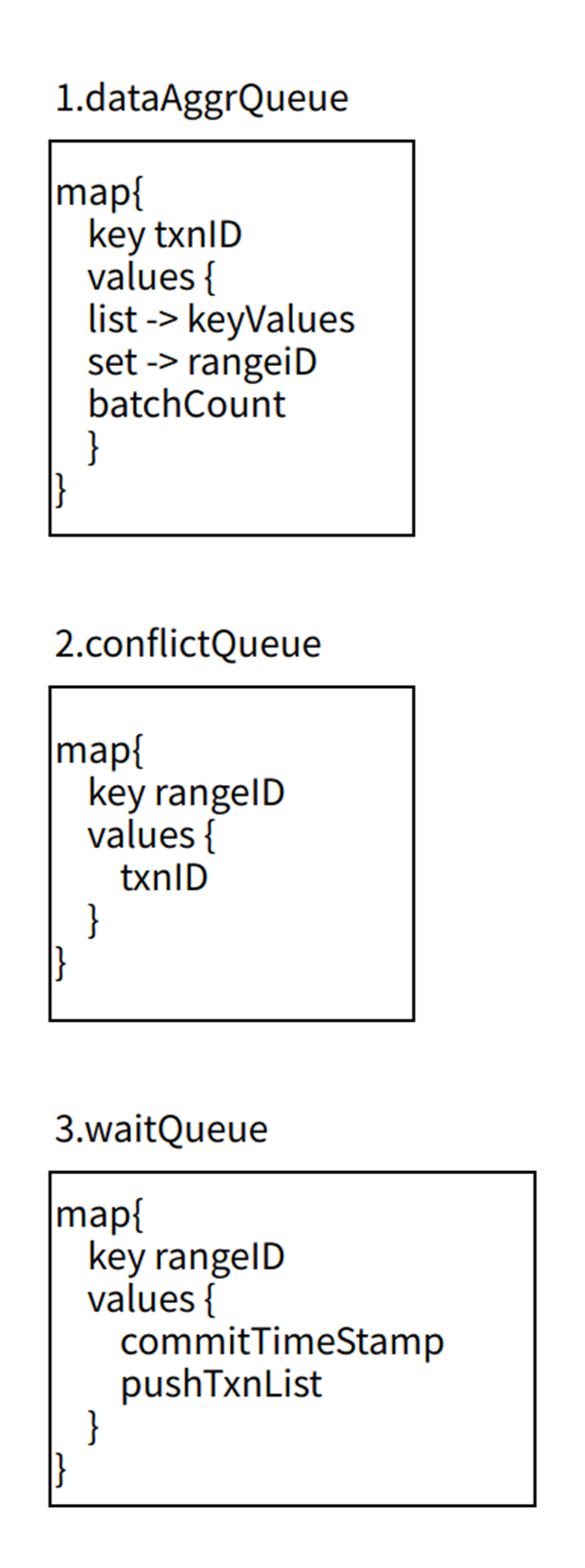
二、数据结构设计
备库的事物数据按照事物 ID 分段存储到备库的事物数据队列中,参考如下图 1;根据事物 ID 为 UUID 完全无序的特性,可以对 UUID 进行事物 ID 分段并发扫描。将事物 ID UUID 分段后,交给多个扫描线程协程,每个扫描线程负责某个 UUID 分区进行多个扫描线程并发扫描,扫描可回放的事物。
三、线程生命周期
当扫描线程发现可回放的事物后,会将事物 ID 加入 txnList 执行 enqueu 操作,加入事物 ID 后,扫描线程会执行 notify 操作,唤醒正在睡眠的回放线程进行事务回放操作,示意图参考如下图 2。 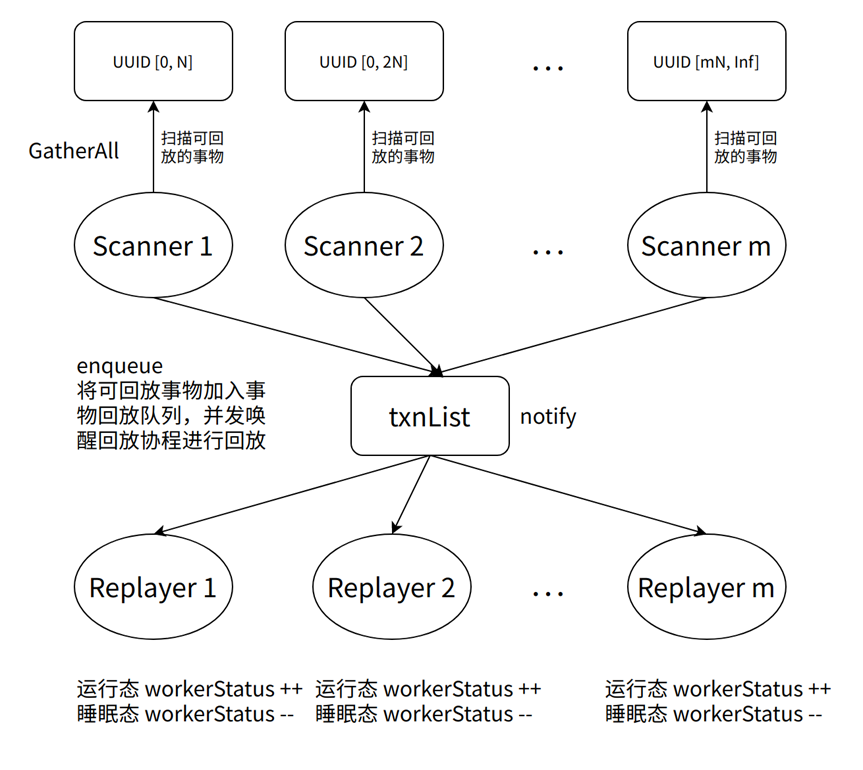
回放线程协程的生命周期如下如图 3,回放线程刚启动后处于睡眠状态,当有事务回放时,会被随机唤醒。被唤醒的回放线程协程会执行事务回放任务,并且清理事务的依赖关系。
当发现可回放的事务时,如果发现可回放的事务数等于 1,则由当前协程进行回放减少一次 CPU 切换的开销;当发现多余 1 个可回放事务时,回放线程协程会将除去第一个的可回放事务,加入 txnList 唤醒其他协程进行事务回放,以实现更好回放的并发性能。 
四、并发切换问题
在采取了并发清理时,因为 CPU 切换的问题,需要处理重复发现的可回放事务,对重复发现相同的事务 ID 进行防御性幂等处理,如下图 4。因此,需要对每个可回放事务引入 txnIDSet 进行幂等处理。 
五、如何判断回放是否结束
因为采取了并发扫描以及并发回放,所以需要在全部可回放事务全部回放结束后,结束回放的流程,在此给出回放结束的定义。
当可回放事务全部回放结束后,认为回放结束。可回放事务分为 3 类,过去发现的可回放事务/现在发现的可回放事务/将来发现的可回放事务。
过去发现的可回放事务都会被加入到 txnList 中,现在发现的可回放事务正在由回放线程进行回放,将来发现的可回放事务是由扫描线程扫描 UUID 进行发现的。
- 过去发现的事务回放结束的条件为 txnList 为空;
- 现在发现的事务回放结束的条件为所有的 workerStatus 总和为 0;
- 将来发现的事务回放结束的条件为所有的扫描线程,GatherAll 扫描可回放事务无法发现。
六、性能调优
根据 CPU 数量,可通过动态调整扫描线程和回放线程的回放协程数量,以合理分配两组协程的负载。这样做可以充分利用多核处理器的性能,并提高系统的吞吐量和响应能力。
我决定放弃开源 工业软件大事件 —— OGG 1.0 发布,华为贡献全部源代码 Ubuntu 24.04 LTS 正式发布 谷歌 Python 基金会团队被裁员 Google Reader 被“代码屎山”杀死 Fedora Linux 40 正式发布 知名游戏公司出新规:员工娶妻彩礼不得超过 10 万元 中国联通发布全球首个 Llama3 8B 中文版开源模型 拼多多因不正当竞争被判赔偿 500 万元 国产云输入法——仅华为无云端数据上传安全问题