
分享人:曾庆国 |学校:南方科技大学
内容简介
摩尔定律的放缓推动了非传统计算范式的发展,例如专门针对组合优化问题求解的定制化Ising机。本次会议将介绍基于P-bit的Ising机在训练深度生成式神经网络方面的新应用,使用稀疏、异步和高度并行的Ising机,在混合概率-经典计算设置中训练深度波尔兹曼网络。
相关论文
标题:Training Deep Boltzmann Networks with Sparse Ising Machines
作者:**Shaila Niazi, Navid Anjum Aadit, Masoud Mohseni, Shuvro Chowdhury, Yao Qin, Kerem Y. Camsari
01
文章的主旨
目标: 说明如何使用专用硬件系统 (例如P-bit) 有效地训练稀疏版本的深度玻尔兹曼网络,在计算硬概率采样任务中, 这些硬件系统比常用的软件实现有数量级的加速;
长期目标: 帮助促进物理启发的概率硬件的开发,以降低基于图形和张量处理单元(GPU/TPU)的传统深度学习的快速增长成本;
硬件实现困难点:
1. 相连p-bits必须串行更新, 禁止在稠密系统中进行更新更新;
2. 确保p位在更新之前从其邻居节点接收到所有的最新信息,否则,网络不会从真正的波尔兹曼分布中采样。
02
主题内容
使用稀疏Ising机训练深度玻尔兹曼网络的内容主要分成四部分:
1. 网络结构
2. 目标函数
3. 参数优化
4. 推断(分类和图像生成)
1. 网络结构
采用D-Wave开发的Pegasus和Zepyhr拓扑结构来训练硬件感知的稀疏深度网络。该操作启发于扩展但连接受限的网络(如人脑和高级微处理器)。尽管机器学习模型中普遍使用全连接,但具有数十亿晶体管网络的先进微处理器和人脑都表现出很大程度的稀疏性。事实上,由于每个节点所需的计算负责度高,RBM的大多数硬件实现面临扩展问题,而硬件神经网络中的稀疏连接通常显示出优势。并且,稀疏的网络结构很好地解决了上述硬件实现的难点。
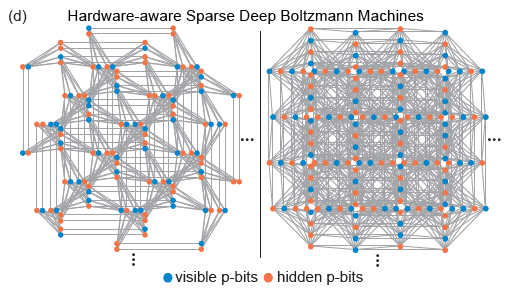
(图片来源:arXiv:2303.10728)
2. 目标函数
最大化似然函数等价于最小化数据分布和模型分布之间的KL散度:
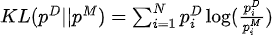
其中,  为数据分布,
为数据分布, 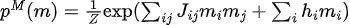 为模型分布。
为模型分布。
KL散度关于模型参数(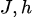 )的梯度为:
)的梯度为:
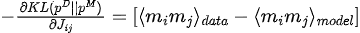
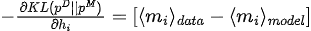
3. 参数优化

(图片来源:arXiv:2303.10728)
根据算法1训练网络参数,包括
-
初始化参数(
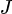 ,
,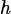 )的初始化;
)的初始化; -
使用训练数据对输入层p-bits进行赋值,然后进行MC采样,得到数据分布的采样样本;
-
直接进行MC采样得到模型分布的采样样本;
-
利用两个阶段采样得到的样本估计梯度(称为持续性对比散度),并使用梯度下降法更新参数。
其中,MC采样使用p-bits迭代演化:

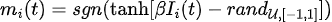
在训练稀疏玻尔兹曼网络的过程中, 还有两点需要注意:
-
1)随机化p-bits索引
在给定稀疏网络上训练玻尔兹曼网络模型时,visible、hideen和label节点之间的图距离是一个非常重要的的概念。通常,如果层是完全连接的,则任何给定的两个节点之间的图距离都是常数, 但对于稀疏图来说却不是这样的, 所以visible、hideen和label p-bits的位置就显得格外重要了。如果visible、hideen和label p-bits聚集且太近,分类精度会受到很大影响。这很可能是因为如果标签位和可见位的图形距离太大,它们之间的相关性就会变弱。随机化p-bits索引可以缓解这个问题。 -
-
(图片来源:arXiv:2303.10728)
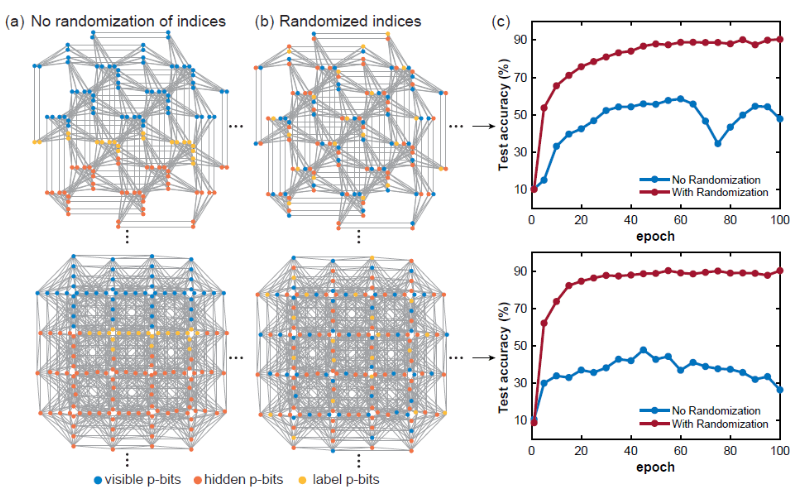
**2)大规模并行**
在稀疏深度玻尔兹曼网络上,我们使用启发式图着色算法DSatur对图着色,对于未连接p-bits进行并行更新。
-
-
(图片来源:arXiv:2303.10728)
4. 推断
分类: 使用测试数据固定visible p-bits, 接着进行MC采样, 然后对得到的label-pbits取期望, 取期望值最大的标签为预测的标签
-
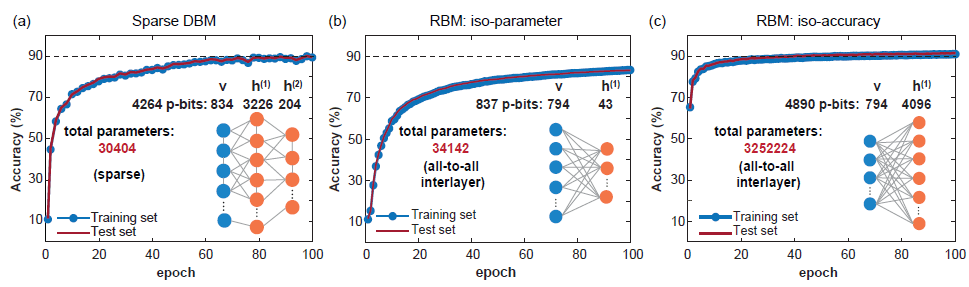
-
(图片来源:arXiv:2303.10728)
图像生成: 将label p-bits固定成想要生成标签所对应的编码, 然后就行MC采样, 且采样过程中对网络进行退火(从0以0.125为步长逐步增长至5), 得到的样本对应的visible p-bits即为生成的图像。
-

-
(图片来源:arXiv:2303.10728)
03
总结
文章使用了一个具有大规模并行体系结构的稀疏Ising机,它实现了比传统CPU快数量级的采样速度。论文系统地研究了硬件感知网络拓扑的混合时间,并表明模型的分类精度不受算法的计算可操作性的限制,而是受在本工作中能够使用的中等大小的FPGA的限制。进一步的改进可能涉及使用更深入、更广泛、可能“更难混合”的网络架构,充分利用超快概率采样器。此外,将传统DBM的逐层训练技术与文章的方法结合起来,可以带来进一步可能的改进。使用纳米器件实现稀疏Ising机,例如随机磁隧道结,可能会改变关于深度玻尔兹曼网络实际应用现状。
90后程序员开发视频搬运软件、不到一年获利超 700 万,结局很刑! 谷歌证实裁员,涉及 Flutter、Dart 和 Python 团队 中国码农的“35岁魔咒” Xshell 8 开启 Beta 公测:支持 RDP 协议、可远程连接 Windows 10/11 MySQL 的第一个长期支持版 8.4 GA 开源日报 | 微软挤兑Chrome;阳痿中年的福报玩具;神秘AI能力太强被疑GPT-4.5;通义千问3个月开源8模型 Arc Browser for Windows 1.0 正式 GA Windows 10 市场份额达 70%,Windows 11 持续下滑 GitHub 发布 AI 原生开发工具 GitHub Copilot Workspace JAVA 下唯一一款搞定 OLTP+OLAP 的强类型查询这就是最好用的 ORM 相见恨晚