


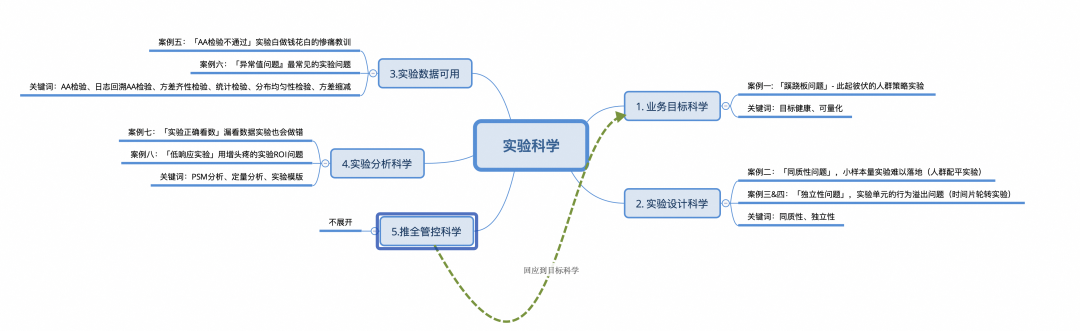

业务目标科学:增长目标应该是长期健康、可量化验证的
▐ 案例一:「蹊跷板问题」- 此起彼伏的运营实验

案例分析
从实验结论可以看出,该实验显著提升人均GMV,同时显著降低用户体验;这类对冲指标在业务中并不少见,例如提高人均成交笔数的同时不降低比单价、提高人均观看时长的同时不降低人均成交金额等等,如果不同的小团队恰好分配到了对冲指标(组织架构常见问题),则大团队需要合理制定目标同时,格外关注对冲指标。
当前解法
-
由大团队维护核心指标、围栏指标,通常这块需要业务leader、财务、BI多方确定。
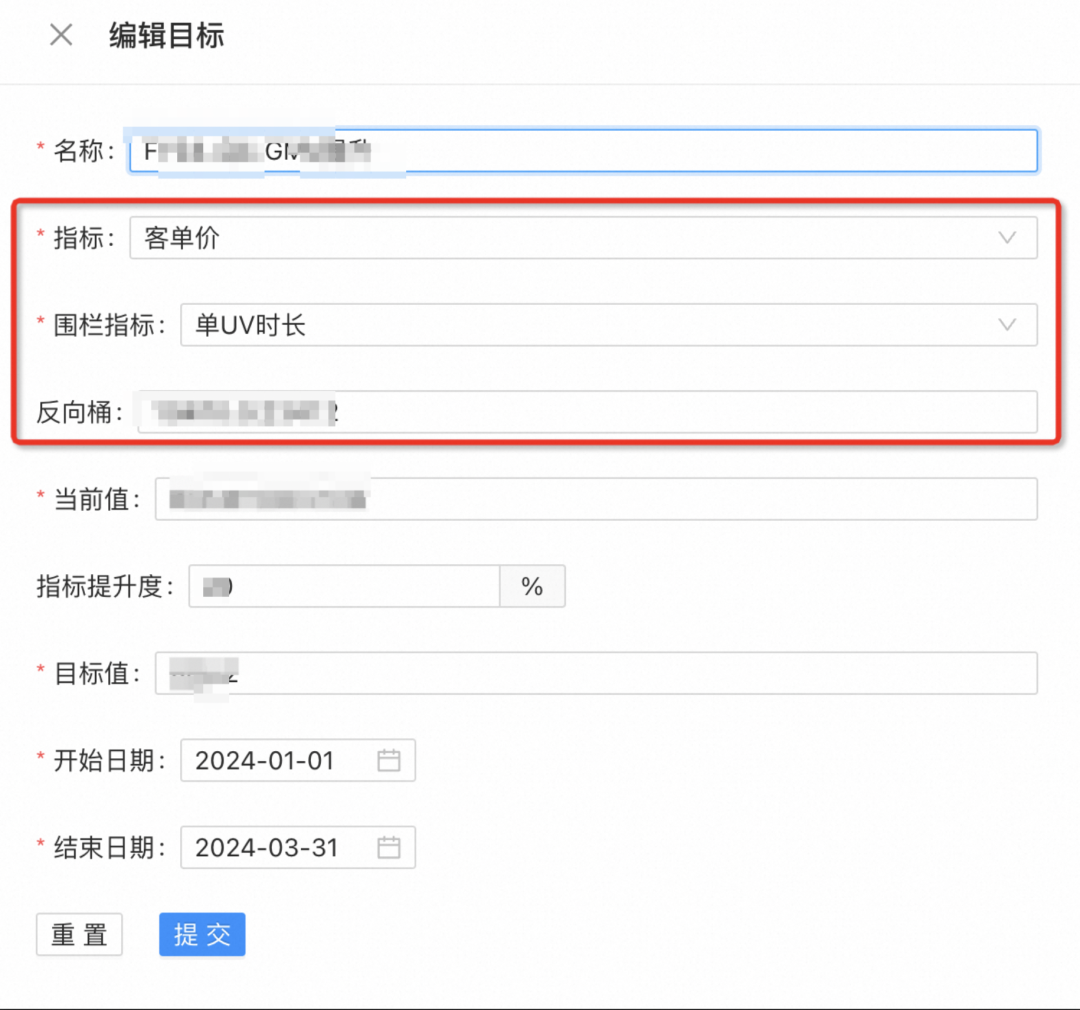
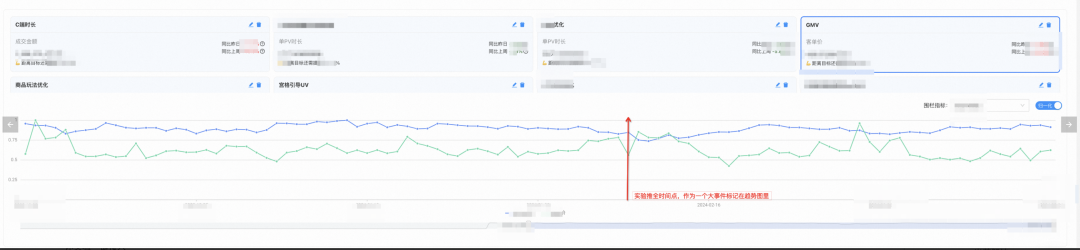
归一化渲染核心指标和围栏指标走势,观察实验推全节点对其产生的直观变化;
-
结合长期反向桶,验证实验增量价值。(图中未展示)
思考:实验管理视角下的业务OKR指标应该怎么定?
-
OKR设定为可实验证明的指标(例如人均GMV),通过这个指标来量化评估实验价值; -
严格反向桶管控流程,通过反向桶预估GMV贡献;

▐ 案例二:「同质性问题」,小样本量实验难进行:新主播实验
案例分析
业务假设:我们通常会做大量策略实验,来提高淘宝新主播的入驻体验,以某个策略为例,我们假设该策略能够有效提高新主播积极性。
实际情况:经过业务筛选后的可实验新主播样本量较少,而主播之间的个体差异巨大,因此随机抽取的两个样本组间指标波动较大,无法开展实验。
当前解法思路
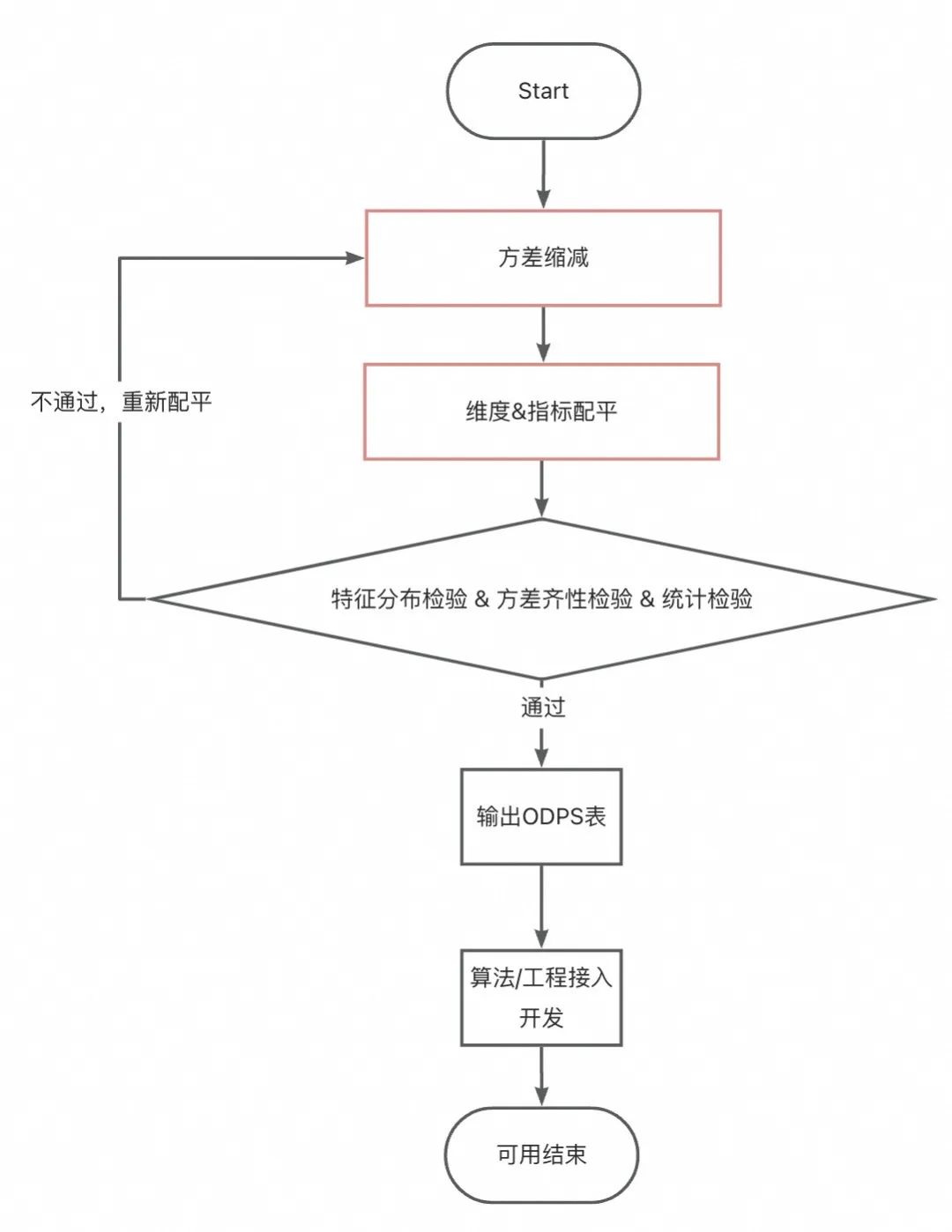
-
方差缩减: 围绕实验待验证指标, 适量剔除离群点 (注意:剔除过多会导致实验效果偏小,剔除过少会导致波动过大,经验上至少保留到99分位),如果依然方差过大,可以 适当加工为长周期指标 ,本案例中主播单日成交金额差异过大,我们则取了三日平均成交金额。但是,这会 导致实验回收数据周期变长 、 实验可解释性可能变差 ,因此需要明确实验目的,再做口径处理。 -
指标&维度配平 :通过离线处理,获取到指标数据分布相当、维度分布相当的多组样本。
-
如果 样本量不是很小、组内差异不太明显 ,可以试试 简单分组配平 ,即每个分组取相同比例的主播参与实验。 -
如果 样本量过小,或组内差异较大 ,则可以使用模型做指标、维度的配平处理,本次案例采用协变量自适应随机方法,可以稳定通过AA检验。
-
AA检验: 保证分组结果具有同质性,确保实验结论可用,这块在下文详细展开。
思考
小样本量实验由于其对大盘的影响较小、实现难度较大,往往容易被忽略,然而在精细化运营下,这类实验也开始逐渐被重视起来。关于小样本量的“小”我们也需要注意,在一个真实的商品降价案例中,重复随机采样500个商品1000次,发现其均值集合并不符合正态分布,调整到随机采样10000个商品后均值开始呈现明显正态分布,因此该背景下的实验可抽样数量不得小于10000。
▐ 案例三&四:「独立性问题」,粉丝间的社群关系导致的用户行为溢出、主播间的流量竞争关系导致的主播行为溢出,这些实验怎么做?
案例分析
当前解法
通过将时间分割成多个时间片,并以每个时间片作为独立的实验单元,我们可以确保在同一个时间片内的所有用户都会体验到相同的策略。这种设计有效地规避了用户体验的不一致性问题。同理,在每个时间片中,所有流量都会被统一分配至一个策略之下。这样的安排从根本上预防了流量竞争和用户体验的不一致性,确保了实验的公平性和有效性。通过时间片轮转实验,我们能够在任何给定时刻为所有用户提供统一的体验,从而在实验过程中维持一致性和避免潜在的干扰。

缺点:
由于其实验单元为时间,所以可统计样本量较少,导致实验效果评估周期长,同时日期切片容易受热点事件影响,导致实验结论偏差。
由于需保证实验单元的独立性,且日期天然存在延续性,因此要减少日期之间的影响,例如1号的策略会影响到2号凌晨的主播(因为主播的场次容易跨天),所以日期切割需要结合业务特点,灵活选择时间切片大小和切割点。

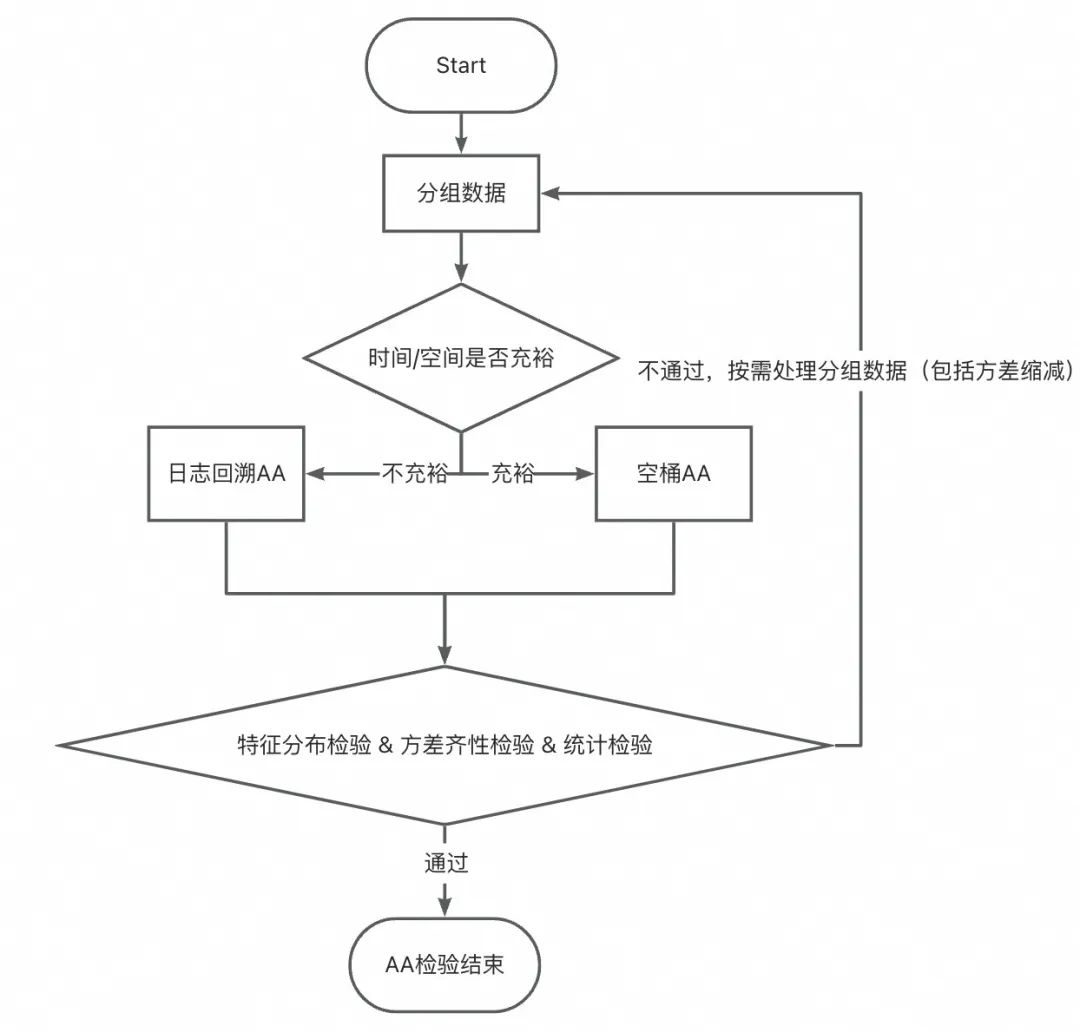
▐ 案例五:「AA检验不通过」在一次下单返红包的实验中,在分析实验数据时才发现用户分布不均匀,导致实验结论严重错误,甚至得出相反结论,浪费实验期间投入的预算等资源。
案例分析
当前解法
1、分布均匀性检验
在这次案例中,实验组和对照组在购买力分层上严重不均,从而导致其核心指标也显著不均,无法获得实验效果。注意:
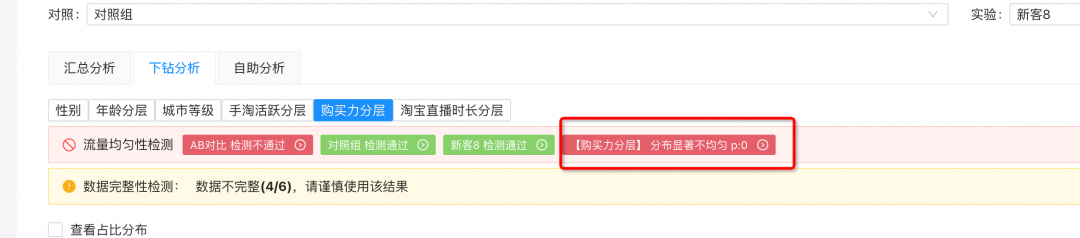
注意:分布不均匀并不一定表示实验数据不可用,本次案例是由于分布不均匀引起了核心指标不同质,导致了实验效果无法验证;
2、方差齐性检验 & 统计检验
在这次案例中,购买力的分布不均已经引起了指标不同质。从下图可以直观理解不同质现象,假设实验组和对照组本身同质,那么他们的数据分布应该都在绿色区域中,随后因为实验组施加了不同策略,导致实验组数据分布从绿色区域移动到了黄色区域。如果实验组未上策略就已经移动到了黄色区域,那么我们是无法证明策略对实验的影响。


图为检验结果
-
统计检验:通过双样本T检验或者多样本ANOVA检验,比较两个独立样本或配对样本的均值差异,具体检验方法可以根据实验样本量大小、样本均衡性情况、样本组数量决定。 -
方差齐性检验:通过Levene's Test或Bartlett's Test来验证实验组和对照组的数据方差是否一致。如果p值大于常用的显著性水平(如0.05),则可以认为组间方差是同质的。
▐ 案例六:「异常值问题』在一次打赏实验中,发现实验效果波动较大,排查后发现榜一大哥竟能左右实验效果
案例分析
在这个案例中,由于实验的用户一致性,榜一大哥会持续进入同一个实验组,于是大哥上线的天数该实验组效果就很好,大哥不在的天数则表现平平。这种实验如果没有找到这个异常值,按照常规经验难以进行分析和迭代。
当前解法
方差缩减:因为异常值会影响到指标的均值、方差,因此异常值除了引起汇总结果的波动外,实验的AA检验、AB检验也都会受影响。目前根据参与实验的实际样本量,采用常用手段:四分位数间距法、标准差法、Z-Score、孤立森林等方式做动态处理。
思考
A/B实验是验证因果关系的黄金标准。错误的因,只会带来错误的果。做好数据可用性验证,保证因果关系的正确发现,是沉淀实验经验,建立实验文化的必要基础。

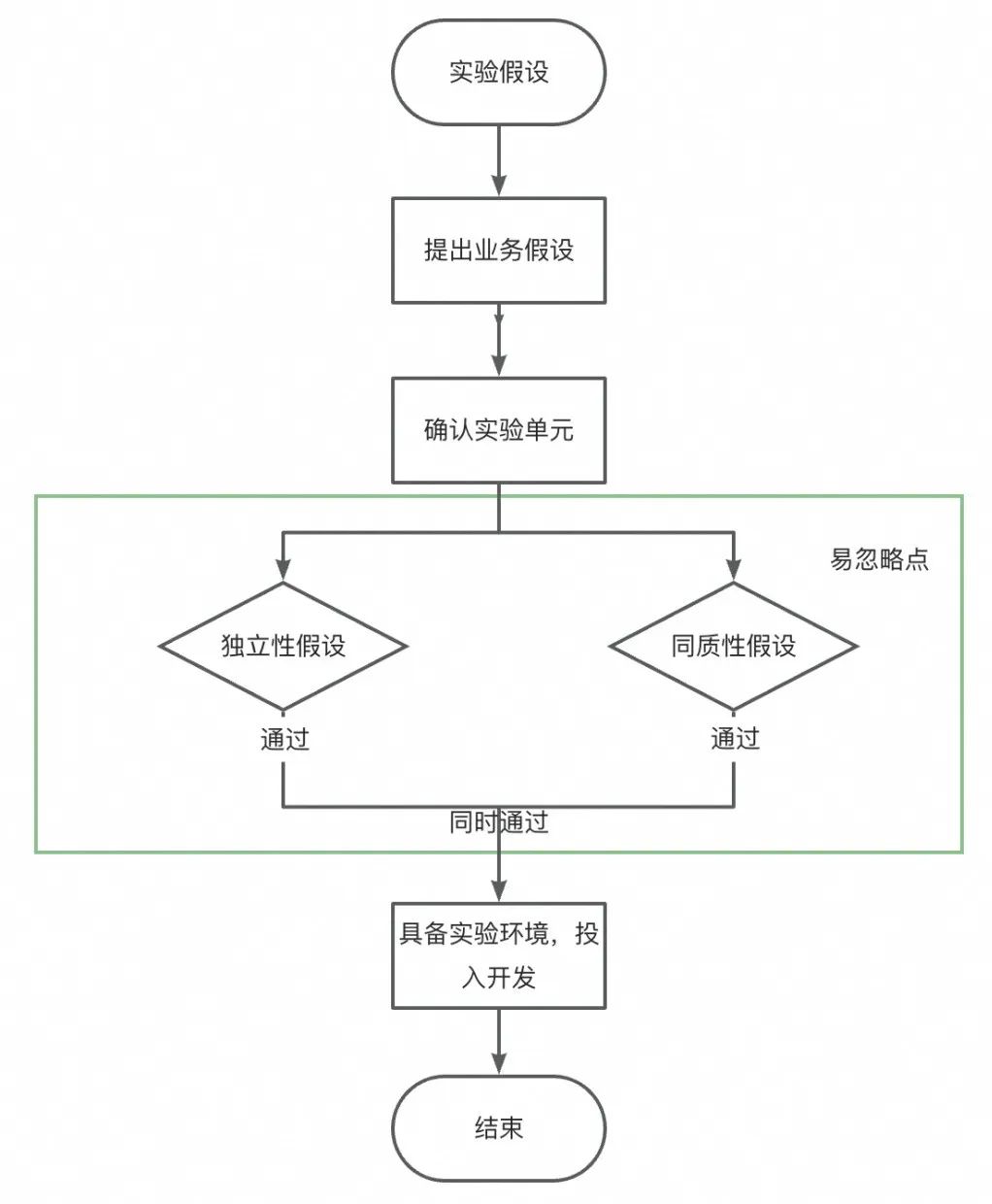
在获得可用的数据基础后,我们开始关注实验分析的问题,图示为一个简化的实验分析流程。
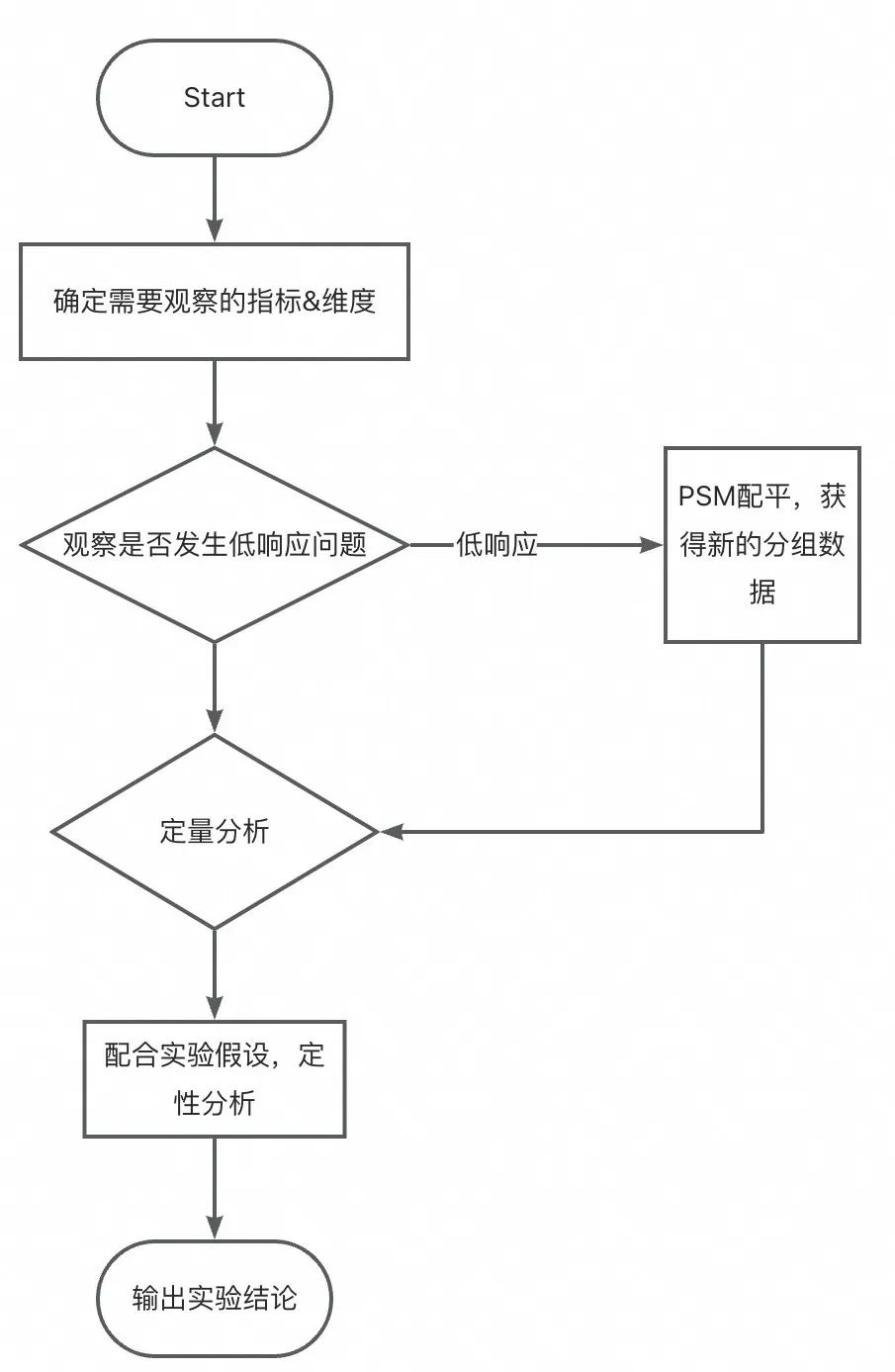
确定需要观察的指标&维度:
在上述案例中,可以发现漏看关键指标、关键维度都可能影响实验结论产出,且实际过程中实验往往需要下钻到关键维度,根据维度项里对实验的差异反应,寻找迭代方向。
▐ 案例七:「实验正确看数」在提单价的实验中,我们发现实验的GMV提升明显,但是观看时长显著降低
案例分析
由于提高了价格带,导致部分低购用户直接选择不看了,而这部分用户本身对GMV的贡献也不大,所以实验依然能够取得明显效果,然而低购群体里的较低年龄段用户他们贡献了较多的观看时长,因此该实验的观看时长也被显著降低。
因此得出一个业务经验:提单价的实验应避免波及(低GMV贡献但高观看时长贡献)的用户。
当前解法
针对不同业务背景,提前确定看数范围(指标+维度),避免经验不足引起的实验观察错误,通常这块由业务方+数据同学共同制定。
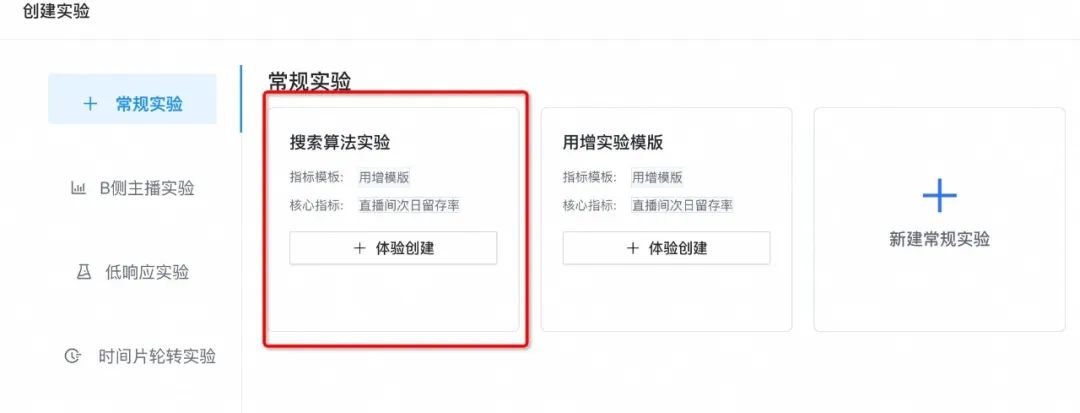
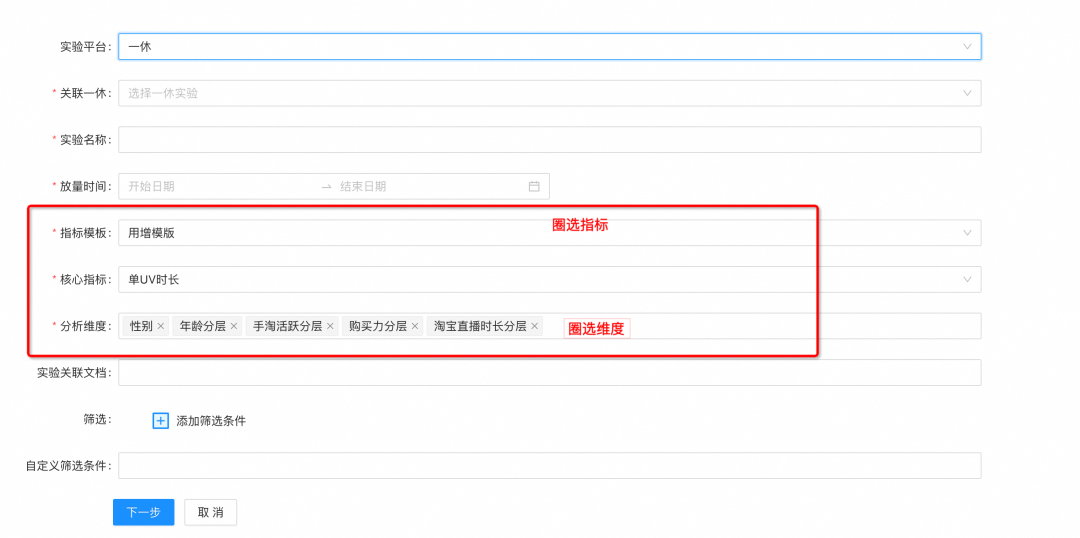
判断低响应实验
▐ 案例八:「低响应实验」活动入口做的AB实验,响应度太低无法分析实验数据。

案例分析
当前解法
▐ 定量分析
这块在第一篇文章中已经浓重介绍过,这里不再赘述。简单提及要点:没有置信度支撑的数据叫随机波动,不要当作实验结论。
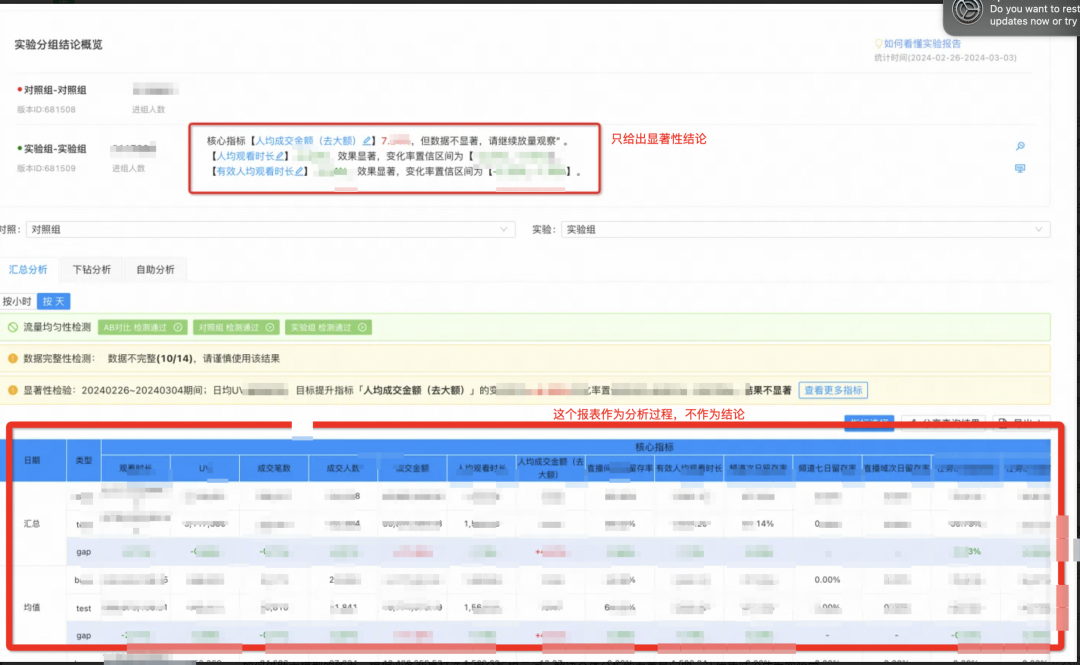
思考:

相关资料
实验推全最终会回应到业务目标达成,我在这块的推动经验较为薄弱,如何围绕业务目标建立可量化的推全标准,这需要多方的信任基础和强大的组织推力,以后补充。
感谢领导信任,让我有机会在直播业务中完善我对A/B实验的理解;感谢大佬的大力支持,感谢所有合作的产品老师、运营老师、算法老师、工程老师、数据研发老师、数据科学老师的大力支持。

技术线内容技术团队,是承接淘天内容电商最核心的技术力量,团队拥有非常全面的内容技术领域布局,不仅覆盖音视频编解码、流媒体传输、低延时直播等多媒体技术,也包含计算机视觉、自然语言处理、多模态內容理解、AIGC等人工智能领域。
在内容技术领域之外,团队拥有强大的算法、前端、客户端、服务端、测试开发、数据开发、数据科学团队、负责面向亿级消费者提供服务的淘宝直播、淘宝逛逛、点淘等核心业务场域;
面向千万级商家、品牌、机构、达人的内容创作工具、内容运营平台内容商业化解决方案;以及面向淘天集团电商板块各业务线的内容管理、内容总线等基石平台。
简历投递邮箱:[email protected]
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。