
摘要:LinkedIn 的研究团队提出了一种创新的客服自动问答架构,将检索增强生成与知识图谱完美结合,取得了惊人的效果。本文将带您深入解读这项研究的核心思路、关键技术与创新亮点,探讨知识图谱和向量数据库在智能客服领域的应用前景,展望人工智能重塑客户服务的美好未来。
作者丨Dr.Min WU Fabarta 科学顾问
01 导读
在这个数字化时代,高效、智能的客户服务已经成为企业制胜的关键。然而,面对日益增长的客户咨询量,传统的人工客服模式已然捉襟见肘。如何利用人工智能技术,打造一个能够快速、准确解答客户问题的自动问答系统,成为了业界亟待攻克的难题。
近日,一项突破性的研究为这一难题提供了崭新的解决方案。LinkedIn 的研究团队提出了一种创新的客服自动问答架构,将检索增强生成(Retrieval Augmented Generation,RAG)与知识图谱(Knowledge Graph)完美结合,取得了惊人的效果[1]。通过构建结构化的领域知识库,并引入向量数据库加速语义检索,该方案不仅使问题解决时间大幅缩短,还极大地提升了答案的相关性和准确性。
这一里程碑式的成果已发表在《Combining Retrieval Augmented Generation with Knowledge Graphs for Customer Service Question Answering》论文中,引起了工业界的广泛关注和好评。本文将带您深入解读这项研究的核心思路、关键技术与创新亮点,探讨知识图谱和向量数据库在智能客服领域的应用前景,展望人工智能重塑客户服务的美好未来。
02 研究背景与问题提出
客服自动问答一直是智能客服领域的研究热点。如何从海量的历史服务工单中快速、准确地检索出与用户问题相关的信息,并据此生成恰当的回答,是决定系统性能的关键。传统的检索增强生成方法虽然在一定程度上提高了答案的相关性,但仍然存在两个主要问题:
- 结构化信息忽略:将历史工单视为纯文本处理,忽略了其内在的结构化信息和问题之间的关联性,导致检索准确率不高。
- 信息断裂:为适应预训练语言模型的输入长度限制,往往需要对工单进行分段,这可能造成关键信息的丢失和语义的割裂,影响生成答案的完整性和连贯性。
针对以上这些问题,该论文提出了一种全新的解决方案。
03 融合知识图谱与 RAG 的技术方案
3.1 让我们先举个例子
下面这个示例描述了如何在客户服务问答系统中应用结合知识图谱和检索增强生成(RAG)的方法。这个例子将通过实际的票据数据和构建过程,展示技术实现的详细步骤。我们有以下几个示例客服票据:
- Ticket 1: ENT-101
- Log in to the account.
- Proceed to checkout.
- Enter credit card details and submit.
- Title: "User cannot complete payment using credit card"
- Description: "The user attempts to pay with a credit card but receives an error message saying 'Transaction failed'."
- Steps to Reproduce:
- Solution: "Check if the credit card information is correct and ensure that the card is not expired. If the problem persists, try using a different payment method."
- Ticket 2: ENT-102
- Click on 'Forgot Password'.
- Enter the email address and submit.
- Check the email inbox for the reset link.
- Title: "User forgot password and cannot reset"
- Description: "The user has forgotten their password and is unable to reset it because the reset email is not being received."
- Steps to Reproduce:
- Solution: "Ensure the user checks their spam folder. If the reset email is still not found, contact support for manual verification and reset."
- Ticket 3: ENT-103
- Title: "User unable to update account details"
- Description: "Attempts to update account information result in a 'Server Error' message."
- User: Alice
- Tags: [Account, Error]
- Ticket 4: ENT-104
- Title: "Server Error when updating user profile"
- Description: "Several users report a server error when they try to update their profile information."
- User: Bob
- Tags: [Profile, Error, Server]
- Ticket 5: ENT-105
- Title: "Payment processing failure"
- Description: "Payment processing fails with an error code 500."
- Related Tickets: ENT-101
- User: Alice
- Tags: [Payment, Error]
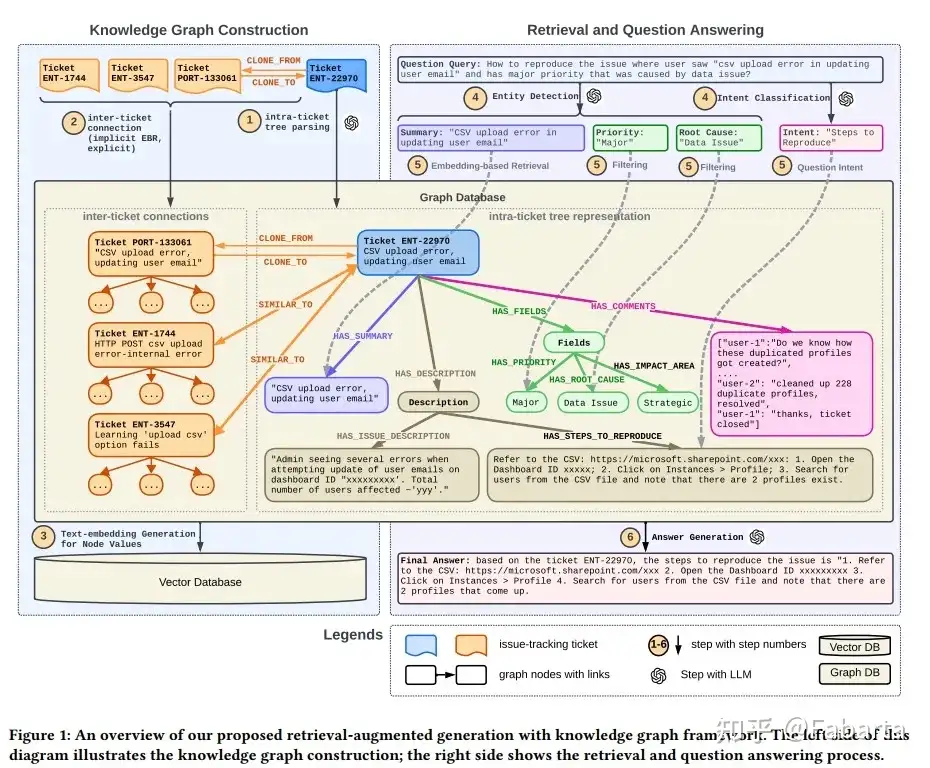
3.2 问题内部树形结构的构建:
对于每个票据,按部分(标题、描述、步骤、解决方案)创建节点。
Ticket 1: ENT-101的树形结构如下:

ENT-101
├── Title: "User cannot complete payment using credit card"
├── Description: "The user attempts to pay with a credit card but receives an error message saying 'Transaction failed'."
├── Steps to Reproduce
│ ├── Step 1: "Log in to the account."
│ ├── Step 2: "Proceed to checkout."
│ ├── Step 3: "Enter credit card details and submit."
└── Solution: "Check if the credit card information is correct and ensure that the card is not expired. If the problem persists, try using a different payment method."- Ticket 2: ENT-102 的树形结构如下:
`ENT-102
├── Title: "User forgot password and cannot reset"
├── Description: "The user has forgotten their password and is unable to reset it because the reset email is not being received."
├── Steps to Reproduce
│ ├── Step 1: "Click on 'Forgot Password'."
│ ├── Step 2: "Enter the email address and submit."
│ ├── Step 3: "Check the email inbox for the reset link."
└── Solution: "Ensure the user checks their spam folder. If the reset email is still not found, contact support for manual verification and reset."3.3 问题间的图形结构构建:
- 使用文本嵌入和余弦相似度计算不同票据标题之间的相似度,确定隐式链接。
- 建立显式链接基于业务逻辑(例如,相同用户的连续问题)。
3.3.1 基于业务逻辑的显式链接构建
显式链接是基于业务逻辑和数据中明确提到的关系来定义的。这些可以是历史关系、用户关系或任何直接在数据中指定的链接。
相同用户的连续问题:如果两个问题是由同一个用户提交的,并且主题相关,它们之间可能存在显式链接。
- Ticket 3 (ENT-103) 和 Ticket 5 (ENT-105) 都是由 Alice 提交,而且都涉及到错误消息。这种情况下,我们可以建立一个显式链接,尽管它们处理的是不同的系统部分(账户信息和支付处理)。
ENT-103 ──> ENT-105直接引用的关系:某些票据可能会直接引用其他票据作为相关问题。
- Ticket 5 (ENT-105) 明确提到了与 Ticket 1 (ENT-101) 相关。这是一个直接的显式链接。
ENT-105 ──> ENT-1013.3.2 隐式链接的构建
隐式链接是基于文本内容的语义相似度来推断的,这通常涉及到使用 NLP 和文本嵌入技术。
基于文本嵌入和余弦相似度的隐式链接构建:
- 文本嵌入技术:首先,对每个票据的标题和描述使用文本嵌入模型(如 BERT 或 E5)生成嵌入向量。
- 余弦相似度计算:计算不同票据之间标题和描述的余弦相似度。
假设我们计算的相似度如下(以简化的方式展示):
- Ticket 3 (ENT-103) 和 Ticket 4 (ENT-104):
- 标题相似度:cos(embed("User unable to update account details"), embed("Server Error when updating user profile")) = 0.78
- 描述相似度:cos(embed("Attempts to update account information result in a 'Server Error' message。"), embed("Several users report a server error when they try to update their profile information.")) = 0.85
因为两个票据的描述中都出现了 "Server Error",我们可以认为它们语义相似,建立一个隐式链接。
ENT-103 ──> ENT-104- Ticket 4 (ENT-104) 和 Ticket 5 (ENT-105):
- 标题相似度:cos(embed("Server Error when updating user profile"), embed("Payment processing failure")) = 0.45 (较低)
- 描述相似度:cos(embed("Several users report a server error when they try to update their profile information。"), embed("Payment processing fails with an error code 500.")) = 0.62
尽管标题相似度较低,描述中的错误上下文 ("server error" 和 "error code 500") 提供了一定的关联性,可以考虑建立较弱的隐式链接。
ENT-104 ──> ENT-105 (较弱)3.4 最终构建完成的知识图谱示意
将上述构建的树形结构和图形结构放在一起,我们得到一个包含显式和隐式链接的知识图谱:
Payment issue)
│
└── ENT-105 (Payment processing failure) ───┐
│ │
└── ENT-103 (Account update issue) ─────┼──> ENT-104 (Profile update issue)
│
└── ENT-101 (Referenced back to Payment issue)3.5 检索和问答过程
3.5.1 查询实体识别和意图检测
- 步骤:在用户的查询中识别关键的实体和用户的意图。这是通过解析查询并将其映射到预定义的图模板中的元素来实现的。
- 例子:对于查询 "How to reproduce the login issue where a user can’t log in to LinkedIn?",系统可能提取:
- 实体:
"issue summary"映射到"login issue","issue description"映射到"user can’t log in to LinkedIn"。 - 意图:例如
"fix solution",表明用户想要找到解决这个问题的方法。
- 实体:
这使得系统能够理解用户查询的深层意图和相关的问题部分。
3.5.2 基于嵌入的子图检索
- 基于 EBR 的票据识别:这个步骤使用从用户查询中提取的实体来找出最相关的历史问题票据。
- 使用文本嵌入(如 BERT)计算查询中的每个实体和知识图谱中相应部分的余弦相似度。
- 通过汇总这些相似度得分来识别最相关的历史票据。
这一步骤帮助系统缩小可能的问题范围,专注于与用户查询最相关的问题。
- 由 LLM 驱动的子图提取:根据上一步识别的相关票据,系统进一步提取这些票据相关的子图。
- 将用户查询转换为包含具体票据 ID 的查询,然后转换成图数据库查询语言(如 Cypher)来检索详细信息。例如,查询可能被转换成一个 Cypher 查询来获取具体步骤或信息。例如,从初始查询
"how to reproduce the issue where user saw ’csv upload error in updating user email’ with major priority due to a data issue",查询被改写为 "how to reproduce ’ENT-22970’",然后转换为 Cypher 查询
MATCH (j:Ticket {ticket_ID: ’ENT-22970’}) -[:HAS_DESCRIPTION]-> (description:Description) -[:HAS_STEPS_TO_REPRODUCE]-> (steps_to_reproduce: StepsToReproduce) RETURN steps_to_reproduce.value值得注意的是,由 LLM 驱动的查询表达足够灵活,可以跨子图检索信息,无论它们来自同一棵树还是知识图中的不同树。这一步骤使系统能够从知识图谱中提取具体的信息,为生成答案做准备。
3.5.3 答案生成
- 合成答案:使用从知识图谱中检索到的信息和原始查询来生成答案。
- LLM 用作解码器,结合检索到的数据和用户的原始查询来生成响应。
- 如果直接查询处理遇到问题,系统可以回退到更基本的文本检索方法。
这一步骤是整个问答流程的最终阶段,输出用户的问题的答案。
04 实验结果与应用实践
为验证所提出方法的有效性,研究团队在真实的客服工单数据集上进行了系统实验。实验结果表明,该方法在多个指标上均明显优于传统的 RAG 模型,例如:
- 检索性能提升:在检索阶段,平均倒数排名(MRR)和召回率(Recall@K)分别提高了 77.6%和 56%;
- 答案生成质量提高:在生成阶段,BLEU 得分从 0.057 提升至 0.377。
此外,该方法已在 LinkedIn 的实际客服系统中进行了约半年的部署应用,取得了显著成效。与未使用该系统的对照组相比,客服问题的平均解决时间缩短 64%,服务效率得到大幅提升。
表 1:检索性能
| MRR | Recall@K | NDCG@K | |||
| K | 1 | 3 | 1 | 3 | |
| 基线 | 0.522 | 0.400 | 0.640 | 0.400 | 0.520 |
| 实验 | 0.927 | 0.860 | 1.000 | 0.860 | 0.946 |
表 2:问答性能
| BLEU | METEOR | ROUGE | |
| 基线 | 0.057 | 0.279 | 0.183 |
| 实验 | 0.377 | 0.613 | 0.546 |
表 3:客户支持问题解决时间
| 平均时间 | P50 | P90 | |
| 未使用工具 | 40 小时 | 7 小时 | 87 小时 |
| 使用工具 | 15 小时 | 5 小时 | 47 小时 |
05 总结与展望
总的来看,这项研究为客服自动问答系统的优化提供了新的思路。通过知识图谱与 RAG 模型的巧妙结合,它很好地弥补了现有方法的不足,实现了检索和生成性能的双提升。展望未来,研究者还计划在以下方面进行深入探索:
- 自动化知识图谱构建:提高知识图谱构建的自动化程度,减少人工依赖;
- 知识图谱动态更新:支持知识图谱的动态更新,以适应实时变化的工单数据;
- 方案拓展:将该方案拓展至客服以外的其他领域。
相信通过学界和业界的共同努力,我们有望进一步挖掘知识图谱与 RAG 模型协同应用的潜力,推动智能客服领域的持续创新和发展。
06 精华归纳
6.1 知识图谱:化繁为简的结构化利器
传统的客服系统将工单视为无差别的文本数据,忽视了其内在的逻辑结构和语义联系,这导致信息检索的准确率难以提升。LinkedIn 团队的一大创新,就是利用知识图谱对工单数据进行了结构化、语义化的表示。
具体而言,他们将每个工单解析为一棵树状图,不同层级的节点分别对应问题的各个部分,如标题、描述、复现步骤等。更重要的是,他们进一步挖掘出不同工单之间的关联,用图结构将其连接起来。这种关联不仅包括工单间的直接引用,还包括基于文本相似度的语义关联。
通过这种方式,原本杂乱无章的工单数据被整合进一张语义连通图,其中的每个节点都具有明确的语义属性,节点间的边也呈现出丰富的语义关系。这不啻为智能客服问答提供了一座知识宝库,系统可以在其中快速找到与用户问题高度相关的知识节点,并沿着语义链接不断拓展信息的广度和深度。
6.2 向量数据库:语义检索的高速通道
构建知识图谱只是智能问答的第一步,要实现实时、高效的信息检索,还必须引入向量数据库技术。这是 LinkedIn 方案的另一大亮点。
传统的关系型数据库难以应对海量节点间复杂的语义匹配,而向量数据库则是专为相似性搜索而生。LinkedIn 团队利用预训练语言模型,如 BERT、E5 等,将知识图谱中的节点文本映射为高维语义向量,然后将这些向量存入专门优化的向量数据库。
当用户提问时,系统同样将其转化为语义向量,并在数据库中进行高速匹配运算,快速找出与之语义最相似的知识节点。由于语义向量能够充分捕获文本的语义信息,即便问题表述存在差异,也能轻松找到最相关的答案线索。
6.3 RAG 模型:知识碎片到完整答案的装配工厂
知识图谱和向量数据库的结合,让系统能快速检索到高相关的知识碎片。但要生成一个完整、连贯的答案,还需要 RAG 模型发挥关键作用。
LinkedIn 方案利用 RAG 模型的强大自然语言生成能力,将相关知识子图中提取的信息作为素材,结合用户的完整问题、动态组装和 rephrase,最终输出一个通顺、准确的答案。由于子图检索避免了对工单的简单截断,保留了必要的上下文信息,生成的答案也更加完整、连贯。
在下一篇文章中,我们将介绍微软最新的研究成果:From Local to Global: A Graph RAG Approach to Query-Focused Summarization [2]
参考文献:
[1] Xu Z, Cruz M J, Guevara M, et al. Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering[J]. arXiv preprint arXiv:2404.17723, 2024.
[2] Edge D, Trinh H, Cheng N, et al. From Local to Global: A Graph RAG Approach to Query-Focused Summarization[J]. arXiv preprint arXiv:2404.16130, 2024.
《庆余年2》盗版资源被上传到 npm,导致 npmmirror 不得已暂停 unpkg 服务 Windows 11 将在中国区设备上安装「微软电脑管家」 新款 iPad Pro 使用了 12GB 内存颗粒,但却声称是 8GB 内存 Linus “吃狗粮”最积极! Kotlin 2.0.0 稳定版发布,K2 编译器已稳定 macOS 终端工具 iTerm2 发布重大更新 3.5.0:集成 ChatGPT、让 AI 帮你写命令 通义千问 GPT-4 级主力模型降价 97%,1 块钱 200 万 tokens 微软 Windows 过渡到 Arm 架构的核心组件 —— “Prism”模拟器 开源日报 | Kotlin 2.0.0;简体中文压缩数据只有6TB;AI不是核弹;全球首个开源大规模"NoC IP";华为有哪些能力是当前不可代替的? 没人能顶得住寡姐的声音,包括 Sam Altman