solr是国外的人做的一个提供关键字搜索的一个功能,所以对中文不支持,于是国人就自己做了一个IKAnalyzer,但是Ik分词也不一定能分到自己想要的词,也就是说词库里面的组词不一定是符合自己的词,但是他们留了后门,可以自己管理词库的,操作步骤如下:
1.下载Ik包 IK Analyzer2012FF ,可以看出这个包已经很久没有出新版本了
2.在schema.xml文件中添加IK分词。schema.xml的由来之前说过,是managed-schema文件的化身,所以他们两个文件要保持一直
<!-- 我添加的IK分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
3.前面的搭建环境,这里不再重复介绍了。在solr的tomcat中,webapp/solr/WEB-INF/classes/把IK的xml放进去----》IKAnalyzer.cfg.xml 里面的配置如下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
然后在IKAnalyzer.cfg.xml的同级目录也就是classes下面创建ext.dic,ext.dic里面就可以添加自己的词库。
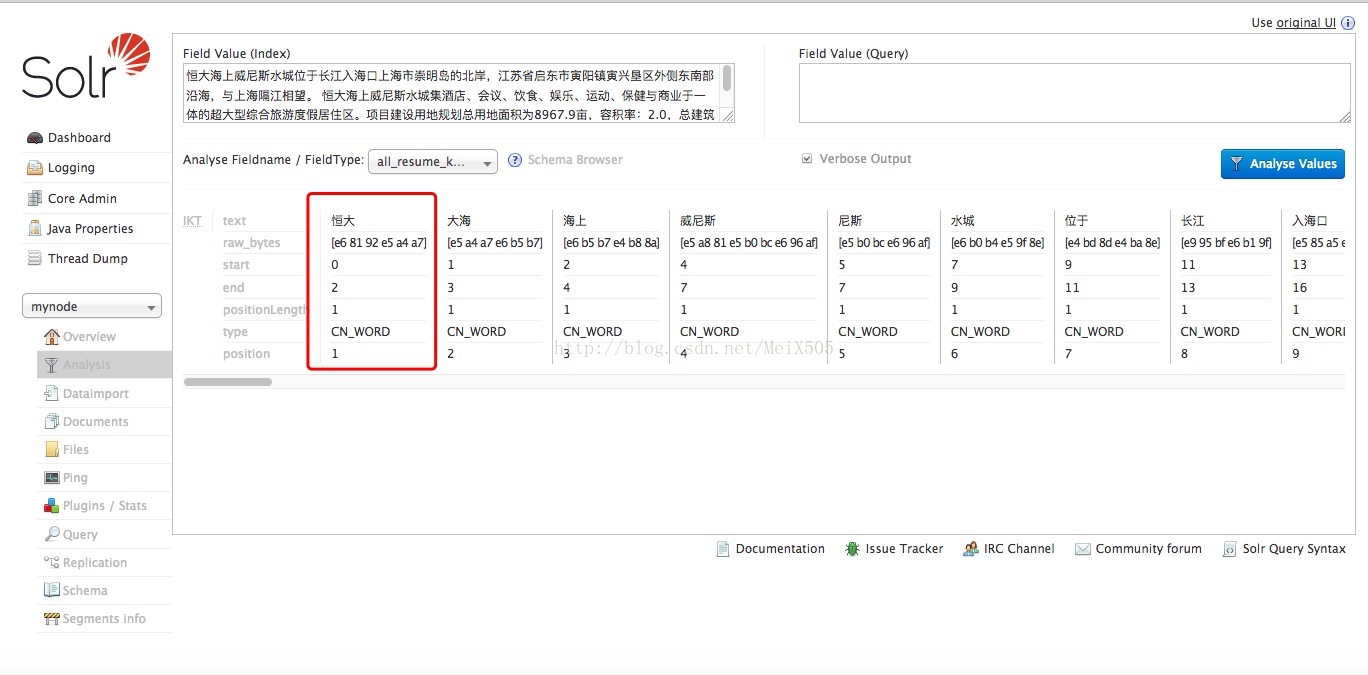
以前“恒大”这个词被分出来,只有一个“恒”,这次我把“恒大”加进了ext.dic里面然后在solr的管理界面中使用配置了text_ik类型的字段分词,可以看到是分出来了