在这篇文章中来看看线程安全的ConcurrentHashMap。
讲到Map结构,我想应该都会知道HashTable和HashMap,但是这两者有什么区别呢?HashTable是线程安全的Map数据结构,因为它内部的操作方法都是通过synchronized关键字进行修饰的,确保了并发情况下不会对元素操作存在冲突。而HashMap是非线程安全的,在并发读取的情况下存在死循环的问题,这在另一篇文章《HashMap死循环问题》中已经对这个问题进行了简单的说明。
那么这里为什么要说ConcurrentHashMap呢?直接用HashTable和HashMap不就可以了吗?
答案是:HashTable的线程安全是重型的,是通过关键字synchronized和虚拟机来实现的,高并发情况下性能上存在一定问题。而HashMap又存在线程安全问题,因此在JDK中提供了另一种优化的线程安全的Map结构,那就是ConcurrentHashMap,既可以达到线程安全的目的,又没有使用synchronized来实现并发控制,而是使用在代码层面加锁进行控制,弱化了加锁的粒度,增强了并发下的性能。
下面以JDK1.7中ConcurrentHashMap实现来进行说明。之所以指明JDK版本,是因为不同版本下该类的实现略有不同。
ConcurrentHashMap实现原理
JDK1.7中的实现
我们知道HashTable中是对整个table进行加锁的,这在数据量比较多的情况下很明显是不合适的,因为在对一个数据进行操作的过程中直接影响其他元素的处理。因此在ConcurrentHashMap中采用了一种称为锁分段的技术,即table中不同段的数据采用不同的锁进行控制,相互之间没有影响,减小了锁控制的范围,从而增强了并发下的读写性能。
在JDK1.7中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
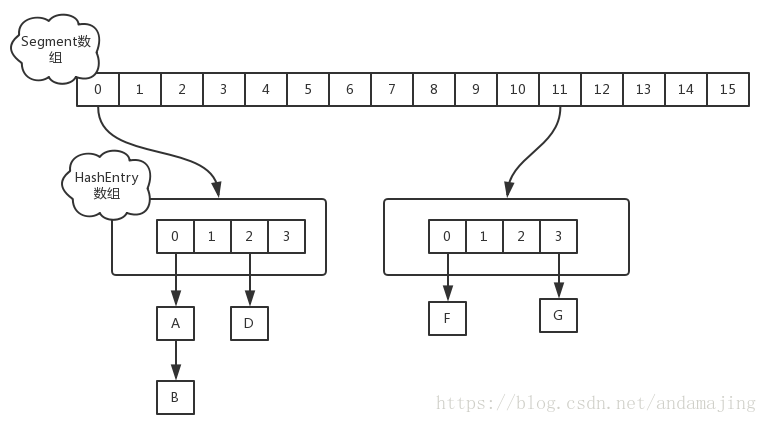
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
初始化过程
ConcurrentHashMap的初始化代码如下所示,通过位运算来初始化segment数组的大小ssize,因此ssize一定是2的N次方;另外concurrencyLevel最大只能是16,即segment数组的大小最大只能是63336。对于每个segment下的HashEntry数组,每个数组的大小也是2的N次方。
/**
* Creates a new, empty map with the specified initial
* capacity, load factor and concurrency level.
*
* @param initialCapacity the initial capacity. The implementation
* performs internal sizing to accommodate this many elements.
* @param loadFactor the load factor threshold, used to control resizing.
* Resizing may be performed when the average number of elements per
* bin exceeds this threshold.
* @param concurrencyLevel the estimated number of concurrently
* updating threads. The implementation performs internal sizing
* to try to accommodate this many threads.
* @throws IllegalArgumentException if the initial capacity is
* negative or the load factor or concurrencyLevel are
* nonpositive.
*/
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
从源代码中可以看到,在初始化过程中需要注意的是并不是在ConcurrentHashMap创建的时候就把所有的segment进行了初始化,这里只初始化了一个segment,那就是s0变量,而后在对这个容器操作过程中根据需要动态创建其他的segment。
put操作
对于数据插入,需要进行两次hash操作来定位元素的最终插入位置,一次是定位segment,一次是定位在此segment下相应的HashEntry数组元素索引位置。
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
如上代码所示,首先根据key的hash值来判断其应该插入的segment元素在segments数组的下标位置j,如果segments[j]元素还没有,那么调用ensureSegment(j)来初始化这个segment元素。之后调用segment的put方法来完成在segment的HashEntry数组中插入该元素key。
Segment类中的put操作逻辑如下:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
从代码可以看出,整个操作过程中都是在锁的保护下进行的。先通过第一次计算的hash值和HashEntry数组的长度进行与运算得到该元素在HashEntry数组中的索引下表,紧接着从该索引位置取其对应的链表元素。如果没有元素就初始化一个链表,如果有则从链表头结点开始遍历判断是否插入元素是已有的元素,如果是,则直接跳出返回旧元素。
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。
源码如下:
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
从源码看,它先通过hash(key)找到segments数组中相应的segment索引下标h,然后判断该segments中是否有元素,如果没有直接返回null;如果有获取相应的HashEntry数组,并且通过再一次的hash计算得到相应的元素在HashEntry数组中的索引下标,并取出相应的元素列表,之后遍历这个列表中的元素,跟请求参数中的key进行对比,找到合适的元素返回或者因遍历整个链表而找不到最终返回null。
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),我们来看看JDK1.7中是如何解决这个问题的。
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
这里首先使用不加锁模式下来计算各个segment下的元素个数并进行累加,比较前后计算两次并对两次计算结果进行比对,如果是一样的,则认为中间没有元素插入,计算结果就是最终的容器的元素的个数;如果两次结果不一样,则再次计算一次,和上一次计算结果进行比对,直到两次结果相同或者超过最大重试次数(3次,即在第一次计算容器元素个数后,后面最多还会重试3次计算容器元素个数并比较是否和上一次计算结果相等),当超过最大重试次数之后,认为情况下是因为并发些操作比较多,这时候会将整个容器的所有segment进行加锁,防止再往容器中新增元素,之后进行统计元素个数,并在统计完之后释放各个锁。
在JDK1.8中,已经摒弃了segment的概念,转而使用Node数组+链表+红黑树的数据结构,并发控制上则使用synchronized关键字和CAS来操作。关于JDK1.8中ConcurrentHashMap的实现感兴趣的读者可以自己看看源码。
感谢大家的阅读,如果有对Java编程、中间件、数据库、及各种开源框架感兴趣,欢迎关注我的博客和头条号(源码帝国),博客和头条号后期将定期提供一些相关技术文章供大家一起讨论学习,谢谢。
如果觉得文章对您有帮助,欢迎给我打赏,一毛不嫌少,一百不嫌多,^_^谢谢。
