# Imports for data io operations
from collections import deque
from six import next
# Main imports for training
import tensorflow as tf
import numpy as np
# Evaluate train times per epoch
import time
from __future__ import absolute_import, division, print_function
import pandas as pd
def read_file(filname, sep="\t"):
col_names = ["user", "item", "rate", "st"]
df = pd.read_csv(filname, sep=sep, header=None, names=col_names, engine='python')
df["user"] -= 1
df["item"] -= 1
for col in ("user", "item"):
df[col] = df[col].astype(np.int32)
df["rate"] = df["rate"].astype(np.float32)
return df
class ShuffleIterator(object):
def __init__(self, inputs, batch_size=10):
self.inputs = inputs
self.batch_size = batch_size
self.num_cols = len(self.inputs)
self.len = len(self.inputs[0])
self.inputs = np.transpose(np.vstack([np.array(self.inputs[i]) for i in range(self.num_cols)]))
def __len__(self):
return self.len
def __iter__(self):
return self
def __next__(self):
return self.next()
def next(self):
ids = np.random.randint(0, self.len, (self.batch_size,))
out = self.inputs[ids, :]
return [out[:, i] for i in range(self.num_cols)]
class OneEpochIterator(ShuffleIterator):
def __init__(self, inputs, batch_size=10):
super(OneEpochIterator, self).__init__(inputs, batch_size=batch_size)
if batch_size > 0:
self.idx_group = np.array_split(np.arange(self.len), np.ceil(self.len / batch_size))
else:
self.idx_group = [np.arange(self.len)]
self.group_id = 0
def next(self):
if self.group_id >= len(self.idx_group):
self.group_id = 0
raise StopIteration
out = self.inputs[self.idx_group[self.group_id], :]
self.group_id += 1
return [out[:, i] for i in range(self.num_cols)]# Constant seed for replicating training results
np.random.seed(42)
u_num = 6040 # Number of users in the dataset
i_num = 3952 # Number of movies in the dataset
batch_size = 1000 # Number of samples per batch
dims = 5 # Dimensions of the data, 15
max_epochs = 50 # Number of times the network sees all the training data
# Device used for all computations
place_device = "/cpu:0"def get_data():
# Reads file using the demiliter :: form the ratings file
# Download movie lens data from: http://files.grouplens.org/datasets/movielens/ml-1m.zip
# Columns are user ID, item ID, rating, and timestamp
# Sample data - 3::1196::4::978297539
df = read_file("ratings.dat", sep="::")
rows = len(df)
# Purely integer-location based indexing for selection by position
df = df.iloc[np.random.permutation(rows)].reset_index(drop=True)#随机排列id顺序
# Separate data into train and test, 90% for train and 10% for test
split_index = int(rows * 0.9)
# Use indices to separate the data
df_train = df[0:split_index]#划分训练集
df_test = df[split_index:].reset_index(drop=True)#划分测试集
return df_train, df_test
def clip(x):
return np.clip(x, 1.0, 5.0)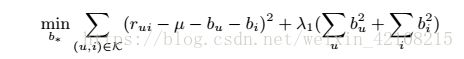
def model(user_batch, item_batch, user_num, item_num, dim=5, device="/cpu:0"):
with tf.device("/cpu:0"):
# Using a global bias term
bias_global = tf.get_variable("bias_global", shape=[])
# User and item bias variables
# get_variable: Prefixes the name with the current variable scope
# and performs reuse checks.
w_bias_user = tf.get_variable("embd_bias_user", shape=[user_num])
w_bias_item = tf.get_variable("embd_bias_item", shape=[item_num])
# embedding_lookup: Looks up 'ids' in a list of embedding tensors
# Bias embeddings for user and items, given a batch
bias_user = tf.nn.embedding_lookup(w_bias_user, user_batch, name="bias_user")
bias_item = tf.nn.embedding_lookup(w_bias_item, item_batch, name="bias_item")
# User and item weight variables
w_user = tf.get_variable("embd_user", shape=[user_num, dim],
initializer=tf.truncated_normal_initializer(stddev=0.02))
w_item = tf.get_variable("embd_item", shape=[item_num, dim],
initializer=tf.truncated_normal_initializer(stddev=0.02))
# Weight embeddings for user and items, given a batch
embd_user = tf.nn.embedding_lookup(w_user, user_batch, name="embedding_user")
embd_item = tf.nn.embedding_lookup(w_item, item_batch, name="embedding_item")
with tf.device(device):
# reduce_sum: Computes the sum of elements across dimensions of a tensor
infer = tf.reduce_sum(tf.multiply(embd_user, embd_item), 1)
infer = tf.add(infer, bias_global)
infer = tf.add(infer, bias_user)
infer = tf.add(infer, bias_item, name="svd_inference")
# l2_loss: Computes half the L2 norm of a tensor without the sqrt
regularizer = tf.add(tf.nn.l2_loss(embd_user), tf.nn.l2_loss(embd_item),
name="svd_regularizer")
return infer, regularizerdef loss(infer, regularizer, rate_batch, learning_rate=0.1, reg=0.1, device="/cpu:0"):
with tf.device(device):
# Use L2 loss to compute penalty
cost_l2 = tf.nn.l2_loss(tf.sub(infer, rate_batch))#数据上的损失
penalty = tf.constant(reg, dtype=tf.float32, shape=[], name="l2")#正则化的损失
cost = tf.add(cost_l2, tf.mul(regularizer, penalty))
# 'Follow the Regularized Leader' optimizer
# Reference: http://www.eecs.tufts.edu/~dsculley/papers/ad-click-prediction.pdf
train_op = tf.train.FtrlOptimizer(learning_rate).minimize(cost)
return cost, train_op# Read data from ratings file to build a TF model
df_train, df_test = get_data()
samples_per_batch = len(df_train) // batch_size
print("Number of train samples %d, test samples %d, samples per batch %d" %
(len(df_train), len(df_test), samples_per_batch))# Using a shuffle iterator to generate random batches, for training
iter_train = ShuffleIterator([df_train["user"],
df_train["item"],
df_train["rate"]],
batch_size=batch_size)
# Sequentially generate one-epoch batches, for testing
iter_test = OneEpochIterator([df_test["user"],
df_test["item"],
df_test["rate"]],
batch_size=-1)
user_batch = tf.placeholder(tf.int32, shape=[None], name="id_user")
item_batch = tf.placeholder(tf.int32, shape=[None], name="id_item")
rate_batch = tf.placeholder(tf.float32, shape=[None])
infer, regularizer = model(user_batch, item_batch, user_num=u_num, item_num=i_num, dim=dims, device=place_device)
_, train_op = loss(infer, regularizer, rate_batch, learning_rate=0.10, reg=0.05, device=place_device)saver = tf.train.Saver()
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print("%s\t%s\t%s\t%s" % ("Epoch", "Train Error", "Val Error", "Elapsed Time"))
errors = deque(maxlen=samples_per_batch)
start = time.time()
for i in range(max_epochs * samples_per_batch):
users, items, rates = next(iter_train)
_, pred_batch = sess.run([train_op, infer], feed_dict={user_batch: users,
item_batch: items,
rate_batch: rates})
pred_batch = clip(pred_batch)
errors.append(np.power(pred_batch - rates, 2))
if i % samples_per_batch == 0:
train_err = np.sqrt(np.mean(errors))
test_err2 = np.array([])
for users, items, rates in iter_test:
pred_batch = sess.run(infer, feed_dict={user_batch: users,
item_batch: items})
pred_batch = clip(pred_batch)
test_err2 = np.append(test_err2, np.power(pred_batch - rates, 2))
end = time.time()
print("%02d\t%.3f\t\t%.3f\t\t%.3f secs" % (i // samples_per_batch, train_err, np.sqrt(np.mean(test_err2)), end - start))
start = end
saver.save(sess, './save/')打印结果:
Epoch Train Error Val Error Elapsed Time 00 2.805 2.793 0.030 secs 01 1.304 0.981 1.585 secs 02 0.941 0.933 1.582 secs 03 0.907 0.913 1.652 secs 04 0.891 0.903 1.560 secs 05 0.882 0.897 1.756 secs 06 0.876 0.893 1.606 secs 07 0.872 0.890 1.553 secs 08 0.869 0.888 1.553 secs 09 0.866 0.886 1.686 secs 10 0.864 0.884 1.694 secs 11 0.861 0.883 1.610 secs 12 0.859 0.882 1.724 secs 13 0.857 0.881 1.563 secs 14 0.857 0.880 1.685 secs 15 0.855 0.879 1.683 secs 16 0.853 0.878 1.612 secs 17 0.851 0.876 1.676 secs 18 0.851 0.876 1.699 secs 19 0.849 0.875 1.623 secs 20 0.846 0.874 1.683 secs 21 0.845 0.873 1.726 secs 22 0.843 0.872 1.600 secs 23 0.843 0.871 1.559 secs 24 0.842 0.871 1.610 secs 25 0.841 0.870 1.579 secs 26 0.839 0.869 1.596 secs 27 0.840 0.868 1.578 secs 28 0.838 0.868 1.763 secs 29 0.837 0.868 1.557 secs 30 0.836 0.868 1.660 secs 31 0.836 0.867 1.805 secs 32 0.834 0.867 1.815 secs 33 0.833 0.866 1.687 secs 34 0.832 0.866 1.662 secs 35 0.832 0.866 1.724 secs 36 0.832 0.865 1.563 secs 37 0.832 0.865 1.565 secs 38 0.831 0.865 1.557 secs 39 0.830 0.864 1.562 secs 40 0.828 0.864 1.730 secs 41 0.829 0.864 2.110 secs 42 0.829 0.864 1.669 secs 43 0.828 0.863 1.820 secs 44 0.827 0.863 2.120 secs 45 0.827 0.863 1.981 secs 46 0.826 0.862 1.638 secs 47 0.826 0.863 1.675 secs 48 0.827 0.863 1.702 secs 49 0.825 0.862 1.668 secs