无论何时我们想对一个对象添加额外的功能,都有下面这些不同的可选方法。
- 如果合理,可以直接将功能添加到对象所属的类(例如,添加一个新的方法)
- 使用组合
- 使用继承
与继承相比,通常应该优先选择组合,因为继承使得代码更难复用,继承关系是静态的,并且应用于整个类以及这个类的所有实例。
设计模式为我们提供第四种可选方法,以支持动态地(运行时)扩展一个对象的功能,这种方法就是修饰器。修饰器(Decorator)模式能够以透明的方式(不会影响其他对象)动态地将功能添加到一个对象中。
在许多编程语言中,使用子类(继承)来实现修饰器模式。在Python中,我们可以(并且应该)使用内置的修饰器特性。一个Python修饰器就是对Python语法的一个特定改变,用于扩展一个类、方法或函数的行为,而无需使用继承。从实现的角度来说,Python修饰器是一个可调用对象(函数、方法、类),接受一个函数对象fin作为输入,并返回另一个函数对象fout。这意味着可以将任何具有这些属性的可调用对象当做一个修饰器。
修饰器模式和Python修饰器之间并不是一对一的等价关系。Python修饰器能做的实际上比修饰器模式多得多,其中之一就是实现修饰器模式。
现实生活的例子
该模式虽名为修饰器,但这并不意味着它应该只用于让产品看起来更漂亮。修饰器模式通常用于扩展一个对象的功能。这类扩展的实际例子有,给枪加一个消音器。
软件的例子
Django框架大量地使用修饰器,其中一个例子是视图修饰器。Django的试图(View)修饰器可用于以下几种用途。
- 限制某些HTTP请求对视图的访问
- 控制特定视图上的缓存行为
- 按单个视图控制压缩
- 基于特定HTTP请求头控制缓存
Grok框架也使用修饰器来实现不同的目标,比如:
- 将一个函数注册为事件订阅者
- 以特定权限保护一个方法
- 实现适配器模式
应用案例
当用于实现横切关注点(cross-cutting concerns)时,修饰器模式会大显神威。以下是横切关注点的一些例子。
- 数据校验
- 事务处理(这里类似数据库事务,要么所有步骤都成功完成,要么事务失败)
- 缓存
- 日志
- 监控
- 调试
- 业务规则
- 压缩
- 加密
一般来说,应用中有些部件是通用的,可应用于其他部件,这样的部件被看做横切关注点。
使用修饰器模式的另一个常见例子是图形用户界面(Graphical User Interface,GUI)工具集。在一个GUI工具集中,我们希望能够将一些特性,比如边框、阴影、颜色以及滚屏,添加到单个组件/部件。
实现
Python修饰器通用并且非常强大。你可以在Python官网的修饰器代码库页面中找到许多修饰器的实用样例。这里,我们将学习如何实现一个memoization修饰器。所有递归函数都能因memoization而提速,那么来试试常用的斐波那契数列例子。实用递归算法实现菲波那切数列,直截了当,但性能问题较大,即使对于很小的数值也是如此。首先来看看朴素的实现方法(文件fibonacci_naive.py)。
def fibonacci(n):
assert (n>=0), 'n must be >= 0'
return n if n in (0,1) else fibonacci(n-1)+fibonacci(n-2)
if __name__=='__main__':
from timeit import Timer
t=Timer('fibonacci(8)','from __main__ import fibonacci')
print(t.timeit())
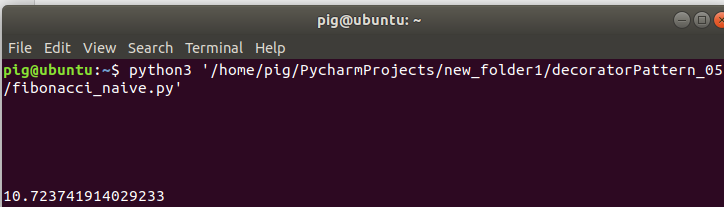
计算8个斐波那契数要花费11秒,实用memoization方法看看能否改善。在下面的代码中,我们使用一个dict来缓存斐波那契数列中已经计算好的数值,同时也修改传给fabonacci()函数的参数,计算第100个菲波那切数,而不是第8个(文件fibonacci.py)。
known={0:0,1:1}
def fibonacci(n):
assert (n>=0), 'n must be >= 0'
if n in known:
return known[n]
res=fibonacci(n-1)+fibonacci(n-2)
known[n]=res
return res
if __name__=='__main__':
from timeit import Timer
t=Timer('fibonacci(100)','from __main__ import fibonacci')
print(t.timeit())

执行基于memoization的代码实现,可以看到性能得到了极大的提升,但代码也没有不使用memoization时那样简洁。如果我们决定扩展代码,加入更多的数学函数,并将其转变为一个模块,那又会是什么样?假设决定加入的下一个函数是nsum(),该函数返回前n个数字的和。注意这个函数已存在于math模块中,名为fsum(),但这不必在意。使用memoization实现nsum()函数的代码如下。
known_sum={0:0}
def nsum(n):
assert (n>=0), 'n must be >= 0'
if n in known_sum:
return known_sum[n]
res=n+nsum(n-1)
known_sum[n]=res
return res你有没有注意到其中的问题?多了一个名为known_sum的字典,为nsum提供缓存,并且函数本身也比不适用memoization时更复杂。这个模块逐步变得不必要地复杂。保持递归函数与朴素版本的一样简单,但性能又与使用memoization相近,这可能吗?幸运的是,确实可能,解决方案就是使用修饰器模式。
首先创建一个如下面的例子所示的memoize()函数。这个修饰器接受一个需要使用memoization的函数fn作为输入,使用一个名为known的dict作为缓存。函数functools.wraps()是一个为创建修饰器提供便利的函数;虽不强制,但推荐使用,因为它能保留被修饰函数的文档和签名。这种情况要求参数列表*args,因为被修饰的函数可能有输入参数。如果fibonacci()和nsum()不需要任何参数,那么使用*args确实是多余的,但它们是需要参数n的。
import functools
def memoize(fn):
known=dict()
@functools.wraps(fn)
def memoizer(*args):
if args not in known:
known[args]=fn(*args)
return known[args]
return memoizer现在,对朴素版本的函数应用memoize()修饰器。这样既能保持代码的可读性又不影响性能。我们通过修饰(或修饰行)来应用一个修饰器。修饰使用@name语法,其中name是指我们想要使用的修饰器的名称。这其实只不过是一个简化修饰器使用的语法糖。下面对我们的递归函数使用memoize()修饰器。
@memoize
def nsum(n):
'''返回前n个数字的和'''
assert (n>=0), 'n must be >=0'
return 0 if n==0 else n+nsum(n)
@memoize
def fibonacci(n):
'''返回斐波那契数列的第n个数'''
assert (n>=0),'n must be >=0'
return n if n in (0,1) else fibonacci(n-1)+fibonacci(n-2)代码的最后一部分展示如何使用被修饰的函数,并测量其性能。measure是一个字典列表,用于避免代码重复。注意__name__和__doc__分别是如何展示正确的函数名称和文档字符串值的。尝试从memoize()中删除@functools.wraps(fn)修饰,看看是否仍旧如此(答案是无法显示函数名称和文档字符串)。
if __name__ == '__main__':
from timeit import Timer
measure = [{'exec': 'fibonacci(100)', 'import': 'fibonacci',
'func': fibonacci}, {'exec': 'nsum(200)', 'import': 'nsum',
'func': nsum}]
for m in measure:
t = Timer('{}'.format(m['exec']), 'from __main__ import {}'.format(m['import']))
print('name: {}, doc: {}, executing: {}, time: {}'.format(
m['func'].__name__, m['func'].__doc__, m['exec'], t.timeit()
))
看看我们数学模块的完整代码(mymath.py)和执行的样例输出。

Q1:多个修饰器时,执行顺序如何?
Answer:文件question.py
输出:
outer start
inner start
10
inner end
outer endQ2:修饰器能否有参数?
Answer:可以有参数,例如这个例子True就返回被修饰的函数f,False返回不修饰的原函数。question02.py
参考文献:https://pythonconquerstheuniverse.wordpress.com/2012/04/29/python-decorators/