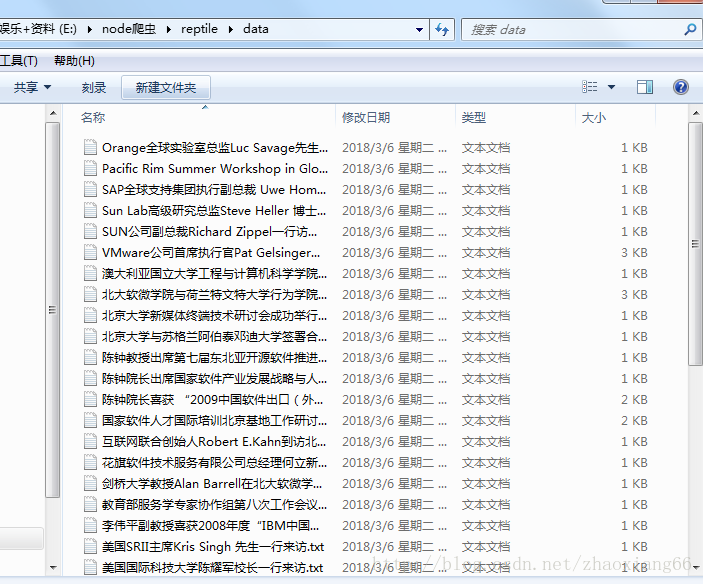
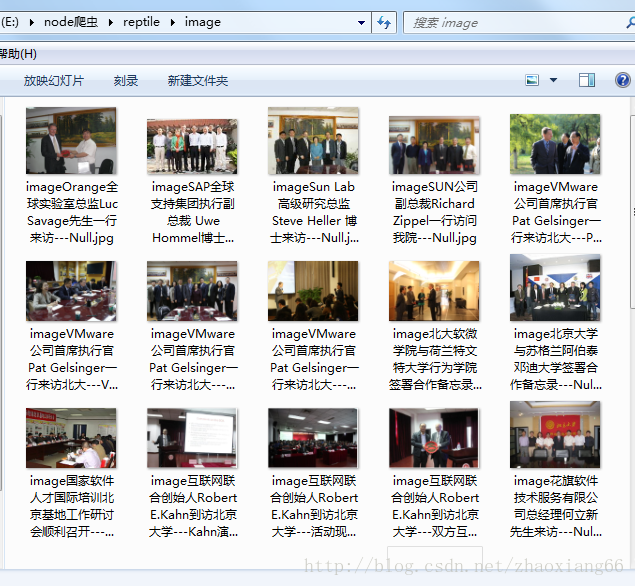
今天突然心血来潮,不如我用nodejs写一个小爬虫吧,nodejs说实话,自从它出生以来,就变成了前端的福音了,我也是一直想学,也曾经自己研究过一段时间,可是我没用到过项目上,爬虫也没写过,我就上网看着大神给的例子,然后一字一句的给敲出来,说实话,一字一句的敲出来,对爬虫的认识又增加一步,有点激动,下面说说我怎么写的吧
首先用nodejs初始化一个package.json,然后下载上需要用的包,下面是下载好的文件
{
"name": "pachong",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"cheerio": "^1.0.0-rc.2",
"request": "^2.83.0"
}
}然后开始爬去网页,我就不一 一解释了,注释里面都有解释,大家直接看代码吧
var http = require('http');
var fs = require('fs');
var cheerio = require('cheerio');
var request = require('request');
var i = 0;
var url = "http://www.ss.pku.edu.cn/index.php/newscenter/news/2391";//初始url
function fetchPage(x){
startRequest(x);
}
function startRequest(x){
//采用http模块向服务器发送一次get请求
http.get(x,function(res){
var html = "";//用来存储请求网页的整个html内容
var titles = [];
res.setEncoding('utf-8');//防止中文乱码
//监听data事件,每次取一块数据
res.on('data',function(chunk){
html += chunk;
})
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on("end",function(){
var $ = cheerio.load(html);//采用cheerio模块解析html
var time = $('.article-info a:first-child').next().text().trim();
var news_item = {
//获取文章标题
title : $('div.article-title a').text().trim(),
//获取文章发布时间
Time : time,
//获取当前文章的url
link : "http://www.ss.pku.edu.cn" + $("div.article-title a").attr('href'),
//获取供稿单位
author:$('[title = 供稿]').text().trim(),
//i是用来判断获取了多少篇文章
i : i = i + 1
};
console.log(news_item)//打印新闻信息
var news_title = $('div.article-title a').text().trim();
savedContent($,news_title);//储存每篇文章的内容及文章标题
saveImg($,news_title);//储存每篇文章的图片及图片标题
//下一篇文章的url
var nextLink="http://www.ss.pku.edu.cn" + $("li.next a").attr('href');
var str1 = nextLink.split('-');//去掉url后面的中文
var str = encodeURI(str1[0]);
if (i <= 500) {
fetchPage(str);
}
})
}).on('error',function(err){
console.log(err);
})
}
//该函数作用:在本地存储爬取的新闻内容资源
function savedContent($,news_title){
$('.article-content p').each(function(index,item){
var x = $(this).text();
var y = x.substring(0,2).trim();
if(y == ''){
x = x + '\n';
//将新闻文本内容一段一段添加到/data文件下,并用新闻的标题来命名文件
fs.appendFile('./data/' + news_title + '.txt',x,'utf-8',function(err){
if(err){
console.log(err);
}
})
}
})
}
//该函数的作用是在本地存储所爬取到的图片资源
function saveImg($,news_title){
$('.article-content img').each(function(index,item){
var img_title = $(this).parent().next().text().trim();//获取图片标题
if(img_title.length>35||img_title==""){
img_title="Null";
}
var img_filename = img_title + '.jpg';
var img_src = 'http://www.ss.pku.edu.cn' + $(this).attr('src'); //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}
});
request(img_src).pipe(fs.createWriteStream('./image/' + news_title + '---' + img_filename));
})
}
fetchPage(url);我是看了这位大神的博客,写完之后有所顿悟
http://blog.csdn.net/yezhenxu1992/article/details/50820629劝告各位,还是一句一句跟着敲吧,如果单纯的复制粘贴,一点东西都学不到!我就是一句一句敲下来的,小爬虫也不是那么难嘛,哈哈!!!
下面是我的项目demo的目录结构
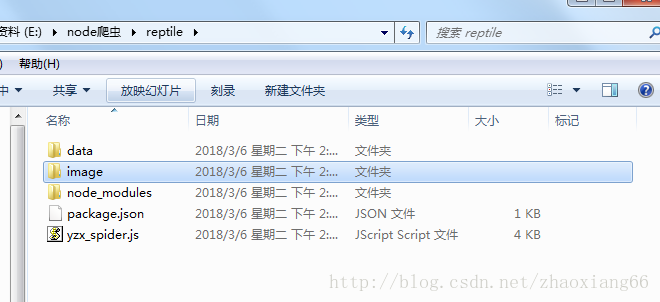
下面是运行后的结果