前言:闲来无事,觉得爬虫技术很高大上,于是小小的研究了一下。
网上查过资料后发现java爬虫也是有很多种类的,可以使用比较成熟的框架。我这里使用的是jsoup,简单粗暴的一种技术。
先做来个简单的demo:
先找一个简单点的网页,就这个了,读者杂志,文章还是很不错的。
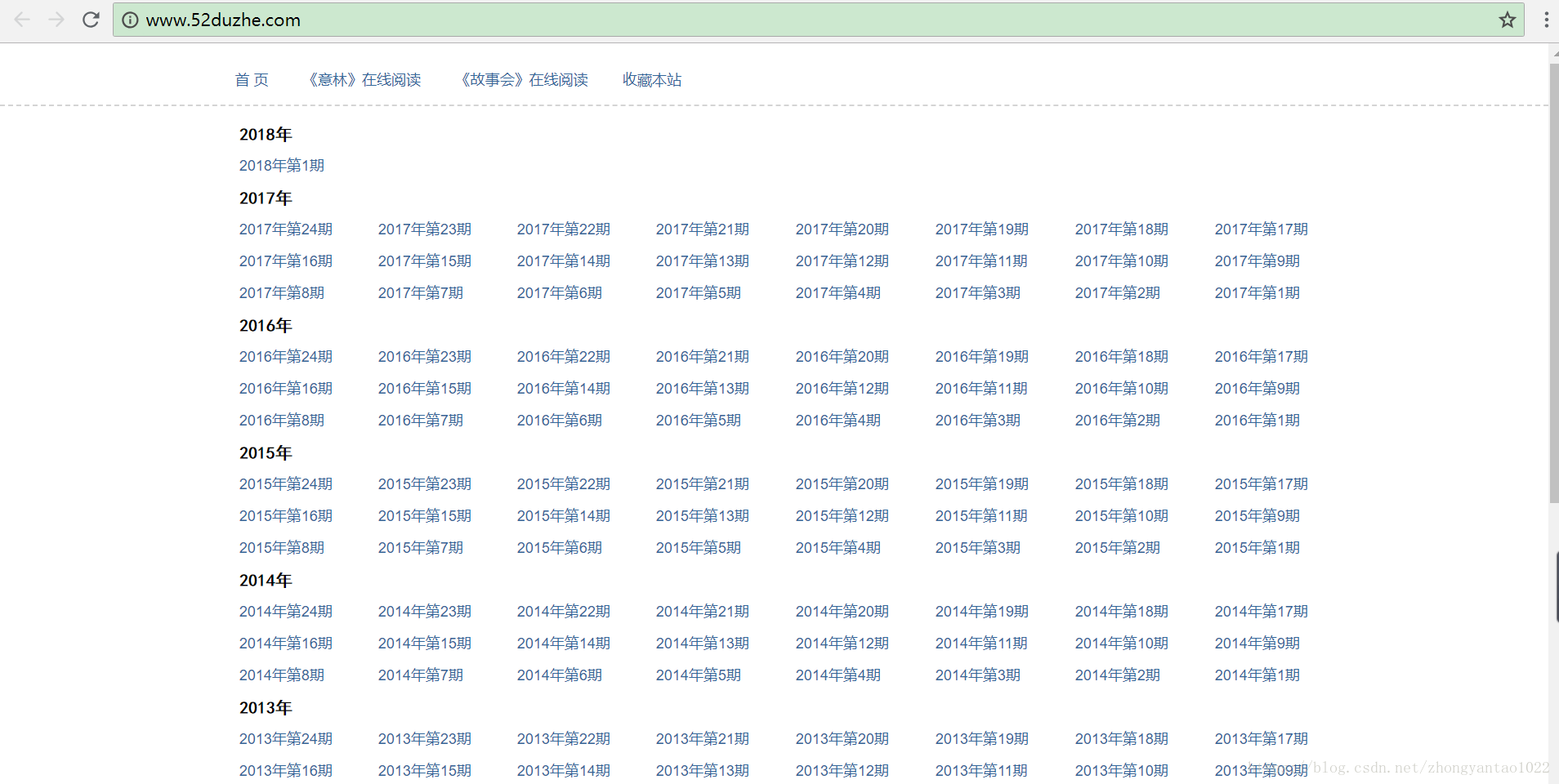
开始写代码:
public void test() {
try {
String url = "http://www.52duzhe.com/2017_01/index.html";
Document doc = Jsoup.connect(url).get();
//获得文章标题
Elements main = doc.getElementsByClass("main clearfix");
Elements link = main.select("a[href]");
for (Element hr : link) {
String href = hr.attr("abs:href");
Document inDoc = Jsoup.connect(href).get();
Elements inMain = inDoc.getElementsByClass("blkContainer");
Elements h1 = inMain.select("h1");
Elements artInfo = inMain.select(".artInfo");
Elements blkContainerSblkCon = inDoc.getElementsByClass("blkContainerSblkCon");
Elements p = blkContainerSblkCon.select("p");
String title = h1.text();
String author = artInfo.select("#pub_date").text();
String source = artInfo.select("#media_name").text();
String content = "";
for (Element contxt : p) {
content += p.text();
}
System.out.println("标题:" + title);
System.out.println(author);
System.out.println(source);
System.out.println("内容:"+content);
System.out.println("");
}
// String s = title.toString();
// String text = title.text();
System.out.println("test");
// String title2 = doc.select("具体选择器内容").get(0).text();
} catch (Exception e) {
e.printStackTrace();
}
}运行效果:

至此一个简单的Java爬虫demo完成啦!
最后附上源码:https://download.csdn.net/download/zhongyantao1022/10566017