http://www.seas.upenn.edu/~pcozzi/OpenGLInsights/OpenGLInsights-TileBasedArchitectures.pdf
tbr 和tbdr是gpu的一种架构 硬件层面的事情和deferred shading是两回事
有关blend的开销
immediate模式 要走相对较慢的 memory read-modify-write framebuffer
tile based模式 就在on chip tile buffer上用专门的硬件做了 基本没有开销 而如果在shader里面写会占shader吞吐量
所以这段的建议就是如果做透明的话 推荐用blend 而不在shader里做
而透明与不透明相比 透明(无论哪种方式alpha blend, alpha test, alpha to coverage)总会导致 对于透明物体后面的fragment来讲hidden surface removal 和earlyz 失效
==============
tbdr情况下似乎透明排序能解决 不知道粒度是不是pixel vertex
===================
tbr multisampling对带宽的影响情况是这样的
multisamp的瓶颈是带宽, 4x为例 访问framebuffer的带宽变为之前的4倍 (一个pixel 4个sample)
如果是tbt这部分 都在tile buffer上做 做完 一次送到framebuffer (resolved 之后 相当于一个pixel1个sample)
开销包含以下两部分
1.tile buffer上的大小需要4倍,厂商在开ms的情况下,减小tile size 为了省下buffer大小,这对性能有些许冲击,half size不会导致half performace
如果程序的瓶颈是shading吞吐量 tile buffer size减小 只会对性能有很很轻微的影响(比几乎无影响高一点 minor impact也就是除非程序瓶颈就是在这里了
2 第二种类型的开销在immediate mode下也是同样存在的 会增加大概10%的fragments(数量)的计算 具体数量取决于场景
不只是cover center的 frag参与 只要cover sample的 frags都会算在内
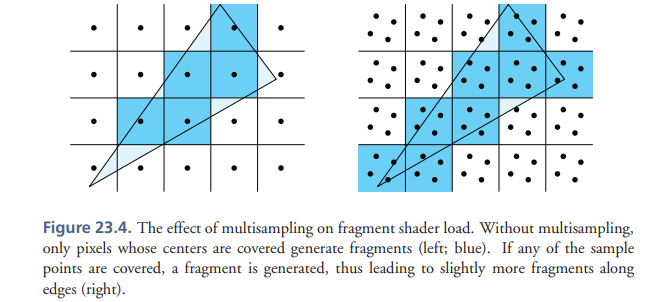
=======================
profiling 的话 gpu query在此类硬件上是不可用的(帧以内)
(非deferred的硬件 就该用gpu query拿精确时间 )
硬件的处理顺序是 所有vertex 第一个pass 之后按tile处理fragment这样拿到的commend buffer里面的 marker是乱的
此平台推荐方法 debug menu做开关检验impact ,用某些工具
==============
介于profile 不那么准确好用了
建议 开发初期 确定复杂度预算 trigngles ,textures ,shader complexity等等,这个我有做
来避免 geometry 超过一个最高的量引发的切分 性能会大幅下降