注:这篇博客内容大量参考机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾
作者: 寒小阳
前言
这已经是第二次认真学习这篇博文了,上一次是在接近两个月以前,很多知识都不懂,很头痛,而且没有整理笔记。
这次相当于复习。这遍看起来轻松多了。不得不说复习和练习对于掌握技能太重要了!
这位作者的此篇博文内容非常丰富详实,其中包含了一个完整数据挖掘项目实现的大体思路、工具和技巧。
我这篇文章是为了加深理解,外加将自己学习过程中补充的其他知识或者心得整理记录下来。
在此先谢过原博文作者!
本篇文章的机器学习算法应用到了逻辑回归分类算法(我的学习记录:逻辑回归学习笔记)。
一 明确课题:
在泰坦尼克号之灾事件中,建立乘客获救情况(是/否)与其诸背景特征之间的量化模型,并且依据此模型来预测有某些背景
的人在该海难中能否获救。
二 课题分析:
2.1 一个二分类问题。常用的分类算法有逻辑回归、随机森林、支持向量机(SVM)等等。
我们可以选择其中的一种算法进行模型建立,或是尝试使用多种算法建立模型并融合。
对于同一个问题,可以尝试多种思路进行解决,尤其是算法模型建立的过程,与问题的背景,
数据的类型,分析计算条件的限制都有关系。
2.2 模型的建立和优化是一个动态的过程,其中有许多尝试和反复,不必开始就要求过高,
先试图建立一个基本的模型,然后再一步步不断的优化。
2.3 优化过程包括:
A.分析现在模型的拟合状态(欠/过拟合?)
B.分析模型中使用的特征的贡献大小,进行特征选择,这也是特征工程的一部分。
C.预测失败案例产生的原因。
D.。。。
三 收集数据:
数据可以从网页中、传感器网络等等许多媒介中获取,这个项目中的数据直接来源于Kaggle竞赛平台,
是现成的数据。
四 认识数据
拿到数据后的第一步不是立即将其投入模型建立,而是先初步的认识了解数据,对该数据集建立一
个基本的概念。这个过程主要用到python中的numpy、pandas和matplotlib包。
4.1 导入数据
data_train = pd.read_csv('train.csv')对ipython notebook早有耳闻,第一次使用,与pycharm 相比,表格化的显示更清晰!

4.2 了解数据集基本信息
弄清楚每一项列名的实际含义和定义(refer to泰坦尼克号数据集):
passengerId:乘客ID
survived:是否被救获
Pclass:乘客等级(舱位等级分为1/2/3等)
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄
SibSp:siblings&spoused,该乘客在船上的堂兄弟妹/配偶人数
Ticket:船票信息
Fare:票价
Cabin:客舱
Embarked:登船港口
弄清楚数据集的数据条数和各列信息的完整性:

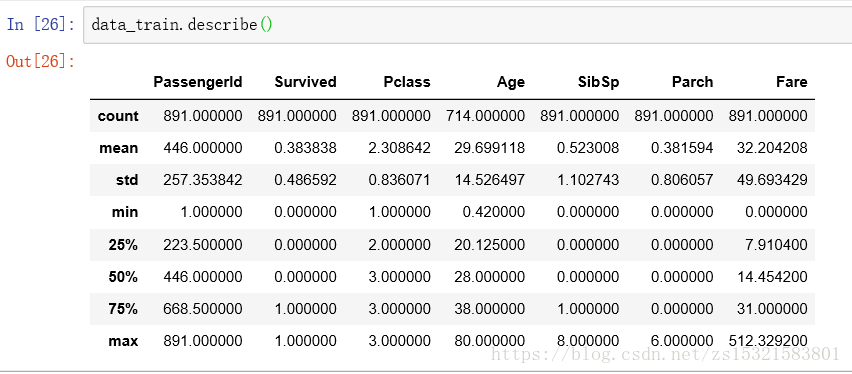
了解数据集各列的统计信息(针对数值型数据):
4.3 各项特征与结果的关联统计
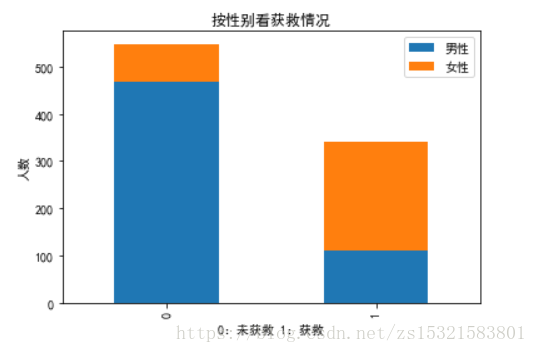
比如性别与是否获救的关系(一对一的关系图表展示):
# 看看各性别的获救情况
# 建立一张空白图表
plt.figure()
# 统计各性别乘客获救情况
survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
# 将各性别获救与未获救的情况做成一个数据框
df = pd.DataFrame({u'男性':survived_m,u'女性':survived_f})
# 用数据框中的数据画一个堆叠条形图
df.plot(kind='bar',stacked=True,title=u'按性别看获救情况')
plt.xlabel(u'0:未获救 1:获救')
plt.ylabel( u'人数')
plt.show()
再比如:
# 把数据框按照是否获救和有几个父母孩子分组,然后统计个数,结果是一个其余各列分组统计个数的数据框
g = data_train.groupby(['Survived', 'Parch'])
g.count()['PassengerId']
父母子女的个数对是否获救貌似没有显著的影响。
五 简单数据预处理*
从上一步的数据概览中初步了解到数据集中有缺失数据(如年龄和舱位),有字符串数据(如名字和票价),
有类型数据(如性别和登船港口),这种数据多种分类算法模型都无法使用,比如逻辑回归模型,只能使用
数值型数据(整型、浮点型、布尔型)。
5.1 缺失值的处理
遇到缺失值的情况,几种常见的处理方式如下:
- 如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
- 如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
- 如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
Age特征的缺失值比例为:(891-714)/891=0.2,不是特别多,而且Age是连续值特征属性,可以选择
后两种方法。一般来说,选择缺失值拟合补全是在存在数据可以给缺失值提供一些影响的条件下才使用。
有多种方法可以给缺失值提供拟合值,比如回归、KNN、随机森林等等。
此处采用随机森林算法拟合补全缺失值。
(sklearn和scipy的关系:前者依赖于后者)\
isnull()和notnull()用于数据框和Series,各项对应返回TRUE OR FALSE\
as_matrix 是将pd数据框或是系列转化成np的矩阵,用于投入模型,现在这种方法
已经过时了,直接使用df.values就可以得到没有标签的矩阵了!\
df.loc[x_exp, y_exp]:用行和列的表达式给数据框中的元素定位\
用ipython还有一个好处,对错误的提示特别详尽\
from sklearn.ensemble import RandomForestRegressor
### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1:])
# 用得到的预测结果填补原缺失数据
df.loc[df.Age.isnull(), 'Age' ] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[df.Cabin.notnull(), 'Cabin' ] = "Yes"
df.loc[df.Cabin.isnull(), 'Cabin' ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
5.2 类别型特征因子化
所谓类别型变量因子化,就是将分类变量变成数值变量。
以Cabin为例,原本一个属性维度,因为其取值可以使['yes','no],而将其平展开为Cabin-yes
Cabin_no两个属性:
- 原本Cabin取值为yes的,在此处的”Cabin_yes”下取值为1,在”Cabin_no”下取值为0
- 原本Cabin取值为no的,在此处的”Cabin_yes”下取值为0,在”Cabin_no”下取值为1
应用pandas的get_dummies()方法\
df 索引方法:df.iloc[]基于位置的索引;df.loc[]基于标签的索引\
pd.concat([])默认竖向(即0向)相连结\
df.drop()也是默认删除竖向的值(即0向),让0向的维度减少\
注意区分:
df = df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True) df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)赋值的作用是将等号右边的返回值赋给左边,上一条因为是在地变动(inplace=True),所以赋值符右侧的返回值为空(NoneType)
# 将'Cabin'因子化
dummies_Cabin = pd.get_dummies(data_train.Cabin, prefix='Cabin')
# 将'Embarked'因子化
dummies_Embarked = pd.get_dummies(data_train.Embarked, prefix='Embarked')
# 将‘Sex’因子化
dummies_Sex = pd.get_dummies(data_train.Sex, prefix='Sex')
# 将‘Pclass’因子化
dummies_Pclass = pd.get_dummies(data_train.Pclass, prefix='Pclass')
# 将生成的多维哑变量与原数据集连接,并且去掉原一维的分类变量
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass],axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
类别变量因子化完成!
5.3 特征值缩放
观察因子化后的数据框,发现Age和Fare两个属性与其他的属性相比,其变化幅度大很多,
这有什么影响呢?参考:梯度下降法
将范围明显过大的两个值进行缩放,可以应用的方法,见:关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
可以用np.ndarray给Series赋值\
values是pandas数据的属性,而不是方法,使用values,而不是values()
age_scale = preprocessing.scale(df.Age.values)
fare_scale = preprocessing.scale(df.Fare.values)
df.loc[:,'Age'] = age_scale
df.loc[:,'Fare'] = fare_scale
缩放成功!
到此为止,数据集的预处理,包括缺失值处理、类别特征处理、变化范围异常特征
标准化处理全部完成!
六 逻辑回归建模
就像拟合缺失值过程中使用随机森林模型一样,LogisticRegression模型也需要np.ndarray
格式的无标签数据,即pandas数据.values。
# 先使用df.columns找到列名的列表,然后取出所需要的列
train_df = df[['Survived', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin_No',
'Cabin_Yes', 'Embarked_C', 'Embarked_Q', 'Embarked_S', 'Sex_female',
'Sex_male', 'Pclass_1', 'Pclass_2', 'Pclass_3']]
# 将DataFrame转化成np.ndarray
train_np = train_df.values
# y即Survival的结果
y = train_np[:, 0]
# X即特征值
X = train_np[:, 1:]
# 导入线性模型中的逻辑回归模型
from sklearn.linear_model import LogisticRegression
# 定义逻辑回归分类器
clf = LogisticRegression()
# 拟合模型
clf.fit(X, y)
clf得到逻辑回归模型:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)接下来就是将测试集中的特征数据导入该模型进行预测了!首先,测试数据集需要和训练数据集
进行一样的预处理!
# 导入测试集放入数据框中
data_test = pd.read_csv('test.csv')查看基本数据信息:

与训练集不同的是,连续型数值变量包括Age和Fare,查看Fare统计量:
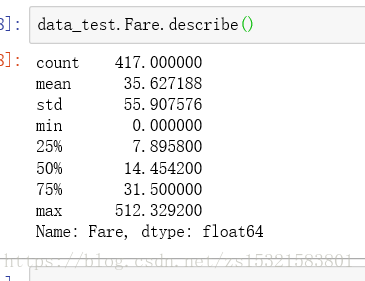
将Fare缺失的一项设置成中位数:
data_test.loc[data_test.Fare.isnull(), 'Fare'] = data_test.Fare.median()# 对测试集进行与训练集相同的预处理
# 现在就可以看出编写函数、建立模型的好处了:可以重复利用!
# 用训练集训练出来的随机森林回归模型拟合填充缺失的年龄值
data_test.loc[data_test.Age.isnull(), 'Age'] = rfr.predict(data_test.loc[data_test.Age.isnull(),['Fare', 'Parch', 'SibSp', 'Pclass']].values)
# 用set_Cabin_type()来分类Cabin值
data_test = set_Cabin_type(data_test)
# 将分类变量因子化,即将一维分类变量变成多维哑变量
dummies_Cabin = pd.get_dummies(data_test.Cabin, prefix='Cabin')
dummies_Embarked = pd.get_dummies(data_test.Embarked, prefix='Embarked')
dummies_Sex = pd.get_dummies(data_test.Sex, prefix='Sex')
dummies_Pclass = pd.get_dummies(data_test.Pclass, prefix='Pclass')
# 横向联结并且横向去除分类变量
df = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass],axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
# 缩放范围明显过大的特征值
df.Age = preprocessing.scale(df.Age)
df.Fare = preprocessing.scale(df.Fare)在应用之前拟合出来的模型时,要特别注意测试特征的排序要与训练特征的排序相同!
# 取出需要投入逻辑回归模型的预测特征并转为np.ndarray
test_df = df[['Age', 'SibSp', 'Parch', 'Fare', 'Cabin_No', 'Cabin_Yes',
'Embarked_C', 'Embarked_Q', 'Embarked_S', 'Sex_female', 'Sex_male',
'Pclass_1', 'Pclass_2', 'Pclass_3']]
test_np = test_df.values
# 预测
predicted_np = clf.predict(test_np)
# 将预测结果放入数据框,与passengerId对应起来,ID是唯一的,与训练集也不能重复
# 注意:数据框中字典的内容应该是列表或是矩阵
# 获救情况是整型,将预测结果astype(np.int32)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].values,'Survived':predicted_np.astype(np.int32)})# 将结果导出到csv文件,不带索引
result.to_csv('predictions.csv', index=False)
在Kaggle上提交了结果,比上次的准确率提高了一个百分点,排在6K名,总参赛人数不到12K,也即是说我的结果还没到50%,
没关系,这只是一个baseline!
七 逻辑回归系统优化
7.1 模型系数关联分析
我们使用的逻辑回归分类模型是线性分类模型,模型中隐含着一个成本函数,其形式是多
远线性方程。模型确定的过程就是要使这个成本函数获得最小值的各个特征(也就是成本
函数的自变量)的系数的确定过程。这个方程的系数有什么实际意义呢?如果系数为
正,该特征与结果呈正相关,反之,呈负相关,越接近0,相关性越低。如果可以列出特征和
其对应的系数,那么我们就可以直观的了解各特征对结果的影响,这也是应用线性模型的好处
之一。
# 线性模型的系数是模型的属性,是一个1*n的矩阵
# list()可以将多维数据变成一维,才可以做字典的内容
coefficients = pd.DataFrame({'columns':list(train_df.columns[1:]),'coef_':list(clf.coef_.T)})

7.2 交叉验证
在实际训练中,模型通常对训练数据表现好,对非训练数据拟合程度较差,通过将训练集本身
随机分成K份,相当于有了多对训练集和测试集,同一个模型可以产生多个准确率,比较多个可能
的模型进行交叉验证的结果的准确率方差后,可以比较各个模型的泛化能力。
K折交叉验证:
from sklearn import model_selection
from sklearn import linear_model
# 将训练集分成5份,4份用来训练模型,1份用来预测,这样就可以用不同的训练集在一个模型中训练# 定义逻辑回归分类器clf = linear_model.LogisticRegression()# 定义特征集和结果集
X = train_df.values[:,1:]
y = train_df.values[:,0]
print(model_selection.cross_val_score(clf, X, y, cv=5))[0.81564246 0.81005587 0.79213483 0.78651685 0.81355932]
7.3 学习曲线
有一个很可能发生的问题是,通过不断的进行特征工程,产生的特征越来越多,用这些
特征去训练模型,会对我们的训练集拟合的越来越好,同时也可能在丧失泛化能力,从
而在待预测的数据上,表现不佳,也就是发生过拟合现象。
从另一个角度上说,如果模型在待预测的数据上表现不佳,除掉上面说的过拟合问题,
也有可能是欠拟合,也就是说,即使在训练集上也表现得不那么好。
在机器学习问题上,对于过拟合和欠拟合两种情形,我们优化的方式是不同的。
对于过拟合而言,通常以下策略对结果优化是有用的:
A 做一下特征选择,挑出较好的特征的子集来做训练
B 提供更多的数据,从而弥补原始数据的偏差问题,学习到的模型也会更准确。
而对于欠拟合,我们通常需要更多的特征,更复杂的模型来提高准确度。
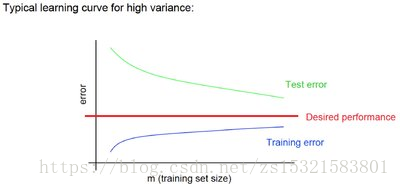
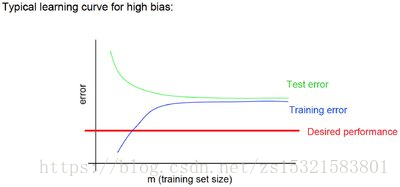
著名的学习曲线(learning curve)可以帮助我们判定我们的模型现在所处的状态。我们以
样本数据为横坐标,训练和交叉验证集上的错误率为纵坐标,两种状态分别如下:
过拟合(overfitting/high variance):
欠拟合(underfitting/high bias):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.show()
plt.gca().invert_yaxis()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
plot_learning_curve(clf, u"学习曲线", X, y)
八 模型融合(model ensemble)
模型融合的含义:当我们手头上有一堆在同一份数据集上训练得到的分类器(比如logistic regression,SVM,KNN,random forest,神经网络),那我们让他们都分别去做判定,然后对结果做投票统计,取票数最多的结果为最后结果。
模型融合可以比较好地缓解,训练过程中产生的过拟合问题,从而对于结果的准确度提升有一定的帮助。
首先,需要训练出多个同时具有可用性的模型。
思路是可以应用多个算法模型,或者是对同一个算法模型用不同的数据集进行训练(bagging)。
BaggingRegressor含义:
A Bagging regressor is an ensemble meta-estimator that fits base regressors each on random subsets of the original dataset and then aggregate their individual predictions (either by voting or by averaging) to form a final prediction. Such a meta-estimator can typically be used as a way to reduce the variance of a black-box estimator (e.g., a decision tree), by introducing randomization into its construction procedure and then making an ensemble out of it.
from sklearn.ensemble import BaggingRegressor
# fit到BaggingRegressor之中
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y)
predictions = bagging_clf.predict(test_np)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].values, 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_bagging_predictions.csv", index=False)将模型融合后的结果再次上传到kaggle中:

准确率没有什么进步!侧面反映了原来的基线模型并没有过拟合。
总结
本文中用机器学习解决问题的过程大概如下图所示:
