字典树
1.引题
给出一个由S(最多4000个)个不同单词组成的字典和一个长字符串。把这个字符串按字典分解成若干个单词的连接,有多少种方法?(方法数可能很多,结果对20071027取模)
比如有4个单词:a、b、cd、ab,则abcd有两种分解方法:a+b+cd和ab+cd。(字典中单词个数不超过4000)
【输入】
abcd
4
a
b
cd
ab
【输出】
Case 1: 2
你会怎么做呢?去一一比较吗?这也太傻了诶。
所以就有种叫做字典树的东西啦!
字典树(trie),又称前缀树。是查找树的一种。主要用于大量字符串的存储,查找。搜索引擎通常利用字典树完成用户的搜索提示。
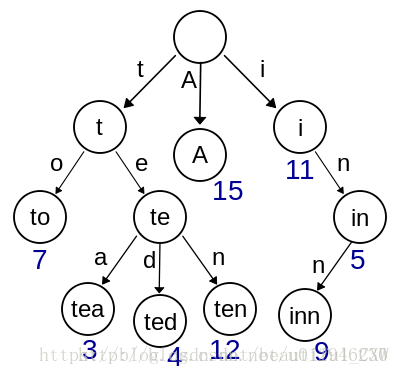
比如像这样的图,tea,ted,ten,to,inn就被我分解成了一个这样的树,也就是说,字典树在本质上是一棵26叉树。当你要找一个单词是,就是从第一个字母开始往下找,直到找到叶子,就找到了这个单词。
那么具体怎么实现呢?
先以引题为例子,
1.用d[i]表示以第i个字符到字符串末尾的字符串能够分解得单词数,
2.假设在s[i…length(s)]中,仅发现s[i…n]是字典中出现的单词,n是该单词的长度,此时d[i]=d[i+n],(这里该怎么理解呢?这样说,因为该单词是仅发现的,说明从i到n里有也只有这么一个单词不能再拆分了,所以d[i]=1*d[i+n])
3.所以,d[i]=sum(d[i+len(x)]),假定x是一个出现的前缀字符串(2中的s[i…n])
4.但是,如果枚举x,再判断它是否为s[i…len]的前缀,复杂度是O(4000*len);
那么,字典树!
以该图为例
我们很容易发现字典树有以下几个特点:
1.根节点为空,
2.内节点一般为字符
3.叶子结点就是往下搜到的单词结点
然后呢,用两个数组来保存这棵树
1.ch[i][j]=x,表示第i号结点的子结点序号是x,保存的字符的ASCII码是j;
2.val[i],表示第i号结点的附加信息,比如val[i]>0表示i是单词结点。(这个val数组是要你自己在造树的时候遇到叶子结点再把它手动赋值为大于0)
接下来展示字典树的插入和查询
const int maxnode = 400*100+10;
const int sigma=26;
struct Tire {
int ch[maxnode][sigma];
int val[maxnode];
int sz; //结点总数
void clear() {
sz=1; memset(ch[0], 0, sizeof(ch[0]));
}
int idx(char c) {return c-'a'};
void insert(char *s, int v);
void find(char *s);
}
void insert(char *s, int v) //v是附加信息,0表示“非单词结点”
{
int u=0, n = strlen(s);
for (int i=0; i<n; i++) {
int c = idx(s[i]);//得出它对于a的相对值
if (!ch[u][c]) //如果是0,那么申请新节点
{
memeset(ch[sz], 0, sizeof(ch[sz]));
val[sz]=0;//说明他不是叶子结点(这里我还不清楚,麻烦各位dalao评论指正啦!!)
ch[u][c]=sz++;//申请新的结点
}
u = ch[u][c];//接下来的字符则是以u为根节点往下延伸了,就是比如说beautiful,当e作为b的子节点之后,就要去做a是e的子节点了
}
val[u]=v;
}
void find(const char *s, int len, vector<int>& ans)
{
int u=0;
for (int i=0; i<len; i++) {
if (s[i] == '\0') break;//空节点不做
int c=idx(s[i]);
if (!ch[u][c]) break;//这一层这个序号的这个字符的子节点没有在字典里,我就不做啦哈哈哈哈哈
u = ch[u][c];//往子节点延伸
if (val[u]>0) ans.push_back(val[u]); //到叶子结点了,那么就是个单词
}
}
}
char str[30001], tmp[101];
int d[30001];
Trie t;
int main()
{
while(scanf("%s",str) != EOF){
scanf("%d",&n);
t.init();
for(int i = 0 ; i < n ; i ++){
scanf("%s",tmp);
int len = strlen(tmp);
//将单词的长度保存的trie树节点中
t.insert(tmp,len);
}
printf("Case %d: ",Case++);
solve();
}
return 0;
}
void solve()
{
memset(d,0,sizeof(d));
int len = strlen(str);
d[len] = 1;
for(int i = len - 1; i >= 0 ; i--){
t.find(str+i,len-i);
for(int j = 0 ; j < ans.size(); j++){
d[i] = (d[i]+d[i+ans[j]])%MOD;//一开始的那道题的解法,我明天来讲!!!!
}
}
printf("%d\n",d[0]);
}啊