这次主要讲一下怎么分析ajax请求来获得我们想要的数据,在通过多进程进行抓取,当然这次的目的主要是这两个,所以最后的结果是以打印在控制台为主。
那么让我们开始这一次的爬虫之旅
我们先进入堆糖网,这次我们要爬取的是我的女神,新垣结衣的图片。
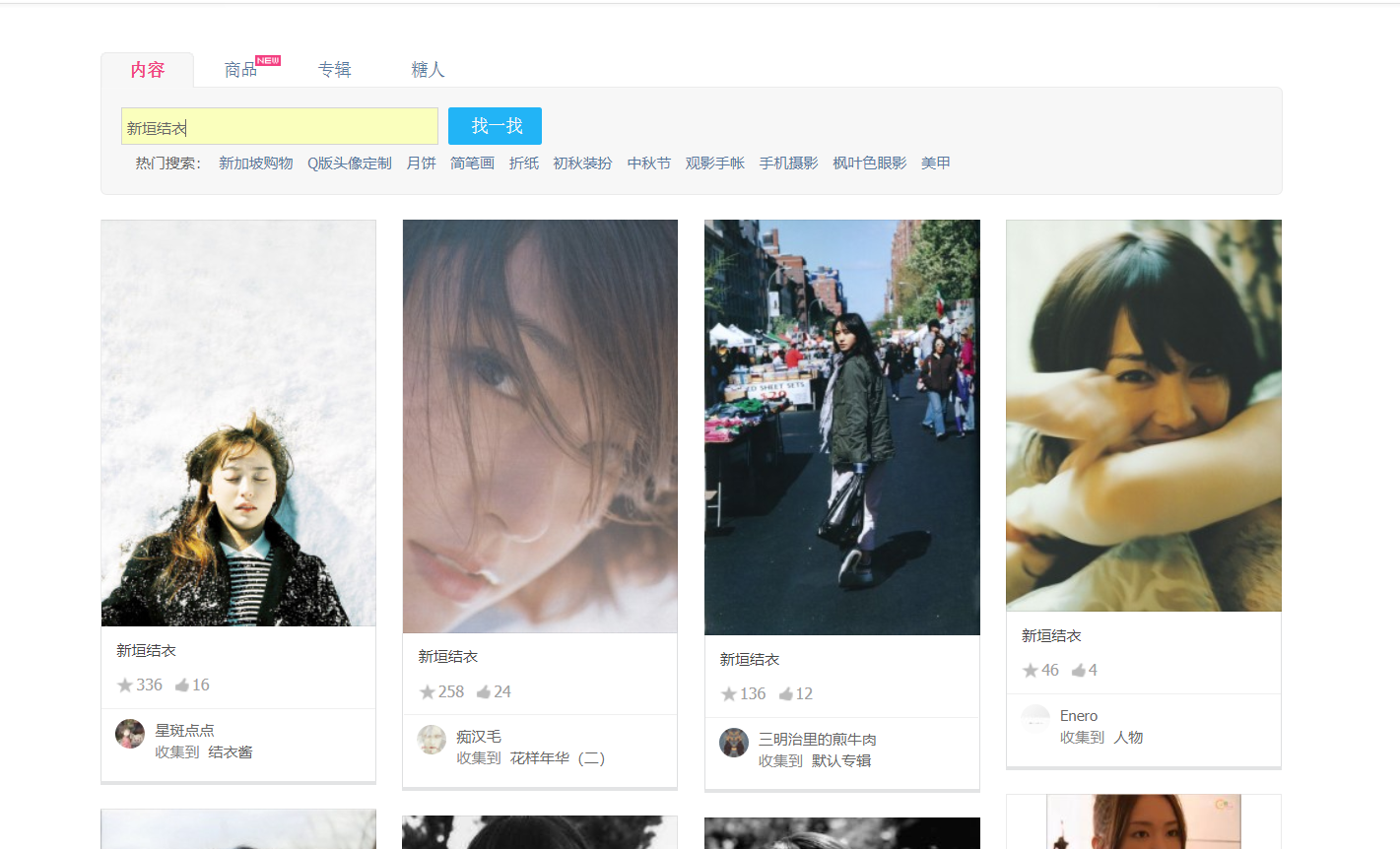
我们看到大致的页面长这样。需要注意的是我们在往下拉的过程会不断的加载出新的图片,也就是说我们没办法直接通过普通的request和bs4来得到我们想要的一整个页面的图片,更不用说翻页抓取了。
这是因为加载出来的图片时通过js渲染过的,属于动态网页,所以我们有两种方法,第一种可以用selenium,第二种就是我们今天要用的ajax。如果有对ajax不了解的,建议先看一下我的下一篇讲解ajax的博客再来看这一篇博客。
回到正题,老套路先按f12,点击network,勾选xhr,我们会看到以下的东西
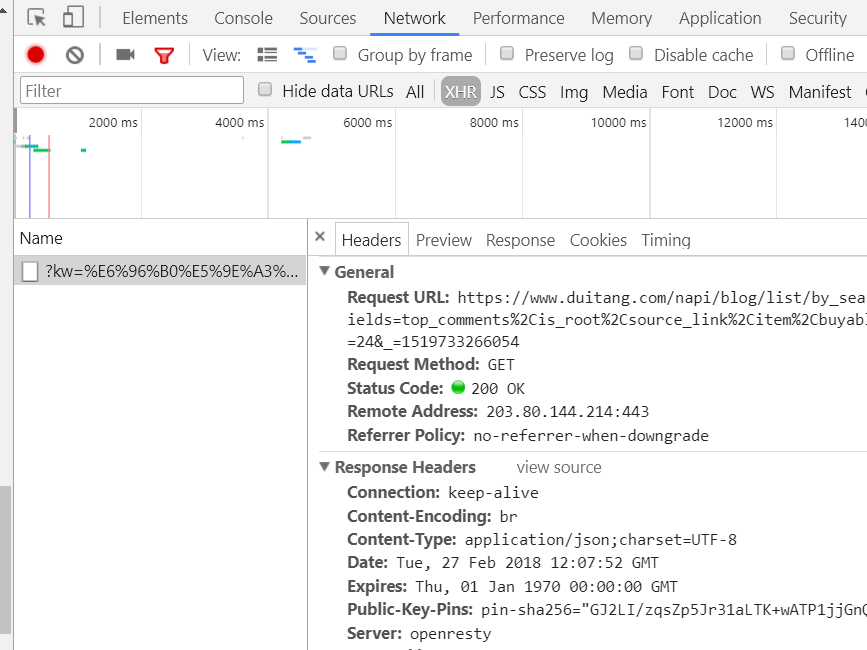
这是我们要的xhr文件,出现这个文件的原因是我们不断的往下来然后加载出来的第一部分的图片,如果继续往下拉,还会不断的出现新的xhr文件。
下一步我们点击Preview,会看到以下东西
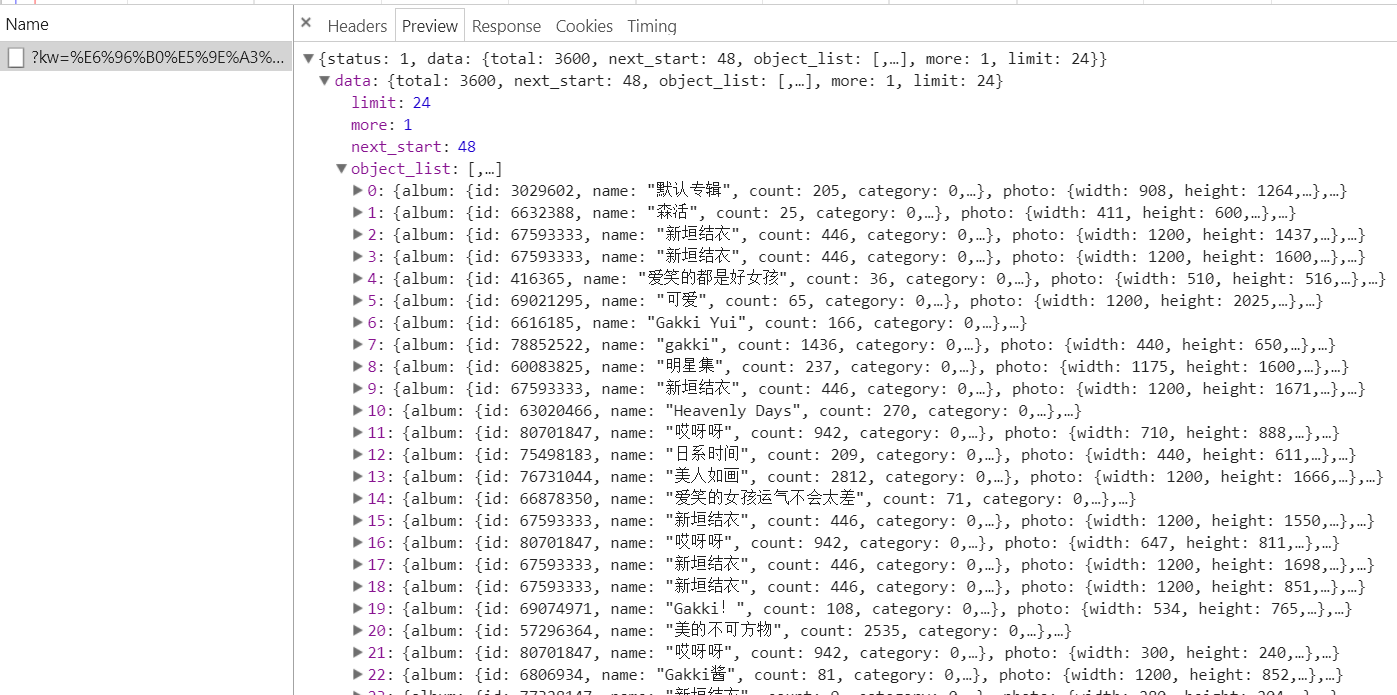
这些就是我们下拉时新加载出来的24张图片,这些图片都以json格式保存,我们要的图片在data里面的object_list里面,我们点开其中一个看一下,

看到photo里面path了吗,这个链接就是我们要找的图片链接。
我们知道我们是要通过发送ajax请求来获得数据的,那么这个请求要包含一些什么呢,我们看一下headers

我们看到URL需要的参数有kw,type,include_fields,start五个参数,那么每一个ajax请求之间的规律又是什么呢,当我们多加载几次的时候,我们发现参数里面的start总是发生了变化,并且是以24的幅度在变,这个是24,下一个请求里面的start就是48,以此类推。
那么找到规律后,我们就开始伪造ajax请求,代码长这样
def get_page(offset): #offset为变动的参数,也就是start
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36',
'Referer': 'https://www.duitang.com/search/?kw=%E6%96%B0%E5%9E%A3%E7%BB%93%E8%A1%A3&type=feed',
'X-Requsted-With': 'XMLHttpRequest'
}
params = { #请求链接所需要的参数
'kw': '新垣结衣',
'type': 'feed',
'include_fields': 'top-comments',
'start': offset,
#'_': number
}
url = 'https://www.duitang.com/napi/blog/list/by_search/?' + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json() #因为返回的是json数据,所以这里我们return response.json()
except requests.ConnectionError:
return None得到我们要的json数据后,我们要来解析数据了,因为我们只要path,其他的不要。
所以有以下代码
def get_image(json):
items = json.get('data')
for item in items.get('object_list'):
path = item.get('photo').get('path')
print(path)
print('Successes!')每打印完一部分后用print('Successes!')来作为分割,到这里基本就差不多了,最后我们看一下怎么利用多进程进行操作。
START = 0
END = 10
if __name__ == '__main__':
offsets = ([x * 24 for x in range(START,END + 1)])
pool = Pool() #Pool是进程池,如果不给参数,则默认的进程数就是你的CPU核数
pool.map(main,offsets) #第一个参数为调用的方法名,第二个参数为改变的值
pool.close() #不允许添加新的进程
pool.join() #在子进程运行结束后父进程再结束
end = time.clock() #检测整个程序的运行时间
print('time:{}'.format(end-start)) #打印运行时间最后贴上完整代码
# -*- coding:utf-8 -*-
from multiprocessing import Pool
import requests
import json
import time
from urllib.parse import urlencode
start = time.clock() #用来检测代码运行时间的
def get_page(offset): #offset为变动的参数,也就是start
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36',
'Referer': 'https://www.duitang.com/search/?kw=%E6%96%B0%E5%9E%A3%E7%BB%93%E8%A1%A3&type=feed',
'X-Requsted-With': 'XMLHttpRequest'
}
params = { #请求链接所需要的参数
'kw': '新垣结衣',
'type': 'feed',
'include_fields': 'top-comments',
'start': offset,
#'_': number
}
url = 'https://www.duitang.com/napi/blog/list/by_search/?' + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
def get_image(json):
items = json.get('data')
for item in items.get('object_list'):
path = item.get('photo').get('path')
print(path)
print('Successes!')
def main(offset):
json = get_page(offset)
get_image(json)
START = 0
END = 10
if __name__ == '__main__':
offsets = ([x * 24 for x in range(START,END + 1)])
pool = Pool() #Pool是进程池,如果不给参数,则默认的进程数就是你的CPU核数
pool.map(main,offsets) #第一个参数为调用的方法名,第二个参数为改变的值
pool.close() #不允许添加新的进程
pool.join() #在子进程运行结束后父进程再结束
end = time.clock() #检测整个程序的运行时间
print('time:{}'.format(end-start)) #打印运行时间