先贴出我借鉴的博客
- http://blog.pluskid.org/?p=287
- http://liuzhiqiangruc.iteye.com/blog/2117144
- http://www.cnblogs.com/wing1995/p/5014050.html
Spectral Clustering(SC, 谱聚类)是一种基于图论的聚类方法。将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似,而子图间距离尽量距离较远,以达到常见的聚类的目的。
谱聚类本身也提供了好几种不同的分割(cut)方法(mininum cut, ratio cut, nomarlized cut),每种方法对应一种优化目标。本文只介绍其中比较常见,也是比较实用,而且实现起来也比较经济的一种:Nomarlized cut.
每条边的边权值为两个点的相似度。
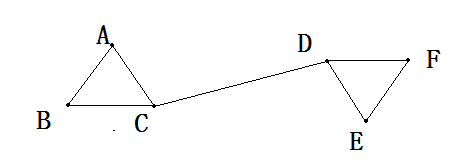
第一步我们先构建一个相似度矩阵
这里我们为了方便理解其概念,将相连的点的边权值设为1,其余是0。
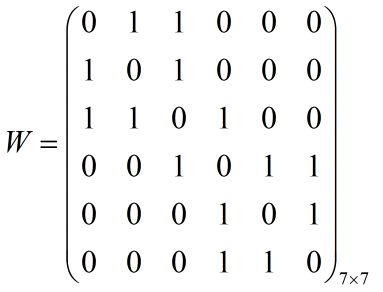
第二步我们构建一个度矩阵
度矩阵(某个点的度指的是与该点关联的点之间的总权数,比如A点的度为2),度矩阵是一个对角矩阵,也就是除了对角线有值以外,其他位置都是0。

第三步构建拉普拉斯矩阵L
计算方法是L = D-W
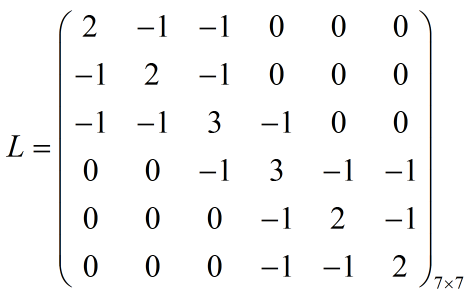
第四步归一化矩阵L

关于第四步中,对拉普拉斯矩阵归一化时,归一化公式进行变换得到:

令:

则在第五步中,我们可以将求L的K个最小特征值及其对应的特征向量的问题,转化为求矩阵E的K个最大的特征值及其对应的特征向量。
第五步计算矩阵L的特征值和特征向量
如果说前面的拉普拉斯矩阵的构造是为了将数据之间的关系反映到矩阵中,那么计算特征值以及特征向量从而达到将维度从N维降到k维,然后维度降下来了,我们就可以使用k-means聚类,聚类完成后再将数据投影到原始数据上,这样原始数据就成功聚类了
既然我们要将N维的矩阵压缩到k维矩阵,那么就少不了特征值,取前k个特征值进而计算出k个N维向量P(1),P(2),...,P(k).这k个向量组成的矩阵N行k列的矩阵(经过标准化)后每一行的元素作为k维欧式空间的一个数据,将这N个数据使用k-means或者其他传统的聚类方法聚类,最后将这个聚类结果映射到原始数据中( 对矩阵N*k按每行为一个数据点,进行k-means聚类,第i行所属的簇就是原来第i个样本所属的簇),原始数据从而达到了聚类的效果。
关于如何计算特征值和特征向量:
特征值为=2,1
把每一个带入线性方程组
求基础解系
当=2时
解得:
当=1时
解得