SQL语句如何优化?
一般会说添加索引,其实应该从下面几个方面考虑
(1)表的数据类型是否设计的合理,有没有遵循数据类型越简单越好
(2)表中的碎片是否整理
(3)表的统计信息是否收集,只有信息统计准确才能帮助优化SQL
(4)查看执行计划,检查索引的使用情况,没有用到创建索引
(5)挑选合适的字段作为索引
那么怎么挑选字段做索引三个原则
- 经常被查询的字段(一般放在where后面)
- 用于表连接的列
- 经常排序分组的列(group by和order by后面的)
我们也可以计算某一个字段(如name)的索引选择性,这个值越大说明重复值越少,那么就适合建立索引
select count (distinct name)/count(*) from userMSQL数据库中B+TREE索引分为:聚集索引(叶子节点存放数据)和非聚集索引(普通索引,叶子存放地址),不同的存储引擎方式不一样
联合索引
创建两个或更多个列上的索引被称作复合索引,联合索引是一个有序元组<a1, a2, …, an>,其中各个元素均为数据表的一列
Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找,这就是利用的最左前缀索引

创建索引
普通索引创建语法:
alter table table_name add index index_name或者
create index index_name on table_name联合索引创建
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )索引使用策略及查询优化
查看表的索引的sql语句
show index from from table_name;使用explain命令生成执行计划,对于结果的查看,有查看心法:
(1)先看type,若为all,全表扫描,不用看其他列的内容。
(2)在看key列,为null,没有使用索引。
(3)看row列,被扫描的行数,越大,sql效率越低。
那么什么样的查询会用到索引呢?

这里我们使用mysql官方数据库employees database作为示例,说明mysql的索引的使用

遇到的问题
ERROR 1193 (HY000) at line 38: Unknown system variable 'storage_engine'解决:
首先查看表的索引
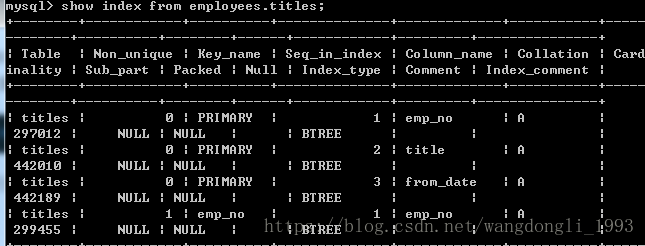
从结果中可以到titles表的主索引为<emp_no, title, from_date>,还有一个辅助索引<emp_no>
<emp_no, title, from_date>就是一个联合索引,因为在列Seq_in_index有1,2,3(类似数组)说明是一个联合索引
根据查询sql语句进行分类分析
(1)精确匹配
用explain查看命令生成执行计划 为了实验,我们先删除辅助索引
alter table employees.titles drop index emp_no;在进行实验,发现有联合索引全部被应用这里有一点需要注意,理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引,效果是一样的

(2)最左前缀匹配

当查询条件精确匹配索引的左边连续一个或几个列时,如<emp_no>或<emp_no, title>,索引可以被用到,但是只能用到一部分,即条件所组成的最左前缀
(3)查询条件用到了索引中列的精确匹配,但是中间某个条件未提供。

此时索引使用情况和情况二相同,因为title未提供,所以查询只用到了索引的第一列,而后面的from_date虽然也在索引中,但是由于title不存在而无法和左前缀连接,因此需要对结果进行扫描过滤from_date(这里由于emp_no唯一,所以不存在扫描)。如果想让from_date也使用索引而不是where过滤,可以增加一个辅助索引<emp_no, from_date>,此时上面的查询会使用这个索引。除此之外,还可以使用一种称之为“隔离列”的优化方法,将emp_no与from_date之间的“坑”填上。
首先我们看下title一共有几种不同的值:

在值比较少的情况下,我们可以用in来达到精确匹配
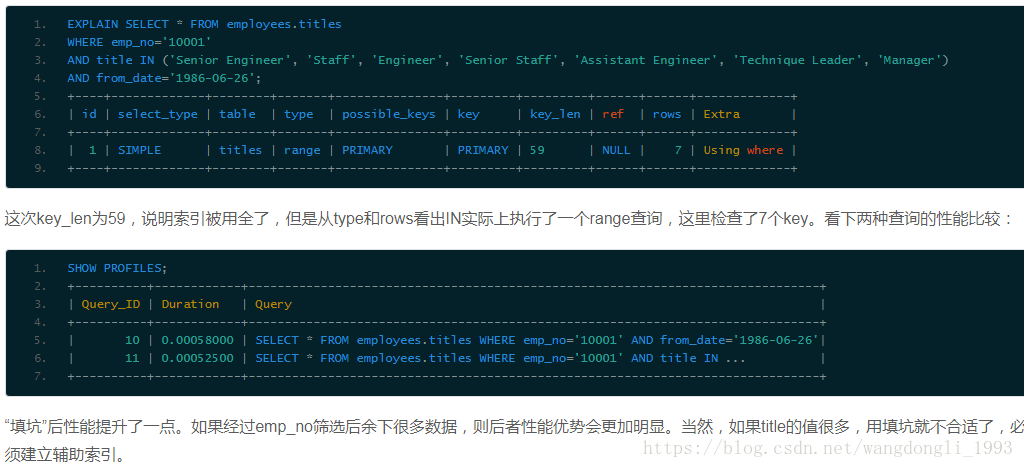
(4)没有使用联合索引的第一列
最左匹配原则,使用不到索引

(5)范围查询
若使用范围查询的列是联合索引的第一列则根据最左匹配原则使用一个索引,后面的列无法使用索引

(6) 查询条件中有函数或者表达式
不会再查询条件为函数或者表达式的列上使用索引
(7)特殊情况
下面这种不会使用索引
