1.concat
import tensorflow as tf
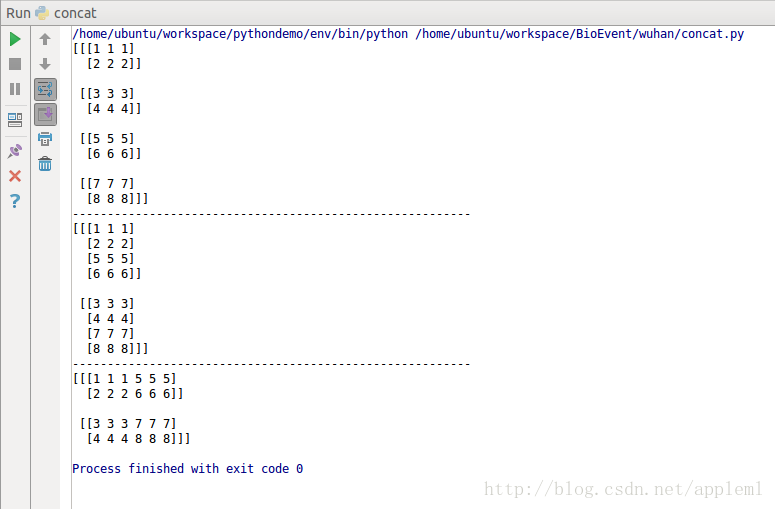
t1 = [[[1, 1, 1],[2, 2, 2]],[[3, 3, 3],[4, 4, 4]]]
t2 = [[[5, 5, 5],[6, 6, 6]],[[7, 7, 7],[8, 8, 8]]]
with tf.Session() as sess:
A = tf.concat(0, [t1, t2])
B = tf.concat(1, [t1, t2])
C = tf.concat(2, [t1, t2])
print(sess.run(A))
print('---------------------------------------------------------')
print(sess.run(B))
print('---------------------------------------------------------')
print(sess.run(C))
2.tensorflow.nn.bidirectional_dynamic_rnn()
cell_fw, # 前向RNN
cell_bw, # 后向RNN
inputs, # 输入
sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度)
initial_state_fw=None, # 前向的初始化状态(可选)
initial_state_bw=None, # 后向的初始化状态(可选)
dtype=None, # 初始化和输出的数据类型(可选)
parallel_iterations=None, swap_memory=False, time_major=False, # 决定了输入输出tensor的格式:如果为true, 向量的形状必须为 `[max_time, batch_size, depth]`. # 如果为false, tensor的形状必须为`[batch_size, max_time, depth]`. scope=None )
返回值: 一个(outputs, output_states)的元组 其中,
outputs为(output_fw, output_bw),是一个包含前向cell输出tensor和后向cell输出tensor组成的元组。假设 time_major=false,tensor的shape为[batch_size, max_time, depth]。实验中使用tf.concat(outputs, 2)将其拼接。
output_states为(output_state_fw, output_state_bw),包含了前向和后向最后的隐藏状态的组成的元组。 output_state_fw和output_state_bw的类型为LSTMStateTuple。 LSTMStateTuple由(c,h)组成,分别代表memory cell和hidden state。
3.tf.nn.embedding_lookup
函数的用法主要是选取一个张量里面索引对应的元素。tf.nn.embedding_lookup(tensor, id):tensor就是输入张量,id就是张量对应的索引。
4.tf.reshape(tensor,shape,name=None)
函数的作用是将tensor变换为参数shape形式,其中的shape为一个列表形式,特殊的是列表可以实现逆序的遍历,即list(-1).-1所代表的含义是我们不用亲自去指定这一维的大小,函数会自动进行计算,但是列表中只能存在一个-1。(如果存在多个-1,就是一个存在多解的方程)
5.tf.matmul(a,b,name)
a,b维度相同
输入a ,b必须是矩阵或者维度大于2的tensor
这个函数是专门矩阵或者tensor乘法,而不是矩阵元素对应元素相乘。
6.squeeze
从数组的形状中删除单维度条目,即把shape中为1的维度去掉。
7.tf.convert_to_tensor()
将python的数据类型转换成TensorFlow可用的tensor数据类型