kaggle上的一个经典的比赛,试试手,权当了解比赛的过程和了解sklearn的建模过程
导库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')读取数据
train_data = pd.read_csv(r'C:\Users\Administrator\Desktop\titanic_train.csv')先看下数据EDA看看什么情况
train_data.head()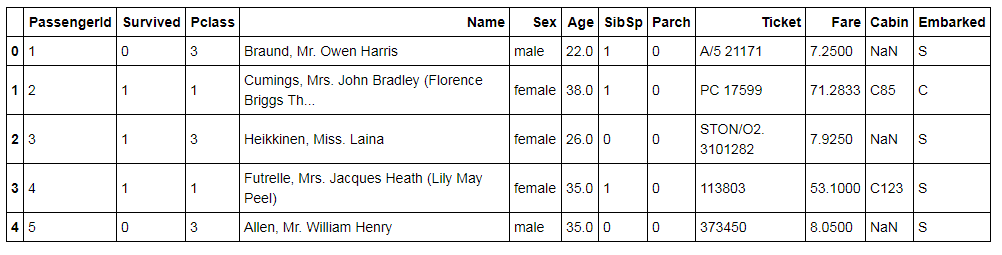
Survived=1、生,0为死;SibSp:兄弟姐妹的数量;Parch:父母子女的数量;Cabin:客舱信息;Embarked:登船地点;Pclass:座位等级
看下数据信息
train_data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB
Age、Cabin、Embarked有缺失值
观察下train_data里获救比例
fig = plt.figure()
train_data.Survived.value_counts().plot(kind = 'bar')
plt.ylabel('人数')
plt.title('获救情况')
plt.show()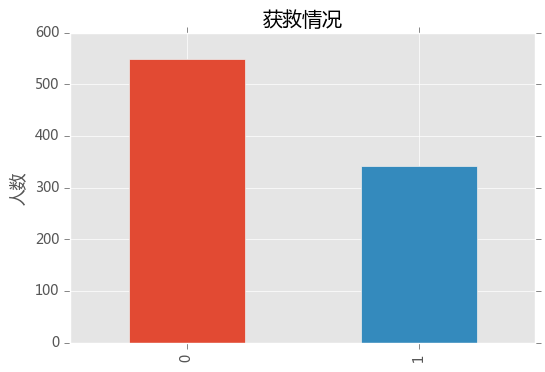
生少亡多
不同等级座位的人数
train_data.Pclass.value_counts().plot(kind = 'bar')
plt.ylabel('人数')
plt.title('座位等级')
plt.show()
3等舱的人最多,穷人还是占多数
各等级船舱的年龄分布
train_data.Age[train_data.Pclass == 1].plot(kind = 'kde')
train_data.Age[train_data.Pclass == 2].plot(kind = 'kde')
train_data.Age[train_data.Pclass == 3].plot(kind = 'kde')
plt.xlabel('年龄')
plt.ylabel('人群密度')
plt.title('各等级船舱年龄分布')
plt.legend(('1等舱','2等舱','3等舱'),loc = 'best')
plt.show()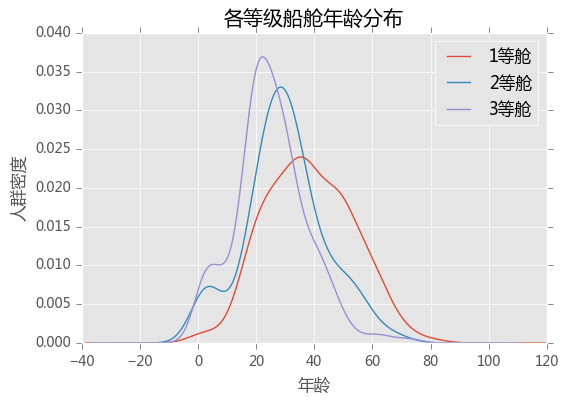
穷的大部分是年轻人,20岁出头挤在3等舱,40多岁的中年人有了一定的财富积累,在1等舱谈笑风声
登船的情况
train_data.Embarked.value_counts().plot(kind = 'bar')
plt.ylabel('人数')
plt.title('登船情况')
plt.show()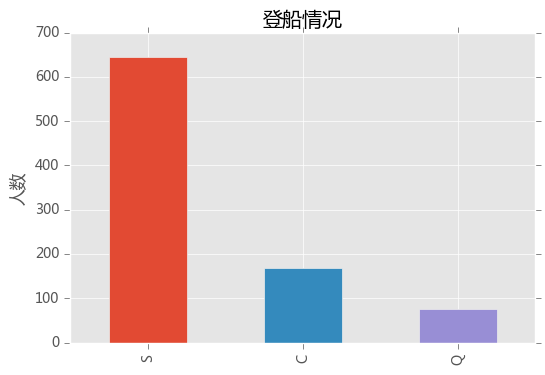
S是southampton(南安普顿,英国南部港口城市),C是Cherbourg(法国 瑟堡),Q是Queenstown(爱尔兰 昆士敦),S点等舱的人最多
分析下各feature和survived的关系
年龄
plt.scatter(train_data.Survived,train_data.Age)
plt.ylabel('年龄')
plt.title('按年龄与获救关系')
plt.show()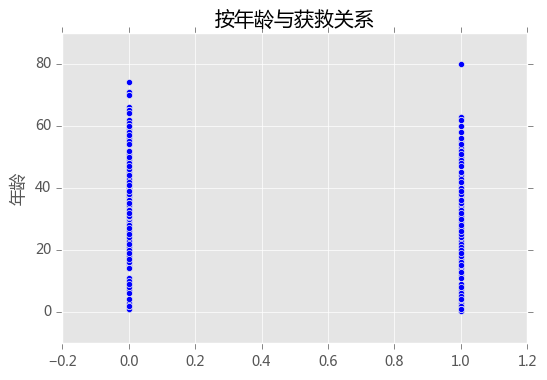
貌似65岁以上的老人都没有获救,但是有个80岁的大爷活下了。。。大爷牛逼
座位等级
survived_0 = train_data.Pclass[train_data.Survived == 0].value_counts()
survived_1 = train_data.Pclass[train_data.Survived == 1].value_counts()
df = pd.DataFrame({'获救': survived_1,'未获救': survived_0})
df.plot(kind = 'bar',stacked = True)
plt.xlabel('座位等级')
plt.ylabel('人数')
plt.title('座位等级与获救关系')
plt.show()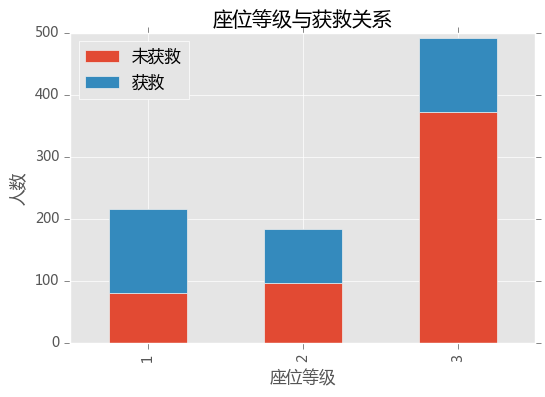
获救情况和座位等级有明显的关系,1等舱获救比例远远高于3等舱
性别
survived_m = train_data.Survived[train_data.Sex == 'male'].value_counts()
survived_f = train_data.Survived[train_data.Sex == 'female'].value_counts()
df=pd.DataFrame({'男性':survived_m, '女性':survived_f})
df.plot(kind='bar', stacked=True)
plt.xlabel('性别')
plt.ylabel('人数')
plt.title('性别与获救的关系')
plt.show()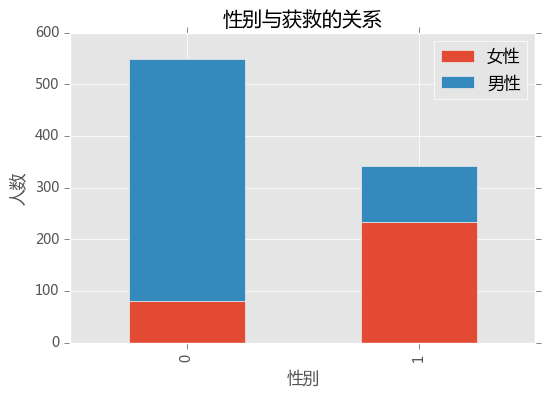
女性貌似更容易获救
登船点
survived_0 = train_data.Embarked[train_data.Survived == 0].value_counts()
survived_1 = train_data.Embarked[train_data.Survived == 1].value_counts()
df=pd.DataFrame({'获救':survived_1, '未获救':survived_0})
df.plot(kind='bar', stacked=True)
plt.xlabel('登船点')
plt.ylabel('人数')
plt.title('登船点与获救的关系')
plt.show()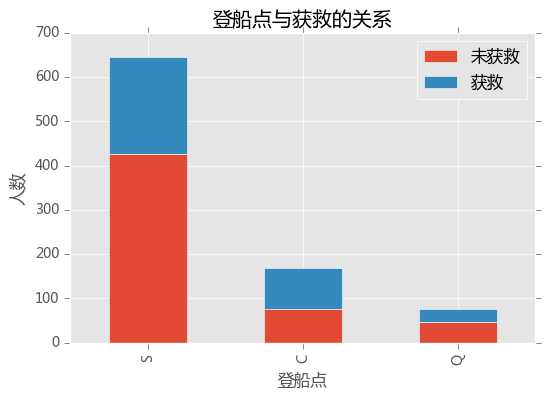
从比例上看,貌似在S点登船的不容易获救,但是在S点登船的人数较多,但从人数判断和获救的关系,两者关系不太明显
兄弟姐妹数量
survived_0 = train_data.SibSp[train_data.Survived == 0].value_counts()
survived_1 = train_data.SibSp[train_data.Survived == 1].value_counts()
df = pd.DataFrame({'获救': survived_1,'未获救': survived_0})
df.plot(kind = 'bar',stacked = True)
plt.xlabel('兄妹数量')
plt.ylabel('人数')
plt.title('兄妹数量与获救关系')
plt.show()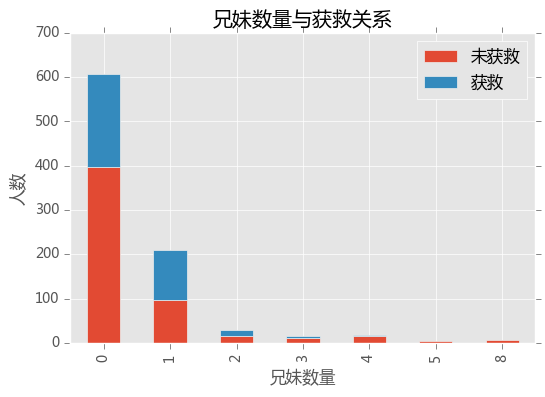
有一定关系,数量>3时,获救的比例减少
父母子女的数量
survived_0 = train_data.Parch[train_data.Survived == 0].value_counts()
survived_1 = train_data.Parch[train_data.Survived == 1].value_counts()
df = pd.DataFrame({'获救': survived_1,'未获救': survived_0})
df.plot(kind = 'bar',stacked = True)
plt.xlabel('父母子女数量')
plt.ylabel('人数')
plt.title('父母子女数量与获救关系')
plt.show()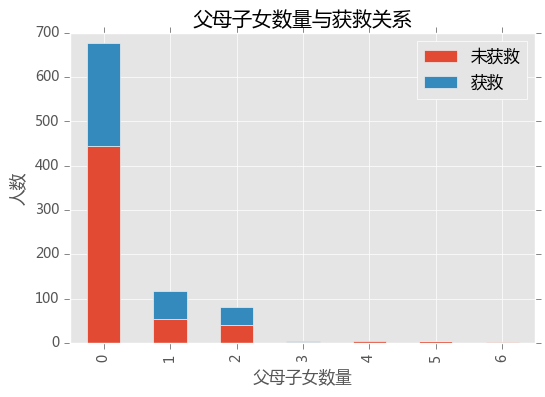
貌似关系不大
客舱信息
train_data.Cabin.value_counts()C23 C25 C27 4
G6 4
B96 B98 4
F33 3
F2 3
E101 3
C22 C26 3
D 3
E8 2
E25 2
C123 2
B18 2
B51 B53 B55 2
E33 2
C83 2
B58 B60 2
D35 2
B5 2
C78 2
E67 2
D20 2
F G73 2
E44 2
F4 2
C52 2
C2 2
B20 2
E121 2
D17 2
C126 2
..
A32 1
A7 1
D10 D12 1
F G63 1
D37 1
E36 1
C82 1
A10 1
C90 1
C103 1
C32 1
C128 1
B71 1
E58 1
A34 1
A14 1
F E69 1
E38 1
C50 1
B94 1
C49 1
B3 1
C106 1
C101 1
B79 1
B4 1
C104 1
D21 1
E63 1
B78 1
Name: Cabin, Length: 147, dtype: int64
缺失值很多,数值不集中,先把cabin缺失与否作为条件,看看和获救的关系
survived_cabin = train_data.Survived[pd.notnull(train_data.Cabin)].value_counts()
survived_nocabin = train_data.Survived[pd.isnull(train_data.Cabin)].value_counts()
df = pd.DataFrame({'有':survived_cabin,'无':survived_nocabin}).transpose()
df.plot(kind = 'bar',stacked = True)
plt.xlabel('cabin有无')
plt.ylabel('人数')
plt.title('cabin有无和获救关系')
plt.show(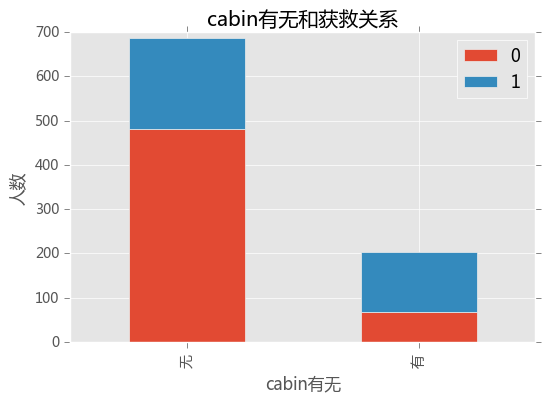
有的话获救的概率会高些
数据预处理
补全缺失值Age、Cabin、Emarked
利用随机森林预测缺失的age值,补全
定义补全函数
from sklearn.ensemble import RandomForestRegressor
def set_miss_age(df):
age_df = df[['Age','Fare','Parch','SibSp','Pclass']]#只拿出数值型的特征预测Age
know_age = age_df[age_df.Age.notnull()].as_matrix()#已知age值的特征作为训练集
unknow_age = age_df[age_df.Age.isnull()].as_matrix()#未知的作为测试集预测年龄
X = know_age[:,1:]
y = know_age[:,0]
test_age = unknow_age[:,1:]
model = RandomForestRegressor(random_state = 2018,n_estimators = 2000,n_jobs = -1)
model.fit(X,y)
pre_age = model.predict(test_age)
df.loc[(df.Age.isnull()),'Age'] = pre_age
return df,modeltrain_data,model = set_miss_age(train_data)Cabin缺失值用No填充、非缺失值用Yes填充
def set_cabin(df):
df.loc[(df.Cabin.notnull()),'Cabin'] = 'Yes'
df.loc[(df.Cabin.isnull()),'Cabin'] = 'No'
return dftrain_data = set_cabin(train_data)Embarked缺失值3个,用较多的S填充
train_data.Embarked = train_data.Embarked.fillna('S')查看补全后的数据
train_data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 891 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 891 non-null object Embarked 891 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB
缺失值补全了
简单的特征工程
利用pd.get_dummies把Cabin、Embarked、Sex、Pclass做成one-hot数据(特征因子化)
dum_cabin = pd.get_dummies(train_data.Cabin,prefix = 'Cabin')
dum_embark = pd.get_dummies(train_data.Embarked,prefix = 'Embarked')
dum_sex = pd.get_dummies(train_data.Sex,prefix = 'Sex')
dum_pclass = pd.get_dummies(train_data.Pclass,prefix = 'Pclass')
df = pd.concat([train_data, dum_cabin, dum_embark, dum_sex, dum_pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)#Name、Ticket特征丢弃df.head()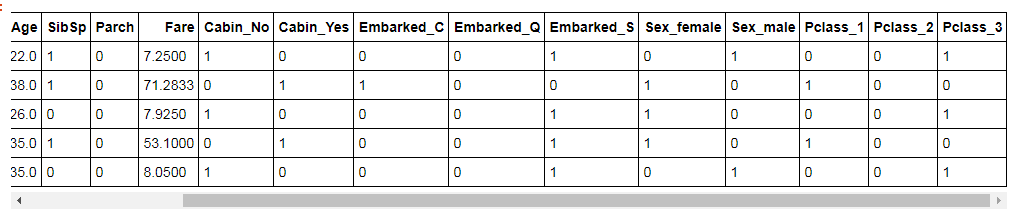
目测没什么问题
对Age、Fare归一化,有利于更快的梯度下降
from sklearn import preprocessing
scaler = preprocessing.StandardScaler()
df['Age_scaled'] = scaler.fit_transform(df['Age'].values.reshape(-1,1))
df['Fare_scaled'] = scaler.fit_transform(df['Fare'].values.reshape(-1,1))df.head()
目测没什么问题
建模前同样处理下test数据集
data_test = pd.read_csv(r'C:\Users\Administrator\Desktop\test.csv')
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
X = null_age[:, 1:]
predictedAges = model.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_cabin(data_test)
dum_cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dum_embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dum_sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dum_pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dum_cabin, dum_embarked, dum_sex, dum_pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'].values.reshape(-1,1))
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'].values.reshape(-1,1))df_test.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 17 columns): PassengerId 418 non-null int64 Age 418 non-null float64 SibSp 418 non-null int64 Parch 418 non-null int64 Fare 418 non-null float64 Cabin_No 418 non-null uint8 Cabin_Yes 418 non-null uint8 Embarked_C 418 non-null uint8 Embarked_Q 418 non-null uint8 Embarked_S 418 non-null uint8 Sex_female 418 non-null uint8 Sex_male 418 non-null uint8 Pclass_1 418 non-null uint8 Pclass_2 418 non-null uint8 Pclass_3 418 non-null uint8 Age_scaled 418 non-null float64 Fare_scaled 418 non-null float64 dtypes: float64(4), int64(3), uint8(10) memory usage: 27.0 KB
处理方式和train_data一样,目测没什么问题
看下
df_test.head()
ok
拿出train_data的featurn和label
train_df = df[['Survived','Age_scaled','SibSp','Parch','Fare_scaled','Cabin_Yes','Cabin_No','Embarked_C','Embarked_S','Embarked_Q','Sex_female','Sex_male','Pclass_1','Pclass_2','Pclass_3']]
train_np = train_df.as_matrix()
X = train_np[:,1:]
y = train_np[:,0]建模了
先来个LR看看
交叉验证调下参数
from sklearn import linear_model
from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import StratifiedKFold
LR = linear_model.LogisticRegression(penalty='l1', tol=1e-6)
param_grid = dict(C=[0.01,0.1,0.2,0.3,0.5,1.0])#正则化参数
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=2018)#10折交叉验证
GS = GridSearchCV(LR, param_grid, scoring='accuracy', n_jobs=-1,cv=list(kfold.split(X,y)))
GS_result = GS.fit(X,y)
print('Best: %f using %s'%(GS_result.best_score_,GS_result.best_params_))Best: 0.808081 using {'C': 0.5}
感觉正确率一般
预测下test,提交看下分数
test_cols = train_df.columns.tolist()[1:len(train_df.columns)]
test = df_test[test_cols]
predictions = GS_result.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv(r'C:\Users\Administrator\Desktop\predictions_LR.csv', index=False)提交kaggle得分:0.77033
试下随机森林
from sklearn.ensemble import RandomForestClassifier as RF
RF = RF()
param_grid = dict(max_features=[3,4,5,6],n_estimators=[100,200,300],min_samples_leaf=[3,4,5,6])
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=2018)
GS = GridSearchCV(RF, param_grid, scoring='accuracy', n_jobs=-1,cv=list(kfold.split(X,y)))
GS_result = GS.fit(X, y)
print('Best: %f using %s'% (GS_result.best_score_, GS_result.best_params_))Best: 0.833895 using {'n_estimators': 200, 'min_samples_leaf': 4, 'max_features': 6}
比LR好点
预测下test,提交看下分数
test_cols = train_df.columns.tolist()[1:len(train_df.columns)]
test = df_test[test_cols]
predictions = GS_result.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv(r'C:\Users\Administrator\Desktop\predictions_RF.csv', index=False)提交kaggle得分:0.75119
test的正确率不如LR
SVM
from sklearn.svm import SVC
svm = SVC()
param_grid = dict(C=[0.01,0.1,1],kernel = ['linear','rbf','sigmoid'])
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=2018)
GS = GridSearchCV(svm, param_grid, scoring='accuracy', n_jobs=-1,cv=list(kfold.split(X,y)))
GS_result = GS.fit(X, y)
print('Best: %f using %s' % (GS_result.best_score_, GS_result.best_params_))Best: 0.826038 using {'C': 1, 'kernel': 'rbf'}
test_cols = train_df.columns.tolist()[1:len(train_df.columns)]
test = df_test[test_cols]
predictions = GS_result.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv(r'C:\Users\Administrator\Desktop\predictions_SVM.csv', index=False)提交kaggle得分:0.77011
Adaboost
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
dt_stump=DecisionTreeClassifier(max_depth=5,min_samples_leaf=5)
Ada = AdaBoostClassifier(dt_stump,algorithm='SAMME.R')
params = {'n_estimators':[700,800,900], 'learning_rate':[0.001,0.01, 0.1,0.2,0.3]}
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
GS = GridSearchCV(Ada, params, scoring='accuracy', n_jobs=-1,cv=list(kfold.split(X,y)))
GS_result = GS.fit(X, y)
print('Best: %f using %s' % (GS_result.best_score_, GS_result.best_params_))Best: 0.832772 using {'learning_rate': 0.001, 'n_estimators': 700}
test_cols = train_df.columns.tolist()[1:len(train_df.columns)]
test = df_test[test_cols]
predictions = GS_result.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv(r'C:\Users\Administrator\Desktop\predictions_Ada.csv', index=False)提交kaggle得分:0.74641
KNN
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
params = {'n_neighbors':list(range(2,10)),'weights':['uniform','distance'],'leaf_size':list(range(1,15,1))}
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
GS = GridSearchCV(knn, params, scoring='accuracy', n_jobs=-1,cv=list(kfold.split(X,y)))
GS_result = GS.fit(X, y)
print('Best: %f using %s' % (GS_result.best_score_, GS_result.best_params_))Best: 0.814815 using {'leaf_size': 1, 'weights': 'uniform', 'n_neighbors': 5}
test_cols = train_df.columns.tolist()[1:len(train_df.columns)]
test = df_test[test_cols]
predictions = GS_result.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv(r'C:\Users\Administrator\Desktop\predictions_Knn.csv', index=False)提交kaggle得分:0.72248
最好的分类器是LR,其次是SVM,得分都在0.77以上
利用VotingClassifier尝试下模型堆叠
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import RandomForestClassifier as RF
from xgboost import XGBClassifier as xgb
from sklearn.svm import SVC
from sklearn import neighbors
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
LR = linear_model.LogisticRegression(penalty='l1', tol=1e-6,C=0.5)
RF = RF(n_estimators= 200, min_samples_leaf= 4, max_features= 6)
svm = SVC(kernel = 'rbf',C=1)
dt_stump=DecisionTreeClassifier(max_depth=5,min_samples_leaf=5)
Ada = AdaBoostClassifier(dt_stump,algorithm='SAMME.R',learning_rate= 0.001, n_estimators= 700)
knn = neighbors.KNeighborsClassifier(weights = 'uniform',leaf_size= 1, n_neighbors= 5)
clf_vc = VotingClassifier(estimators=[('LR', LR), ('RF', RF), ('svm', svm), ('Ada', Ada), ('KNN', knn)])
clf_vc.fit(X,y)VotingClassifier(estimators=[('LR', LogisticRegression(C=0.5, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l1', random_state=None, solver='liblinear', tol=1e-06,
verbose=0, warm_start=False)), ('RF', RandomFo...owski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform'))],
flatten_transform=None, n_jobs=1, voting='hard', weights=None)
res=clf_vc.predict(X)
acc = sum(res==y)/len(res)
print(acc)0.8709315375982043
训练集上表现要比单个模型要好
提交看下分数
est_cols = train_df.columns.tolist()[1:len(train_df.columns)]
test = df_test[test_cols]
predictions = clf_vc.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv(r'C:\Users\Administrator\Desktop\predictions_stack.csv', index=False)提交kaggle得分:0.78468
有所提高

排名不是很好,主要在特征工程做的不够,主要是了解下比赛的过程和模型的建立,再接再厉吧
最后想在堆叠上交叉验证调参
from sklearn import linear_model
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import RandomForestClassifier as RF
from xgboost import XGBClassifier as xgb
from sklearn.svm import SVC
from sklearn import neighbors
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import StratifiedKFold
LR = linear_model.LogisticRegression()
RF = RF()
svm = SVC(kernel = 'rbf')
dt_stump=DecisionTreeClassifier(max_depth=5,min_samples_leaf=5)
Ada = AdaBoostClassifier(dt_stump,algorithm='SAMME.R')
knn = neighbors.KNeighborsClassifier(weights = 'uniform')
clf_vc = VotingClassifier(estimators=[('LR', LR), ('RF', RF), ('svm', svm), ('Ada', Ada), ('KNN', knn)])
params = {'LR__C': [0.01,0.1,0.2,0.3],
'RF__n_estimators': [300,500,700],'RF__max_features':[3,4,5,6],'RF__min_samples_leaf':[3,4,5,6],
'svm__C':[0.01,0.1,1],
'Ada__n_estimators':[700,800,900], 'Ada__learning_rate':[0.001,0.01, 0.1,0.2,0.3],
'KNN__n_neighbors':list(range(2,6)),'KNN__leaf_size':list(range(1,10))}
GS = GridSearchCV(estimator=clf_vc, param_grid=params,n_jobs=-1, cv=5)
GS_result = GS.fit(X, y)
print('Best: %f using %s' % (GS_result.best_score_, GS_result.best_params_))