import pandas #ipython notebook
titanic = pandas.read_csv("titanic_train.csv")
titanic.head(5)
#print (titanic.describe())
print (titanic.describe())
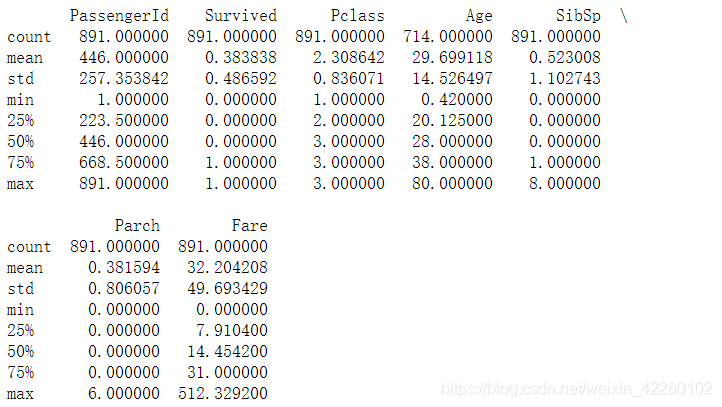
发现age中发生了数据缺失!!!!
需要进行数据预处理:
numpy模块下的median作用为:计算沿指定轴的均值,返回数组元素的均值。
median(a,
axis=None,
out=None,
overwrite_input=False,
keepdims=False)
其中各参数为:
a:输入的数组;
axis:计算哪个轴上的均值,比如输入是二维数组,那么axis=0对应行,axis=1对应列;
out:用于放置求取中位数后的数组。 它必须具有与预期输出相同的形状和缓冲区长度;
overwrite_input :一个bool型的参数,默认为Flase。如果为True那么将直接在数组内存中计算,这意味着计算之后原数组没办法保存,但是好处在于节省内存资源,Flase则相反;
keepdims:一个bool型的参数,默认为Flase。如果为True那么求取中位数的那个轴将保留在结果中;
具体使用:
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
print(titanic.describe())

将字符变成数值:
print (titanic["Sex"].unique())
# Replace all the occurences of male with the number 0.
titanic.loc[titanic["Sex"] == "male", "Sex"] = 0
titanic.loc[titanic["Sex"] == "female", "Sex"] = 1

print (titanic["Embarked"].unique())
# 不能用均值填充了,谁最多就用谁就可以了
titanic["Embarked"] = titanic["Embarked"].fillna('S')
titanic.loc[titanic["Embarked"] == "S", "Embarked"] = 0
titanic.loc[titanic["Embarked"] == "C", "Embarked"] = 1
titanic.loc[titanic["Embarked"] == "Q", "Embarked"] = 2

使用线性回归算法进行预测:
这里我们还是使用sklearn
K折交叉验证时使用:
KFold(n_split, shuffle, random_state)
参数:
n_split:要划分的折数
shuffle: 每次都进行shuffle,测试集中折数的总和就是训练集的个数
random_state:随机状态
# Import the linear regression class
from sklearn.linear_model import LinearRegression
# Sklearn also has a helper that makes it easy to do cross validation
# from sklearn.cross_validation import KFold
from sklearn.model_selection import KFold
# The columns we'll use to predict the target
# 指定传给分类器哪些特征
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# Initialize our algorithm class
# 实例化模型
alg = LinearRegression()
# Generate cross validation folds for the titanic dataset. It return the row indices corresponding to train and test.
# We set random_state to ensure we get the same splits every time we run this.
# kf = KFold(titanic.shape[0], n_folds=3, random_state=1)
# 交叉验证
kf = KFold(n_splits=3, shuffle=False, random_state=1)
predictions = []
for train, test in kf.split(titanic[predictions]):
# The predictors we're using the train the algorithm. Note how we only take the rows in the train folds.
train_predictors = (titanic[predictors].iloc[train,:])
# The target we're using to train the algorithm.
train_target = titanic["Survived"].iloc[train]
# Training the algorithm using the predictors and target.
alg.fit(train_predictors, train_target)
# We can now make predictions on the test fold
test_predictions = alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictions)
import numpy as np
# The predictions are in three separate numpy arrays. Concatenate them into one.
# We concatenate them on axis 0, as they only have one axis.
# 将多个数组进行拼接
predictions = np.concatenate(predictions, axis=0)
# Map predictions to outcomes (only possible outcomes are 1 and 0)
predictions[predictions > .5] = 1
predictions[predictions <=.5] = 0
accuracy = sum(predictions[predictions == titanic["Survived"]]) / len(predictions)
print (accuracy)
不知道为什么结果不对!!!

from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
# Initialize our algorithm
alg = LogisticRegression(random_state=1)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
scores = model_selection.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3)
# Take the mean of the scores (because we have one for each fold)
print(scores.mean())

使用随机森林改进模型
titanic_test = pandas.read_csv("test.csv")
titanic_test["Age"] = titanic_test["Age"].fillna(titanic["Age"].median())
titanic_test["Fare"] = titanic_test["Fare"].fillna(titanic_test["Fare"].median())
titanic_test.loc[titanic_test["Sex"] == "male", "Sex"] = 0
titanic_test.loc[titanic_test["Sex"] == "female", "Sex"] = 1
titanic_test["Embarked"] = titanic_test["Embarked"].fillna("S")
titanic_test.loc[titanic_test["Embarked"] == "S", "Embarked"] = 0
titanic_test.loc[titanic_test["Embarked"] == "C", "Embarked"] = 1
titanic_test.loc[titanic_test["Embarked"] == "Q", "Embarked"] = 2
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# Initialize our algorithm with the default paramters
# n_estimators is the number of trees we want to make
# min_samples_split is the minimum number of rows we need to make a split
# min_samples_leaf is the minimum number of samples we can have at the place where a tree branch ends (the bottom points of the tree)
alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
kf = model_selection.KFold(n_splits=3, random_state=1)
scores = model_selection.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=kf)
# Take the mean of the scores (because we have one for each fold)
print(scores.mean())

简单的调参
alg = RandomForestClassifier(random_state=1, n_estimators=100, min_samples_split=4, min_samples_leaf=2)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
kf = model_selection.KFold(3, random_state=1)
scores = model_selection.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=kf)
# Take the mean of the scores (because we have one for each fold)
print(scores.mean())

模型优化差不多了,但是还想优化应该怎么办呢?
可以,需要增加其他特征
# Generating a familysize column
titanic["FamilySize"] = titanic["SibSp"] + titanic["Parch"]
# The .apply method generates a new series
titanic["NameLength"] = titanic["Name"].apply(lambda x: len(x))
import re
# A function to get the title from a name.
def get_title(name):
# Use a regular expression to search for a title. Titles always consist of capital and lowercase letters, and end with a period.
title_search = re.search(' ([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
# Get all the titles and print how often each one occurs.
titles = titanic["Name"].apply(get_title)
print(pandas.value_counts(titles))
# Map each title to an integer. Some titles are very rare, and are compressed into the same codes as other titles.
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2}
for k,v in title_mapping.items():
titles[titles == k] = v
# Verify that we converted everything.
print(pandas.value_counts(titles))
# Add in the title column.
titanic["Title"] = titles
import re
# A function to get the title from a name.
def get_title(name):
# Use a regular expression to search for a title. Titles always consist of capital and lowercase letters, and end with a period.
title_search = re.search('([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
# Get all the titles and print how often each one occurs.
titles = titanic["Name"].apply(get_title)
print(pandas.value_counts(titles))
# Map each title to an integer. Some titles are very rare, and are compressed into the same codes as other titles.
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2}
for k,v in title_mapping.items():
titles[titles == k] = v
# Verify that we converted everything.
print(pandas.value_counts(titles))
# Add in the title column.
titanic["Title"] = titles
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
import matplotlib.pyplot as plt
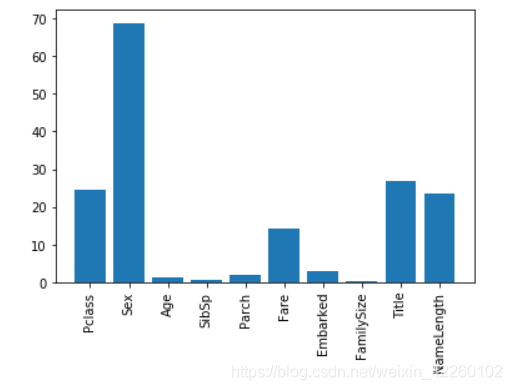
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "FamilySize", "Title", "NameLength"]
# Perform feature selection
selector = SelectKBest(f_classif, k=5)
selector.fit(titanic[predictors], titanic["Survived"])
# Get the raw p-values for each feature, and transform from p-values into scores
scores = -np.log10(selector.pvalues_)
# Plot the scores. See how "Pclass", "Sex", "Title", and "Fare" are the best?
plt.bar(range(len(predictors)), scores)
plt.xticks(range(len(predictors)), predictors, rotation='vertical')
plt.show()
# Pick only the four best features.
predictors = ["Pclass", "Sex", "Fare", "Title"]
alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=8, min_samples_leaf=4)
算法集成
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
# The algorithms we want to ensemble.
# We're using the more linear predictors for the logistic regression, and everything with the gradient boosting classifier.
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), ["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize", "Title",]],
[LogisticRegression(random_state=1), ["Pclass", "Sex", "Fare", "FamilySize", "Title", "Age", "Embarked"]]
]
# Initialize the cross validation folds
kf = KFold(3, random_state=1)
predictions = []
for train, test in kf.split(titanic["Survived"]):
train_target = titanic["Survived"].iloc[train]
full_test_predictions = []
# Make predictions for each algorithm on each fold
for alg, predictors in algorithms:
# Fit the algorithm on the training data.
alg.fit(titanic[predictors].iloc[train,:], train_target)
# Select and predict on the test fold.
# The .astype(float) is necessary to convert the dataframe to all floats and avoid an sklearn error.
test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1]
full_test_predictions.append(test_predictions)
# Use a simple ensembling scheme -- just average the predictions to get the final classification.
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
# Any value over .5 is assumed to be a 1 prediction, and below .5 is a 0 prediction.
test_predictions[test_predictions <= .5] = 0
test_predictions[test_predictions > .5] = 1
predictions.append(test_predictions)
# Put all the predictions together into one array.
predictions = np.concatenate(predictions, axis=0)
# Compute accuracy by comparing to the training data.
accuracy = sum(predictions[predictions == titanic["Survived"]]) / len(predictions)
print(accuracy)

