这是github上RL练习的笔记
https://github.com/dennybritz/reinforcement-learning/tree/master/DP
Implement Policy Evaluation in Python (Gridworld)
首先观察opai env.P的构造
env: OpenAI env. env.P represents the transition probabilities of the environment. env.P[s][a] is a list of transition tuples (prob, next_state, reward, done). env.nS is a number of states in the environment. env.nA is a number of actions in the environment.

回忆policy evaluation的迭代公式:
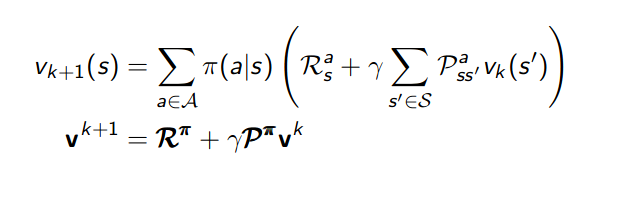
使用向量进行计算
R_pi = np.zeros(shape=(env.nS)) P_pi = np.zeros(shape=(env.nS,env.nS)) v_pi = np.zeros(shape=(env.nS)) for s,s_item in env.P.items(): for a,a_item in s_item.items(): for dis in a_item: prob,next_state,reward,_ = dis R_pi[s] += policy[s,a] * reward P_pi[s,next_state] += policy[s,a] * prob v_change = np.ones(shape=(env.nS,env.nS)) while (np.abs(v_change) > theta).any(): v_change = R_pi + discount_factor * np.dot(P_pi,v_pi) - v_pi v_pi += v_change
首先展开env.P计算R和P,之后进行迭代至收敛