本文是翻译,原文地址为Tarang Shah的博客
mAP
mAP,Mean Average Precision,平均精度,用于评估预测的定位和分类的算法,其对于评估定位模型、目标检测模型和分割模型是有效的。【因为用于分类的precision不能直接用于具有定位问题的模型,所以引入mAP概念】
在目标检测中,这几个概念有如下解释(下面有详细解释):
- Precision
- 在某个确定的 Recall下,(某类别)能在某图片上取得的 precision的最大值
- AP
- 在某些确定的 Recall下,某个类别在整个数据集下的 Average Precision
- mAP
- 在某些确定的 Recall下,模型在整个数据集下所有类的 mean AP
Ground Truth
对于一个评估算法,其测量标准就是和ground truth的比较(Training,Validation,Test datasets都有这个ground truth信息)。
对于目标检测问题,ground truth包括images,objects的classes set,和每个objects的bounding boxes。
也就是说,对于训练而言,我们的模型能得到的是图片,一张具体的图片如下:

以及一个坐标和类别的列表的集合,一个具体的对象的 ground truth sets如下:

将ground truth sets可视化到图片上,展示如下:

计算mAP
使用IoU来判断每个对象的检测边框的正确度。
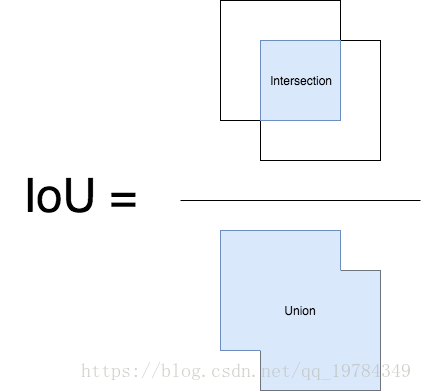
IoU
IoU,Intersection over Union,交并集,其在目标检测的应用是预测边框与ground truth boxes的交集与并集的比率。
Confidence
Confidence,置信度,每个边框都有一个置信度,其与置信度门槛比较,低于置信度阈值的,我们把这些boxes当做负的(框);反之,高于置信度阈值的,当做正的(框)。
Precision,Recall
如果预测结果是正的,那么其有两种可能,⑴ 正确的,True(就是预测的和labels是一致的,在检测里,就是IoU大于一定阈值的边框,一般认为是
);⑵ 错误的,False。这两种正预测对应的结果分别是:⑴ 正阳性,True Positive;⑵ 假阳性,False Positive
对于每一张输入模型的图片(训练,测试,验证),我们都有对应的ground truth data,这告诉我们这张图片有多少对象。我们把正框(比confidence阈值大的框)与ground truth计算IoU(对一张图片的每个类都进行一遍),将这个IoU与IoU阈值比较,就能得到TP,正阳性和FP,假阳性。
从上面的推导可以看出,目标检测的Precision,Recall由IoU阈值和confidence阈值两个变量决定。
mAP
信息检索(Information Retrieval)和目标检测都有使用mAP的概念,但这两个领域的mAP计算方式不一样。
每个数据集评估用的IoU阈值不同(VOC是 ,COCO是从 ),对于不同模型,其confidence的影响不同(一个模型confidence为 的,可能相当于另一个模型的 )。所以我们需要一个无关模型的评判标准。
对于一个给定的任务和(某个)类别,其precision/recall曲线是由方法得出的(对于不同的阈值有不同的值,所有有曲线)。AP,Average Precision就是这个类别的precision/recall曲线下的积分面积,其定义为 个recall水平的precision的平均值。(也就是说对于不同的类别,都有一个AP,这些AP的平均值就是mAP,mean Average Precision)
这也就意味着我们选择 个confidence阈值,使得Recall达到 ,AP就是这 个值下的平均精度(所有图片)。
比较mAP时需要注意的点
- 对于目标检测来说,很难找到一个绝对量化的标准来衡量模型的输出,但mAP是一个很好的相对度量。它可以帮助我们度量一个数据集上的两个检测算法的结果。
- AP是依赖于训练数据的分布的(对于每个类),也就是说不同类的结果可能差别很大(可能mAP的结果不过,但不同类的AP差别很多)。所以,对于模型结果而言,我们可以输出每个类别的AP(这也是一个可取的方法帮助我们分析模型的结果,我们可以以此为依据添加样本)。