go语言版本:1.9.2 linux/amd64
InfluxDB版本:1.7
influxdb存储引擎tsdb代码目录:github.com\influxdata\influxdb\tsdb
可以先阅读以下对于tsdb的官方文档。 其采用的存储模型是LSM-Tree模型,对其进行了一定的改造。将其称之为Time-Structured Merge Tree (TSM)
当一个point写入时,influxdb根据其所属的database、measurements和timestamp选取一个对应的shard。每个 shard对应一个TSM存储引擎。每个shard对应一段时间范围的存储。
一个TSM存储引擎包含:
- In-Memory Index 在shard之间共享,提供measurements,tags,和series的索引
- WAL 同其他database的binlog一样,当WAL的大小达到一定大小后,会重启开启一个WAL文件。
- Cache 内存中缓存的WAL,加速查找
- TSM Files 压缩后的series数据
- FileStore TSM Files的封装
- Compactor 存储数据的比较器
- Compaction Planner 用来确定哪些TSM文件需要compaction,同时避免并发compaction之间的相互干扰
- Compression 用于压缩持久化文件
- Writers/Readers 用于访问文件
shard通过CreateShard 来创建。可以看出其依次创建了所需的文件目录,然后创建Index 和Shard 数据结构。
Store:
github.com\influxdata\influxdb\tsdb\store.go
// Store manages shards and indexes for databases.
type Store struct {
mu sync.RWMutex
shards map[uint64]*Shard // 所有 shards 的索引,key 为其 shard ID
databases map[string]struct{}
sfiles map[string]*SeriesFile
SeriesFileMaxSize int64 // Determines size of series file mmap. Can be altered in tests.
path string // 数据库文件在磁盘上的存储路径
// shared per-database indexes, only if using "inmem".
indexes map[string]interface{}
// Maintains a set of shards that are in the process of deletion.
// This prevents new shards from being created while old ones are being deleted.
pendingShardDeletes map[uint64]struct{}
EngineOptions EngineOptions
baseLogger *zap.Logger
Logger *zap.Logger
closing chan struct{}
wg sync.WaitGroup
opened bool
}Store 是存储结构中最顶层的抽象结构体,主要包含了 InfluxDB 中所有数据库的 索引 和 实际存储数据的 Shard 对象。InfluxDB 中的其他服务都需要通过 Store 对象对底层数据进行操作。store是influxdb的存储模块,全局只有一个该实例。主要负责将数据按一定格式写入磁盘,并且维护influxdb相关的 存储概念。例如:创建/删除Shard、创建/删除retention policy、调度shard的compaction、以及最重要的WriteToShard 等等。在store内部又包含index和engine2个抽象概念,index是对应shard的索引,engine是对应shard的存储实现, 不同的engine采用不同的存储格式和策略。后面要讲的tsdb其实就是一个engine的实现。在influxdb启动时,会创建 一个store实例,然后Open它,初始化时,它会加载已经存在的Shard ,并启动一个Shard监控任务, 监控任务负责调度每个Shard的Compaction和对使用inmem索引的Shard计算每种Tag拥有的数值的基数(与配置中max-values-per-tag有关)。
Shard:

github.com\influxdata\influxdb\tsdb\shard.go
// Shard represents a self-contained time series database. An inverted index of
// the measurement and tag data is kept along with the raw time series data.
// Data can be split across many shards. The query engine in TSDB is responsible
// for combining the output of many shards into a single query result.
type Shard struct {
path string // shard 在磁盘上的路径
walPath string // 对应的 wal 文件所在目录
id uint64 // shard ID,就是在磁盘上的文件名
database string // 所在数据库名
retentionPolicy string // 对应存储策略名
sfile *SeriesFile
options EngineOptions
mu sync.RWMutex
_engine Engine // 存储引擎,抽象接口,可插拔设计,目前是 tsm1 存储引擎
index Index
enabled bool
// expvar-based stats.
stats *ShardStatistics
defaultTags models.StatisticTags
baseLogger *zap.Logger
logger *zap.Logger
EnableOnOpen bool
// CompactionDisabled specifies the shard should not schedule compactions.
// This option is intended for offline tooling.
CompactionDisabled bool
}每一个 Shard 对象都有一个单独的底层数据存储引擎,engine 负责和底层的文件数据打交道。Shard 还保存了一个指向所在数据库索引的指针,便于快速检索到该 Shard 中的元数据信息。存储引擎,抽象接口,可插拔设计,目前是 tsm1 存储引擎。Index也是一个抽象接口,可插拔设计,目前有inmem和tsi1。
Engine:
github.com\influxdata\influxdb\tsdb\engine.go
Engine 是一个抽象接口,可插拔设计,对于 InfluxDB 来说,可以很方便地替换掉底层的存储引擎,目前是 tsm1 存储引擎。
// Engine represents a swappable storage engine for the shard.
type Engine interface {
Open() error
Close() error
SetEnabled(enabled bool)
SetCompactionsEnabled(enabled bool)
ScheduleFullCompaction() error
WithLogger(*zap.Logger)
LoadMetadataIndex(shardID uint64, index Index) error
CreateSnapshot() (string, error)
Backup(w io.Writer, basePath string, since time.Time) error
Export(w io.Writer, basePath string, start time.Time, end time.Time) error
Restore(r io.Reader, basePath string) error
Import(r io.Reader, basePath string) error
Digest() (io.ReadCloser, int64, error)
CreateIterator(ctx context.Context, measurement string, opt query.IteratorOptions) (query.Iterator, error)
CreateCursorIterator(ctx context.Context) (CursorIterator, error)
IteratorCost(measurement string, opt query.IteratorOptions) (query.IteratorCost, error)
WritePoints(points []models.Point) error
CreateSeriesIfNotExists(key, name []byte, tags models.Tags) error
CreateSeriesListIfNotExists(keys, names [][]byte, tags []models.Tags) error
DeleteSeriesRange(itr SeriesIterator, min, max int64) error
DeleteSeriesRangeWithPredicate(itr SeriesIterator, predicate func(name []byte, tags models.Tags) (int64, int64, bool)) error
MeasurementsSketches() (estimator.Sketch, estimator.Sketch, error)
SeriesSketches() (estimator.Sketch, estimator.Sketch, error)
SeriesN() int64
MeasurementExists(name []byte) (bool, error)
MeasurementNamesByRegex(re *regexp.Regexp) ([][]byte, error)
MeasurementFieldSet() *MeasurementFieldSet
MeasurementFields(measurement []byte) *MeasurementFields
ForEachMeasurementName(fn func(name []byte) error) error
DeleteMeasurement(name []byte) error
HasTagKey(name, key []byte) (bool, error)
MeasurementTagKeysByExpr(name []byte, expr influxql.Expr) (map[string]struct{}, error)
TagKeyCardinality(name, key []byte) int
// Statistics will return statistics relevant to this engine.
Statistics(tags map[string]string) []models.Statistic
LastModified() time.Time
DiskSize() int64
IsIdle() bool
Free() error
io.WriterTo
}Index:
github.com\influxdata\influxdb\tsdb\engine.go
index是一个抽象接口
type Index interface {
Open() error
Close() error
WithLogger(*zap.Logger)
Database() string
MeasurementExists(name []byte) (bool, error)
MeasurementNamesByRegex(re *regexp.Regexp) ([][]byte, error)
DropMeasurement(name []byte) error
ForEachMeasurementName(fn func(name []byte) error) error
InitializeSeries(keys, names [][]byte, tags []models.Tags) error
CreateSeriesIfNotExists(key, name []byte, tags models.Tags) error
CreateSeriesListIfNotExists(keys, names [][]byte, tags []models.Tags) error
DropSeries(seriesID uint64, key []byte, cascade bool) error
DropMeasurementIfSeriesNotExist(name []byte) error
MeasurementsSketches() (estimator.Sketch, estimator.Sketch, error)
SeriesN() int64
SeriesSketches() (estimator.Sketch, estimator.Sketch, error)
SeriesIDSet() *SeriesIDSet
HasTagKey(name, key []byte) (bool, error)
HasTagValue(name, key, value []byte) (bool, error)
MeasurementTagKeysByExpr(name []byte, expr influxql.Expr) (map[string]struct{}, error)
TagKeyCardinality(name, key []byte) int
// InfluxQL system iterators
MeasurementIterator() (MeasurementIterator, error)
TagKeyIterator(name []byte) (TagKeyIterator, error)
TagValueIterator(name, key []byte) (TagValueIterator, error)
MeasurementSeriesIDIterator(name []byte) (SeriesIDIterator, error)
TagKeySeriesIDIterator(name, key []byte) (SeriesIDIterator, error)
TagValueSeriesIDIterator(name, key, value []byte) (SeriesIDIterator, error)
// Sets a shared fieldset from the engine.
FieldSet() *MeasurementFieldSet
SetFieldSet(fs *MeasurementFieldSet)
// Size of the index on disk, if applicable.
DiskSizeBytes() int64
// Bytes estimates the memory footprint of this Index, in bytes.
Bytes() int
// To be removed w/ tsi1.
SetFieldName(measurement []byte, name string)
Type() string
// Returns a unique reference ID to the index instance.
// For inmem, returns a reference to the backing Index, not ShardIndex.
UniqueReferenceID() uintptr
Rebuild()
}看一下tsm1 engine结构体:
github.com\influxdata\influxdb\tsdb\engine\tsm1\engine.go
// Engine represents a storage engine with compressed blocks.
type Engine struct {
mu sync.RWMutex
index tsdb.Index // 数据库索引信息,目前没和存储引擎放在一起,看起来后续会更改设计作为存储引擎的一部分
// The following group of fields is used to track the state of level compactions within the 以下字段组用于跟踪其中的级别压缩状态
// Engine. The WaitGroup is used to monitor the compaction goroutines, the 'done' channel is used to signal those goroutines to shutdown. Every request to disable level compactions will call 'Wait' on 'wg', with the first goroutine to arrive (levelWorkers == 0 while holding the lock) will close the done channel and re-assign 'nil' to the variable. Re-enabling will decrease 'levelWorkers', and when it decreases to zero, level compactions will be started back up again.
// WaitGroup用于监视压缩goroutines,'done'通道用于通知那些goroutine要关闭。 每个禁用级别压缩的请求都会在'wg'上调用'Wait',第一个goroutine到达(levelWorkers == 0,同时保持锁定)将关闭done通道并为变量重新分配'nil'。 重新启用会减少“levelWorkers”,当它减少到零时,级别压缩将再次启动。
wg *sync.WaitGroup // waitgroup for active level compaction goroutines
done chan struct{} // channel to signal level compactions to stop
levelWorkers int // Number of "workers" that expect compactions to be in a disabled state 期望压缩处于禁用状态的work数量
snapDone chan struct{} // channel to signal snapshot compactions to stop
snapWG *sync.WaitGroup // waitgroup for running snapshot compactions
id uint64
path string
sfile *tsdb.SeriesFile
logger *zap.Logger // Logger to be used for important messages
traceLogger *zap.Logger // Logger to be used when trace-logging is on.
traceLogging bool
fieldset *tsdb.MeasurementFieldSet // 所有 measurement 对应的 fields 对象
WAL *WAL // WAL 文件对象
Cache *Cache // WAL 文件在内存中的缓存
Compactor *Compactor // 压缩合并管理对象
CompactionPlan CompactionPlanner
FileStore *FileStore // 数据文件对象
MaxPointsPerBlock int
// CacheFlushMemorySizeThreshold specifies the minimum size threshold for
// the cache when the engine should write a snapshot to a TSM file
CacheFlushMemorySizeThreshold uint64 // Cache 超过指定大小后内容会被写入一个新的 TSM 文件
// CacheFlushWriteColdDuration specifies the length of time after which if
// no writes have been committed to the WAL, the engine will write
// a snapshot of the cache to a TSM file
CacheFlushWriteColdDuration time.Duration // Cache 超过多长时间后还没有数据写入,会将内容写入新的 TSM 文件
// WALEnabled determines whether writes to the WAL are enabled. If this is false,
// writes will only exist in the cache and can be lost if a snapshot has not occurred.
WALEnabled bool
// Invoked when creating a backup file "as new".创建备份文件“as new”时调用。
formatFileName FormatFileNameFunc
// Controls whether to enabled compactions when the engine is open 控制引擎打开时是否启用压缩
enableCompactionsOnOpen bool
stats *EngineStatistics
// Limiter for concurrent compactions.并发压缩的限制器。
compactionLimiter limiter.Fixed
scheduler *scheduler
// provides access to the total set of series IDs
seriesIDSets tsdb.SeriesIDSets
// seriesTypeMap maps a series key to field type
seriesTypeMap *radix.Tree
}tms1 存储引擎设计,参考github.com\influxdata\influxdb\tsdb\engine\tsm1\DESIGN.md
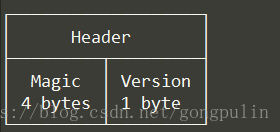
A TSM file由四部分组成:header, blocks, index and the footer

Header由一个magic number和一个版本号组成
Blocks data组成结构:
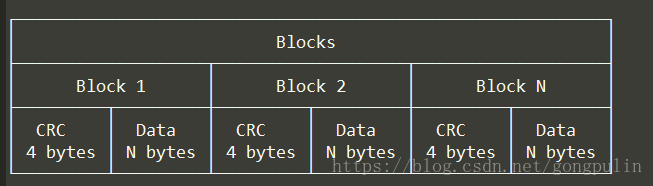
Blocks data是由CRC32和数据的序列。块数据对文件是不透明的。 CRC32用于恢复,以确保块由于我们控制之外的错误而未被破坏。块的长度存储在索引中。
Index组成结构:

索引由一系列索引条目组成,这些索引条目按键按字典顺序排序,然后按时间排序。每个索引条目如上图,每个块条目由块的最小和最大时间,块所在文件的偏移量以及块的大小组成。
索引结构可以提供对所有块的有效访问,以及减少获取块数据的时间成本。给定key和时间戳,我们确切地知道哪个文件包含该时间戳的块以及该块所在的位置以及要检索块的数据量。如果我们知道我们需要读取文件中的所有或多个块,我们可以使用该大小来确定给定IO中的读取量。
*存储在块数据中的块长度可能会被删除,因为我们将它存储在索引中
Footer组成结构:
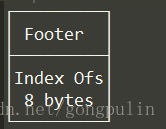
footer存储索引开头偏移量.