延续总结(1):pandas系列总结(1) --- pandas数据结构
实际使用中,我常用的DataFrame数据类型,下面了解DataFrame基本功能,基本数据集
import pandas as pd
import numpy as np
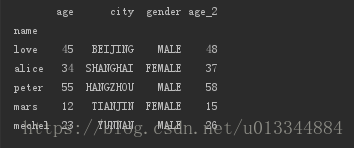
index = pd.Index(['love','alice','peter','mars','mechel'],name='name')
data = {'age':[45,34,55,12,23],
'city':['beijign','shanghai','hangzhou','tianjin','yunnan'],
'gender':['male','female','male','female','male']}
df_age = pd.DataFrame(data=data, index=index)
df_age['age_2'] = df_age.age + 3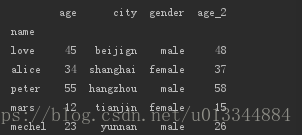
一、数据基本情况
1.数据集基本信息
查看数据集整体大小类型信息
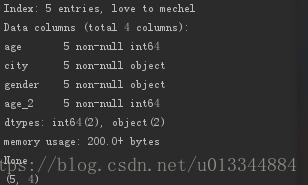
print(df_age.info()) #数据集大小类型
print(df_age.shape) #数据集行、列数
print(df_age.columns) #所有列名
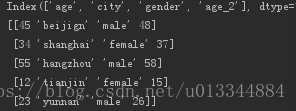
print(df_age.values) #所有数据
print(df_age.head(2)) #查看前两行
print(df_age.T) #数据转置输出: 12-3
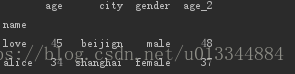
2.基本描述性统计
1.整体的均值、最值、标准差、四分位数等的描述统计
print(df_age.describe()) #输出数值字段的四分位、最值、均值等描述性统计量,结果为DataFrame
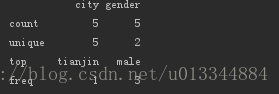
print(df_age.describe(include=['object'])) #非数值字段的统计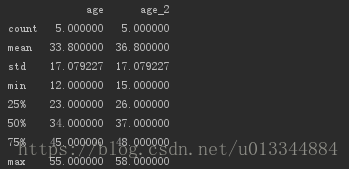
2.当个字段的统计量
print(df_age.age.max()) #age字段的最大值
print(df_age.age.cumsum()) #age字段的累加求和
print(df_age.age_2.value_counts()) #每个值出现次数的统计
print(df_age.age.idxmax()) #最大值对应的索引
print(df_age.age.idxmin()) #最小值对应的索引
print(df_age.age_2.quantile(0.1)) #十分位数
二、数据排序
Pandas 支持两种排序方式:按轴(索引或列)排序和按实际值排序。要改变原始数据集,需要设置参数inplace=True
1.根据索引 sort_index
#排序
#根据索引
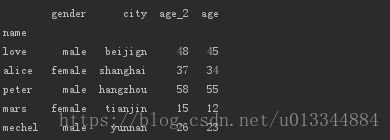
print(df_age.sort_index()) #默认按照索引进行排序
print(df_age.sort_index(axis=1,ascending=False)) #行排序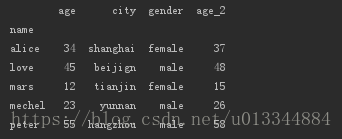
2.根据实际值 sort_values
#根据实际值
print(df_age.sort_values(by=['age','gender'])) #按照年龄、性别字段进行排序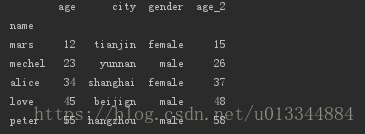
三、数据离散化
简单的离散化话一般有等频分段,等距分段,python cut函数和qcut函数能够实现等距、等频分段。
#离散化
print(pd.cut(df_age['age'],3)) #等距(宽)分段,分为3段
print(pd.qcut(df_age.age_2,3)) #等频(高)分段,分为3段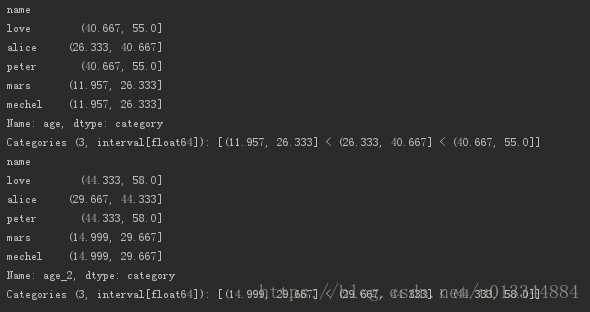
四、其他函数应用
我们可能需要自己定制一些函数,并将它应用到 DataFrame 或 Series。常用到的函数有:map、apply、applymap。
1.map 是 Series 中特有的方法,通过它可以对 Series 中的每个元素实现转换。
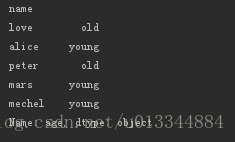
print(df_age.age.map(lambda x:'old' if x > 40 else 'young')) #根据年龄判断为青年还是老年
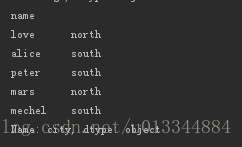
city_map = {
"beijing": "north",
"shanghai": "south",
"hangzhou": "south",
"yunnan": "south",
"tianjin":"north"
}
print(df_age.city.map(city_map)) #根据城市判断南北方输出:
2.apply 方法既支持 Series,也支持 DataFrame,在对 Series 操作时会作用到每个值上,在对 DataFrame 操作时会作用到所有行或所有列(通过 axis 参数控制,默认为列)。
#apply
# 对 Series 来说,apply 方法 与 map 方法区别不大。
print(df_age.age.apply(lambda x:'old' if x > 40 else 'young')) #根据年龄判断为青年还是老年
# 对 DataFrame 来说,apply 方法的作用对象是一行或一列数据(一个Series)默认一列
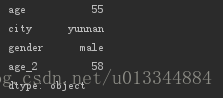
print(df_age.apply(lambda x: x.max(),axis=0))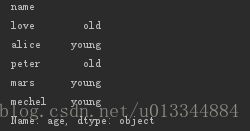
3.applymap 方法针对于 DataFrame,它作用于 DataFrame 中的每个元素,它对 DataFrame 的效果类似于 apply 对 Series 的效果。
#applymap,针对DataFrame,作用于每个元素
print(df_age.applymap(lambda x: str(x).upper()))