课程的所有数据和代码在我的Github:Machine learning in Action,目前刚开始做,有不对的欢迎指正,也欢迎大家star。除了 版本差异,代码里的部分函数以及代码范式也和原书不一样(因为作者的代码实在让人看的别扭,我改过后看起来舒服多了)。在这个系列之后,我还会写一个scikit-learn机器学习系列,因为在实现了源码之后,带大家看看SKT框架如何使用也是非常重要的。
CART是决策树的一种,主要由特征选择,树的生成和剪枝三部分组成。它主要用来处理分类和回归问题,下面对分别对其进行介绍。
1、回归树:使用平方误差最小准则
训练集为:D={(x1,y1), (x2,y2), …, (xn,yn)}。
输出Y为连续变量,将输入划分为M个区域,分别为R1,R2,…,RM,每个区域的输出值分别为:c1,c2,…,cm则回归树模型可表示为:
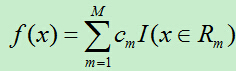
则平方误差为:
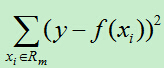
假如使用特征j的取值s来将输入空间划分为两个区域,分别为:

我们需要最小化损失函数,即:
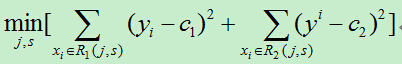
其中c1,c2分别为R1,R2区间内的输出平均值。(此处与统计学习课本上的公式有所不同,在课本中里面的c1,c2都需要取最小值,但是,在确定的区间中,当c1,c2取区间输出值的平均值时其平方会达到最小,为简单起见,故而在此直接使用区间的输出均值。)
为了使平方误差最小,我们需要依次对每个特征的每个取值进行遍历,计算出当前每一个可能的切分点的误差,最后选择切分误差最小的点将输入空间切分为两个部分,然后递归上述步骤,直到切分结束。此方法切分的树称为最小二乘回归树。
最小二乘回归树生成算法:
1)依次遍历每个特征j,以及该特征的每个取值s,计算每个切分点(j,s)的损失函数,选择损失函数最小的切分点。
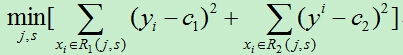
2)使用上步得到的切分点将当前的输入空间划分为两个部分
3)然后将被划分后的两个部分再次计算切分点,依次类推,直到不能继续划分。
4)最后将输入空间划分为M个区域R1,R2,…,RM,生成的决策树为:
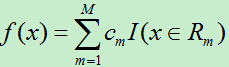
其中cm为所在区域的输出值的平均。
总结:此方法的复杂度较高,尤其在每次寻找切分点时,需要遍历当前所有特征的所有可能取值,假如总共有F个特征,每个特征有N个取值,生成的决策树有S个内部节点,则该算法的时间复杂度为:O(F*N*S)
2、分类树:使用基尼指数最小化准则
基尼指数:假如总共有K类,样本属于第k类的概率为:pk,则该概率分布的基尼指数为:
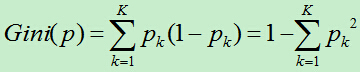
基尼指数越大,说明不确定性就越大。
对于二类分类: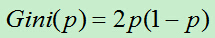
使用特征A=a,将D划分为两部分,即D1(满足A=a的样本集合),D2(不满足A=a的样本集合)。则在特征A=a的条件下D的基尼指数为:
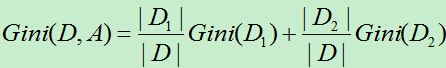
Gini(D):表示集合D的不确定性。
Gini(A,D):表示经过A=a分割后的集合D的不确定性。
CART生成算法:
1)依次遍历每个特征A的可能取值a,对每一个切分点(A, a)计算其基尼指数。
2)选择基尼指数最小的切分点作为最优切分点。然后使用该切分点将当前数据集切分成两个子集。
3)对上步切出的两个子集分别递归调用1)和2),直至满足停止条件。(算法停止的条件是样本个数小于预定阀值,或者样本集的基尼指数小于预定阀值或者没有更多特征)
4)生成CART决策树。
3、CART树剪枝
通过CART刚生成的决策树我们记为T0,然后从T0的底端开始剪枝,直到根节点。在剪枝的过程中,计算损失函数:
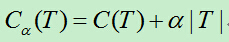
注:参数此处为了方便编辑使用a来表示。a>=0,C(T)为训练数据的预测误差,|T|为模型的复杂度。
对于一个固定的a,在T0中一定存在一颗树Ta使得损失函数Ca(T)最小。也就是每一个固定的a,都存在一颗相应的使得损失函数最小的树。这样不同的a会产生不同的最优树,而我们不知道在这些最优树中,到底哪颗最好,于是我们需要将a在其取值空间内划分为一系列区域,在每个区域都取一个a然后得到相应的最优树,最终选择损失函数最小的最优树。
现在对a取一系列的值,分别为:a0<a1<…<an<+无穷大。产生一系列的区间[ai,ai+1)。在每个区间内取一个值ai,对每个ai,我们可以得到一颗最优树Tai。于是我们得到一个最优树列表{T0,T1,…,Tn}。
那么对于一个固定的a,如何找到最优的子树?现在假如节点t就是一棵树,一颗单节点的树,则其损失函数为:Ca(t)=C(t)+a*1。对于一个以节点t为根节点的树,其损失函数为:Ca(Tt)=C(Tt)+a*|Tt|。当a=0时,即没有剪枝时,Ca(t) > Ca(Tt)。因为使用决策树分类的效果肯定比将所有样本分成一个类的效果要好。即使出现过拟合。
然而,随着a的增大,Ca(t)和Ca(Tt)的大小关系会出现变化(即Ca(t)- Ca(Tt)随着a单调递减。只是猜测,未经证明)。所以会出现Ca(t)= Ca(Tt),即t和Tt有相同的损失函数,而t的节点少,故而选择t。
当Ca(t)= Ca(Tt)时,即:
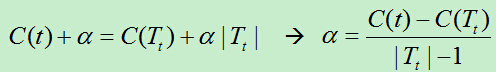
据上分析,在T0中的每个内部节点t,计算a的值,它表示剪枝后整体损失函数减少的程度。在T0中剪去a最小的子树Tt,将得到的新的树记为T1,同时将此a记为a1。即T1为区间[a1,a2)上的最优树。
a与损失函数之间的关系分析:当a=0时,此时未进行任何剪枝,因为产生过拟合,所以损失函数会较大,而随着a的增大,产生的过拟合会慢慢消退,因而,损失函数会慢慢减小,当a增大到某一值时,损失函数会出现一个临界值,因而a超过此临界值继续增大的话损失函数就会因而模型越来越简单而开始增大。所以我们需要找到一个使损失函数最小的临界点a。
如何找到使损失函数最小的a呢?我们通过尝试的方式,依次遍历生成树的每一个内部节点,分别计算剪掉该内部节点和不剪掉该内部节点时的整体损失函数,当这两种情况的损失函数相等时,我们可以得到一个a,此a表示当前需要剪枝的最小a。这样每个内部节点都能计算出一个a。此a表示整体损失函数减少的程度。
那么选择哪个a来对生成树进行剪枝呢?我们选择上面计算出的最小的a来进行剪枝。假如我们选择的不是最小的a进行剪枝的话,则至少存在两处可以剪枝的内部节点,这样剪枝后的损失函数必然会比只剪枝一处的损失要大(这句话表述的可能不准确),为了使得损失函数最小,因而选最小的a来进行剪枝。在选出a之后,我们就需要计算该a对应的使损失函数最小的子树。即从树的根节点出发,逐层遍历每个内部节点,计算每个内部节点处是否需要剪枝。剪枝完之后的树便是我们所需要的树。
代码模块
树节点类
class treeNode():
def __init__(self,feat,val,right,left):
featureToSplitOn=feat
valueOfSplit=val
rightBranch=right
leftBranch=left解析文本数据
#解析文本数据
def loadDatabase(filename):
dataMat=[]
fr=open(filename)
for line in fr.readlines():
curLine=line.strip().split('\t')
#将每行数据映射为浮点数
fltLine=map(float,curLine)
dataMat.append(fltLine)
return dataMat
#拆分数据集函数,二元拆分法
#@dataSet:待拆分的数据集
#@feature:作为拆分点的特征索引
#@value:特征的某一取值作为分割值
def binSplitDataSet(dataSet,feature,value):
#采用条件过滤的方法获取数据集每个样本目标特征的取值大于
#value的样本存入mat0
#左子集列表的第一行
#mat0=dataSet[nonzero(dataSet[:,feature]>value)[0],:][0]
#左子集列表
mat0=dataSet[nonzero(dataSet[:,feature]>value)[0],:]
#同上,样本目标特征取值不大于value的样本存入mat1
mat1=dataSet[nonzero(dataSet[:,feature]<=value)[0],:]
#返回获得的两个列表
return mat0,mat1
#创建树函数
#@dataSet:数据集
#@leafType:生成叶节点的类型 1 回归树:叶节点为常数值 2 模型树:叶节点为线性模型
#@errType:计算误差的类型 1 回归错误类型:总方差=均方差*样本数
# 2 模型错误类型:预测误差(y-yHat)平方的累加和
#@ops:用户指定的参数,包含tolS:容忍误差的降低程度 tolN:切分的最少样本数
def createTree(dataSet,leafType=regLeaf,errType=regErr,ops=(1,4)):
#选取最佳分割特征和特征值
feat,val=chooseBestSplit(dataSet,leafType,errType,ops)
#如果特征为none,直接返回叶节点值
if feat == None:return val
#树的类型是字典类型
retTree={}
#树字典的一个元素是切分的最佳特征
retTree['spInd']=feat
#第二个元素是最佳特征对应的最佳切分特征值
retTree['spval']=val
#根据特征索引及特征值对数据集进行二元拆分,并返回拆分的两个数据子集
lSet,rSet=binSplitDataSet(dataSet,feat,val)
#第三个元素是树的左分支,通过lSet子集递归生成左子树
retTree['left']=createTree(lSet,leafType,errType,ops)
#第四个元素是树的右分支,通过rSet子集递归生成右子树
retTree['right']=createTree(rSet,leafType,errType,ops)
#返回生成的数字典
return retTree切分函数
#回归树的切分函数
#叶节点生成函数
def regLeaf(dataSet):
#数据集列表最后一列特征值的均值作为叶节点返回
return mean(dataSet[:,-1])
#误差计算函数
def regErr(dataSet):
#计算数据集最后一列特征值的均方差*数据集样本数,得到总方差返回
return var(dataSet[:,-1])*shape(dataSet)[0]
#选择最佳切分特征和最佳特征取值函数
#@dataSet:数据集
#@leafType:生成叶节点的类型,默认为回归树类型
#@errType:计算误差的类型,默认为总方差类型
#@ops:用户指定的参数,默认tolS=1.0,tolN=4
def chooseBestSplit(dataSet,leafType=regLeaf,errType=regErr,ops=(1,4)):
#容忍误差下降值1,最少切分样本数4
tolS=ops[0];tolN=ops[1]
#数据集最后一列所有的值都相同
if len(set(dataSet[:,-1].T.tolist()[0])==1):
#最优特征返回none,将该数据集最后一列计算均值作为叶节点值返回
return none,leafType(dataSet))
#数据集的行与列
m,n=shape(dataSet)
#计算未切分前数据集的误差
S=errType(dataSet)
#初始化最小误差;最佳切分特征索引;最佳切分特征值
bestS=inf;bestIndex=0;bestValue=0
#遍历数据集所有的特征,除最后一列目标变量值
for featIndex in range(n-1):
#遍历该特征的每一个可能取值
for splitVal in set(dataSet[:,featIndex]):
#以该特征,特征值作为参数对数据集进行切分为左右子集
mat0,mat1=binSplitDataSet(dataSet,featIndex,splitVal)
#如何左分支子集样本数小于tolN或者右分支子集样本数小于tolN,跳出本次循环
if (shape(mat0)[0]<tolN) or (shape(mat1)[0]<tolN):continue
#计算切分后的误差,即均方差和
newS=errType(mat0)+errType(mat1)
#保留最小误差及对应的特征及特征值
if newS<bestS:
bestIndex=featIndex
bestValue=splitVal
bestS=newS
#如果切分后比切分前误差下降值未达到tolS
if (S-bestS)<tolS:
#不需切分,直接返回目标变量均值作为叶节点
return None,leafType(dataSet)
#检查最佳特征及特征值是否满足不切分条件
mat0,mat1=binSplitDataSet(dataSet,bestIndex,bestValue)
if(shape(mat0)[0]<tolN) or (shape(mat1)[0]<tolN):
return None,leafType(dataSet)
#返回最佳切分特征及最佳切分特征取值
return bestIndex,bestValueCART树剪枝
#后剪枝
#根据目标数据的存储类型是否为字典型,是返回true,否则返回false
def isTree(obj):
return (type(obj).__name__=='dict')
#获取均值函数
def getMean(tree):
#树字典的右分支为字典类型:递归获得右子树的均值
if isTree(tree['right']):tree['right']=getMean(tree['right'])
#树字典的左分支为字典类型:递归获得左子树的均值
if isTree(tree['left']):tree['left']=getMean(tree['left'])
#递归直至找到两个叶节点,求二者的均值返回
return (tree['left']+tree['right'])/2.0
#剪枝函数
#@tree:树字典
#@testData:用于剪枝的测试集
def prune(tree,testData):
#测试集为空,直接对树相邻叶子结点进行求均值操作
if shape(testData)[0]==0:return getMean(tree)
#左右分支中有非叶子结点类型
if (isTree(tree['right']) or isTree(tree['left'])):
#利用当前树的最佳切分点和特征值对测试集进行树构建过程
lSet,rSet=binSplitDataSet(testData,tree['spInd'],tree['spval'])
#左分支非叶子结点,递归利用测试数据的左子集对做分支剪枝
if isTree(tree['left']):tree['left']=prune(tree['left'],lSet)
#同理,右分支非叶子结点,递归利用测试数据的右子集对做分支剪枝
if isTree(tree['right']):tree['right']=prune(tree['right'],lSet)
#左右分支都是叶节点
if not isTree(tree['left']) and ont isTree(tree['right']):
#利用该子树对应的切分点对测试数据进行切分(树构建)
lSet,rSet=binSplitDataSet(testData,tree['spInd'],tree['spval'])
#如果这两个叶节点不合并,计算误差,即(实际值-预测值)的平方和
errorNoMerge=sum(power(lSet[:,-1]-tree['left'],2))+\
sum(rSet[:,-1]-tree['right'],2))
#求两个叶结点值的均值
treeMean=(tree['left']+tree['right'])/2.0
#如果两个叶节点合并,计算合并后误差,即(真实值-合并后值)平方和
errorMerge=sum(power(testData[:,-1]-treeMean,2))
#合并后误差小于合并前误差
if errorMerge<errorNoMerge:
#和并两个叶节点,返回合并后节点值
print('merging')
return treeMean
#否则不合并,返回该子树
else:return tree
#不合并,直接返回树
else:return tree模型叶节点
#模型树叶节点生成函数
def linearSolve(dataSet):
#获取数据行与列数
m,n=shape(dataSet)
#构建大小为(m,n)和(m,1)的矩阵
X=mat(ones((m,n)));Y=mat(ones((m,1)))
#数据集矩阵的第一列初始化为1,偏置项;每个样本目标变量值存入Y
X[:,1:n]=dataSet[:,0:n-1];Y=dataSet[:,-1]
#对数据集矩阵求内积
xTx=X.T*X
#计算行列式值是否为0,即判断是否可逆
if linalg.det(xTx)==0.0:
#不可逆,打印信息
print('This matrix is singular,cannot do inverse,\n\
try increasing the second value if ops')
#可逆,计算回归系数
ws=(xTx).I*(X.T*Y)
#返回回顾系数;数据集矩阵;目标变量值矩阵
return ws,X,Y
#模型树的叶节点模型
def modelLeaf(dataSet):
#调用线性回归函数生成叶节点模型
ws,X,Y=linearSolve(dataSet)
#返回该叶节点线性方程的回顾系数
return ws
#模型树的误差计算函数
def modelErr(dataSet):
#构建模型树叶节点的线性方程,返回参数
ws,X,Y=linearSolve(dataSet)
#利用线性方程对数据集进行预测
yHat=X*ws
#返回误差的平方和,平方损失
return sum(power(y-yHat,2))利用树进行预测
#用树回归进行预测代码
#回归树的叶节点为float型常量
def regTreeEval(model,inDat):
return float(model)
#模型树的叶节点浮点型参数的线性方程
def modelTreeEval(model,inDat):
#获取输入数据的列数
n=shape(inDat)[1]
#构建n+1维的单列矩阵
X=mat(ones((1,n+1)))
#第一列设置为1,线性方程偏置项b
X[:,1:n+1]=inDat
#返回浮点型的回归系数向量
return float(X*model)
#树预测
#@tree;树回归模型
#@inData:输入数据
#@modelEval:叶节点生成类型,需指定,默认回归树类型
def treeForeCast(tree,inData,modelEval=regTreeEval):
#如果当前树为叶节点,生成叶节点
if not isTree(tree):return modelEval(tree,inData)
#非叶节点,对该子树对应的切分点对输入数据进行切分
if inData[tree['spInd']]>tree['spval']:
#该树的左分支为非叶节点类型
if isTree(tree['left']):
#递归调用treeForeCast函数继续树预测过程,直至找到叶节点
return treeForeCast(tree['left'],inData,modelEval)
#左分支为叶节点,生成叶节点
else: return modelEval(tree['left'],inData)
#小于切分点值的右分支
else:
#非叶节点类型
if isTree(tree['right']):
#继续递归treeForeCast函数寻找叶节点
return treeForeCast(tree['right'],inData,modelEval)
#叶节点,生成叶节点类型
else: return modelEval(tree['right'],inData)
#创建预测树
def createForeCast(tree,testData,modelEval=regTreeEval):
#测试集样本数
m=len(testData)
#初始化行向量各维度值为1
yHat=mat(zeros((m,1)))
#遍历每个样本
for i in range(m):
#利用树预测函数对测试集进行树构建过程,并计算模型预测值
yHat[i,0]=treeForeCast(tree,mat(testData[i]),modelEval)
#返回预测值
return yHat原书后面还给了一个可视化的例子,要用到几个Python插件,感兴趣的朋友可以自己照着做一下