首先看看需求:

其实这个也是一个WordCount的问题我们应该这么看问题。比如2,5这条线段就包含(2,1),(3,1),(4,1),(5,1)这几个点。这样就可以按照WordCount的方式去处理问题了。按照这种方式处理完问题之后,我们可以得到重叠的点和次数。
接下来我们需要取出重叠次数最多的前三个点。我们可以将这两个属性封装成一个实体,然后实现WritableComparable接口让他按照我们的排序规则排序。拍完序之后我们还需要取出前三个,这时我们可以在Reducer类中定义一个成员变量,每执行一次reduce方法就让它加一,如果等于三就return这样就只能写入前三个数据。其实我们不一定只取前三个,所以我们最好将这个数值通过args参数进行传递。如果我们要取的话,我们通过context获取,那这个获取的代码放在哪里?放在reduce方法中吗?不对,这样每次执行reduce方法都要取值,没必要的,我们可以在setup方法中获取,这样这个值我们只获取一次就可以了。
以下贴出代码:
package com.test.linecount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LineCount1 {
public static class LineMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>{
IntWritable k = new IntWritable();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
int start = Integer.parseInt(split[0]);
int end = Integer.parseInt(split[1]);
for(int i=start;i<=end;i++){
k.set(i);
context.write(k, v);
}
}
}
public static class LineReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
v.set(count);
context.write(key, v);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LineCount1.class);
job.setMapperClass(LineMapper.class);
job.setReducerClass(LineReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileSystem fs = FileSystem.get(conf);
Path p = new Path(args[1]);
if(fs.exists(p)){
fs.delete(p, true);
}
FileOutputFormat.setOutputPath(job, p);
job.setNumReduceTasks(2);
boolean res = job.waitForCompletion(true);
System.out.println(res?"mr程序成功执行":"mr程序好像被外星人抓走了");
}
}package com.test.linecount;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class Count implements WritableComparable<Count>{
private String point;
private String no;
public String getPoint() {
return point;
}
public void setPoint(String point) {
this.point = point;
}
public String getNo() {
return no;
}
public void setNo(String no) {
this.no = no;
}
public Count() {
super();
// TODO Auto-generated constructor stub
}
public Count(String point, String no) {
super();
this.point = point;
this.no = no;
}
@Override
public String toString() {
return "点:" + point + "次数:" + no;
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.point = in.readUTF();
this.no = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(this.point);
out.writeUTF(this.no);
}
@Override
public int compareTo(Count o) {
// TODO Auto-generated method stub
int one = Integer.parseInt(o.getNo());
int two = Integer.parseInt(this.no);
return one-two==0?o.getPoint().compareTo(this.no):one-two;
}
}package com.test.linecount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LineCount2 {
public static class lineMapper extends Mapper<LongWritable, Text, Count, NullWritable>{
Count c = new Count();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\t");
c.setPoint(split[0]);
c.setNo(split[1]);
context.write(c, NullWritable.get());
}
}
public static class lineReducer extends Reducer<Count, NullWritable, Count, NullWritable>{
int count = 0;
@Override
protected void reduce(Count key, Iterable<NullWritable> values,Context context) throws IOException, InterruptedException {
if(count==3) return;
count++;
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LineCount2.class);
job.setMapperClass(lineMapper.class);
job.setReducerClass(lineReducer.class);
job.setMapOutputKeyClass(Count.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Count.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileSystem fs = FileSystem.get(conf);
Path p = new Path(args[1]);
if(fs.exists(p)){
fs.delete(p,true);
}
FileOutputFormat.setOutputPath(job, p);
job.setNumReduceTasks(1);
boolean res = job.waitForCompletion(true);
System.out.println(res?"mr程序成功执行":"mr程序好像被外星人抓走了");
}
}
程序一运行截图:

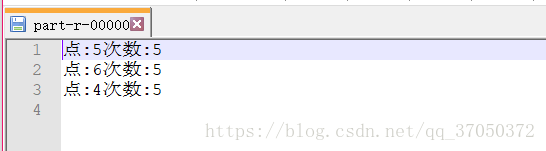
程序二运行截图: