数据集如下:
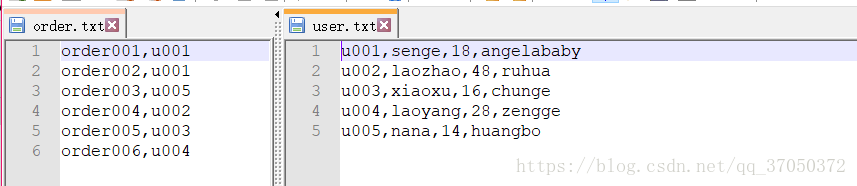
任务为:将两个文档通过用户id相同的进行合并
思路:将两个文档的内容合并为一个实体,实体中再加一个用户与订单区分的字段,在map阶段使用uid做为key,我们可以通过context拿到FileSplit,再通过FileSplit得到文件名,通过文件名区分用户数据与订单数据。经过map阶段uid相同的肯定会被分配到同一个区。到了reduce阶段,这里的数据都是用户id相同的用户数据与订单数据,我们首先要做的是将用户数据与订单数据分开。这里一定要注意,我们在遍历的时候是使用迭代器遍历的,迭代器中的value其实每次都是同一个对象,只是被worker重新赋值而已。之后我们要做的就是,遍历订单数据,将用户数据与订单数据进行合并。
以下贴出代码:
package com.test.user_order;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class Entity implements Writable{
private String oid;
private String uid;
private String name;
private Integer age;
private String love;
private String table;
public String getTable() {
return table;
}
public void setTable(String table) {
this.table = table;
}
@Override
public String toString() {
return oid+","+uid+","+name+","+age+","+love;
}
public void set(String oid, String uid, String name, Integer age, String love,String table) {
this.oid = oid;
this.uid = uid;
this.name = name;
this.age = age;
this.love = love;
this.table = table;
}
public String getOid() {
return oid;
}
public void setOid(String oid) {
this.oid = oid;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getLove() {
return love;
}
public void setLove(String love) {
this.love = love;
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.oid = in.readUTF();
this.uid = in.readUTF();
this.name = in.readUTF();
this.age = in.readInt();
this.love = in.readUTF();
this.table = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(this.oid);
out.writeUTF(this.uid);
out.writeUTF(this.name);
out.writeInt(this.age);
out.writeUTF(this.love);
out.writeUTF(this.table);
}
}
package com.test.user_order;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class UMapper extends Mapper<LongWritable, Text, Text, Entity>{
Text t = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String name = inputSplit.getPath().getName();
String line = value.toString();
String[] split = line.split(",");
Entity entity = new Entity();
if(name.startsWith("order")){
t.set(split[1]);
entity.set(split[0], split[1], "", -1, "","t_order");
context.write(t, entity);
}else{
t.set(split[0]);
entity.set("", split[0], split[1], Integer.parseInt(split[2]), split[3], "t_user");
context.write(t, entity);
}
}
}package com.test.user_order;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class UReducer extends Reducer<Text, Entity, Entity, NullWritable>{
@Override
protected void reduce(Text key, Iterable<Entity> values, Context context)
throws IOException, InterruptedException {
ArrayList<Entity> list = new ArrayList<Entity>();
Entity userBean = new Entity();
//这一步的目的是将用户与订单分开
for (Entity value : values) {
if(value.getTable().equals("t_order")){
/**
* 这里我们不能直接将value添加到list中,
* 因为这里的value始终是一个对象,这样添加进去的话
* 值会变的都一样
*/
Entity e = new Entity();
e.set(value.getOid(),value.getUid(), "", -1, "", "t_order");
list.add(e);
}else{
userBean.set("", value.getUid(), value.getName(), value.getAge(), value.getLove(), "t_user");
}
}
//分开之后,就可以遍历订单,将订单与用户合并
for (Entity entity : list) {
userBean.setOid(entity.getOid());
context.write(userBean, NullWritable.get());
}
}
}package com.test.user_order;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(UMapper.class);
job.setReducerClass(UReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Entity.class);
job.setOutputKeyClass(Entity.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileSystem fs = FileSystem.get(conf);
Path p = new Path(args[1]);
if(fs.exists(p)){
fs.delete(p,true);
}
FileOutputFormat.setOutputPath(job,p);
job.setNumReduceTasks(1);
boolean res = job.waitForCompletion(true);
System.out.println(res?"mr程序成功执行":"mr程序好像被外星人抓走了");
}
}运行成功截图:
