Linking Image and Text with 2-Way Nets
CVPR 2017
这篇文章可以为Corr-AE中的Corr-Cross-AE结构的一种拓展,另外文章中加入了很多的技巧和约束,且都有理论上的证明。 在介绍这篇文章之前,先回顾一下Corr-Cross-AE结构。
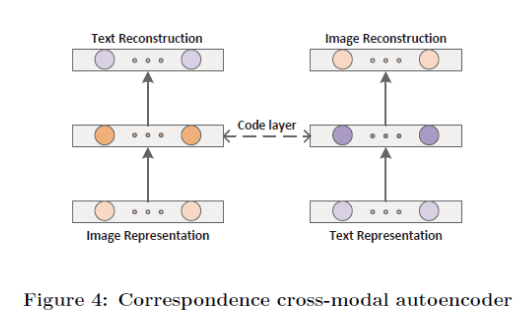
1.文本和图像特征分别通过encoder映射到共同空间,然后用L2计算文本和图像之间相似性,得到correlation loss 2.将共同空间的文本decoder出来的特征与原图像特征做L2,而共享空间的图像decoder出来的特征与原文本做L2,得到representation loss 3.用两个和为1的超参数将两个correlation loss和representation loss相加
一、Introduction
文章提出了双向神经网络架构,匹配来自两个数据源的向量。采用两个绑定的神经网络通道,使用欧几里德损失将两个模态向量投影到一个共同的、最大相关的空间。
引入网络技巧:
-
Batch Normalization
-
Leaky ReLU
-
Locally Dense Layer(将维度大的向量分成几个维度小的向量)
-
Tied Dropout(乘每个元素都服从伯努利分布的随机矩阵,并引入尺度因子根号下0.5)
二、Model
两个数据源:visual data X 和external data source Y
图像特征:VGG得到4096维特征
文本特征:Fisher Vector 18000(GMM)+18000(HGLMM)=36000维特征
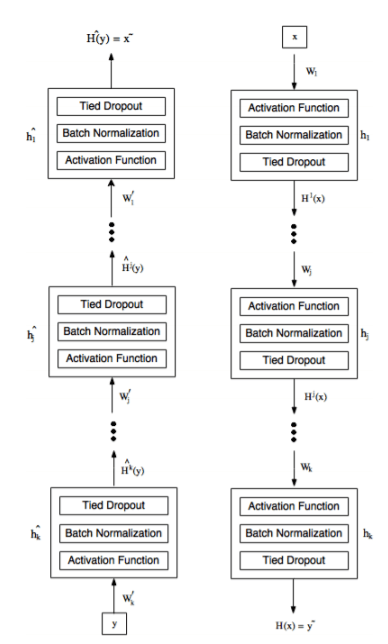
双向网络结构:每个通道将一个视图转化为另一个视图,提取中间特征使相似度最大。
两个通道分别为(如上图):
图像→文本:4096→2000→3000→2000→36000
文本→图像:36000→2000→3000→2000→4096
选择中间层:
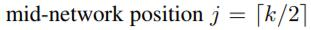
三、损失函数
文章是6个损失函数的叠加
分别为:
1.两端用 L2
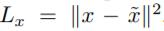

2.中间层 j 用 L2
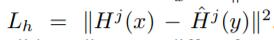
3.中间层用decorrelation regularization
4.全连接层中的参数做weight decay
5.对Batch Normalization中尺度参数做regularization
最后Loss Function为:
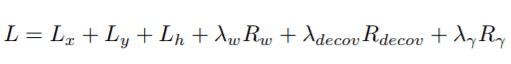
四、总结
-
采用双向网络结构,与大多数方法不同,使用欧几里德损失。
-
引入了一系列技巧和约束。
具体公式见文章。