为什么有有hive ?
便于一些不会java的人对HDFS上的数据执行MapReduec操作。
Hive是一种数据仓库
HIVE: 解释器 编译器 优化器 sql ——》执行计划
Hive运行时,元数据储存在关系型数据库里
Hive不支持事物,非实时,不支持行级别的CRUD。因为HDFS不支持
数据库:业务数据。 三大范式,减少冗余。给业务系统支撑
数据仓库:历史数据。HDFS 引入冗余,保证数据安全,面向分析
元数据:描述数据的数据(表的属性,字段)存储在关系型数据库里(mysql)(derby自带)
架构图 hadoop2.0以后把 job tracker 改为 resourcemanager

连接hive的三种方式
1 cli 命令行
2 jdbc、odbc 通过thrift协议连接
3 web gui
4 流行工具 hue
Hive架构 : 编译器将一个hive ql 转化成一个操作符
操作符是hive的最小处理单元
每个操作符代表HDFS上的一个操作或者一个MapReduce作业
操作符源码是一种树型结构
Hive语法解析
hive采用antlr词法语法解析工具解析hql
parser 将HQL转换成抽象语法树
semantic analyzer 将抽象语法树转化成查询块
logic plan generate 将查询块转化成逻辑查询计划
logical optimizer 重写逻辑查询计划
physical plan generator 将逻辑计划转化成物理执行计划 (mr jobs)
physical optimizer 选择最佳执行策略
Hive三种模式
1 local 模式
采用自带的derby数据库存储元数据
2 单用户模式
采用mysql 存储元数据
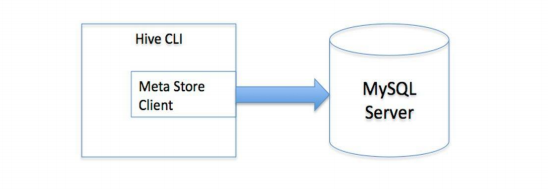
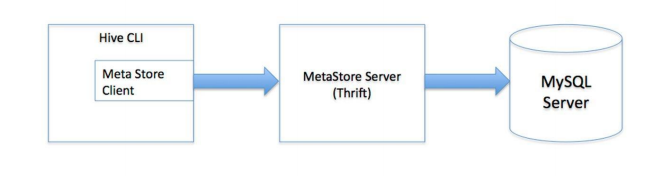
3 多用户模式
用户非java客户端访问元数据数据库,在服务器端启动metastoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库
<name>hive.metastore.warehouse.dir</name>
这个文件夹在hdfs上存的是表的具体数据
表的元数据信息存在mysql里对应数据库里有两个表:TBLS里的TBL_ID字段对应columns_2的CD_ID字段
hive里有一种hql不转化成mr job
包含* 的查询 ,select * from zxy;
select id from zxy;