版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/uagvdu/article/details/78951568
一: 初始MySQL;

个人对库和表的大概的见解:
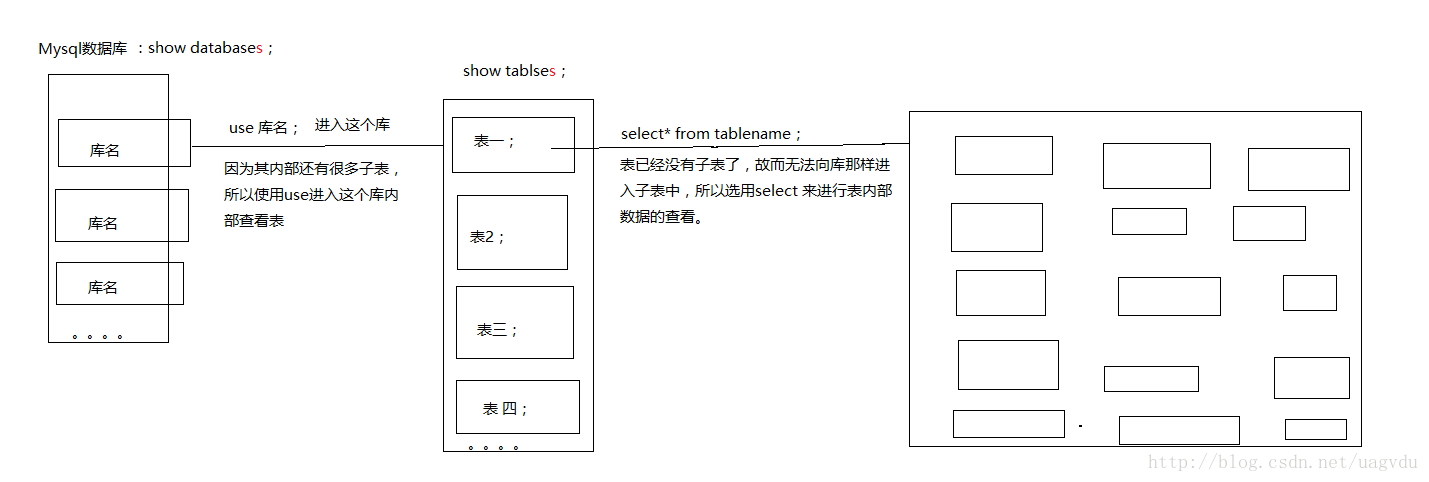
二: 库操作: drop 代表删除 ; use 代表进入
创建库:create database 库名;
删除库: drop database 库名;
进入库: use 库名;
查看当前进入的是哪个库 : select database();
三: 表操作: INSERT INTO 代表插入。
0. 建表: 需要四个信息: 表名,表字段名,定义每个表字段,语法
1. CREATE TABLE table_name (column_name column_type);
例子: CREATE TABLE learn(name VARCHAR(40) NOT NULL,ages VARCHAR(40), id INT NOT NULL ,PRIMARY KEY(ID));
1. 查:select
查看表内部的全部数据内容 : select * from 表名; // 也可以只查询一个列的内容,* 改为列名
查看表头和其类型等非内部数据的内容: desc 表名;
例子:CREATE TABLE log(name VARCHAR(100)NOT NULL,ages int NOT NULL,ID INT NOT NULL AUTO_INCREMENT,PRIMARY KEY(ID));;
2. 增: INSERT INTO
插入数据: INSERT INTO
例子: INSERT INTO table_name(filed1,filed2,filed3.。。)VALUES(value1,value2,value3.。。); 若数据是字符类型数据则需要使用‘’或者“”。
AUTO_INCREMENT(自动增加) 属性 : 所以就没有必要为该字段的ID赋值。
例子: INSERT * from table_name;
3. 删: DELETE FROM
DELETE FROM table_name [WHERE 语句] ;
如果没有指定 WHERE 子句,MySQL表中的所有记录将被删除。
4. 改: update;
UPDATE table_name SET field1 = new-value1, field2=new-value2;
这样的缺点是一次性会把field的变量全部更新成一样的,
改进方法: 使用where 来进行条件判断,它的功能很强大,可以让你进行各种各样的条件设置
UPDATE table_name SET field1 = new-value1, field2=new-value2 where ID = 2;
四: 附注:
* 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
* SELECT 命令可以读取一条或者多条记录。
* 你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
* 你可以使用 WHERE 语句来包含任何条件。
* 你可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
* 你可以使用 LIMIT 属性来设定返回的记录数。
五: 使用C++插入变量内容到数据库中的时候:
可以利用sprintf函数来格式化到某一个缓冲区中,然后mysql_query(conn,buf); 来进行mysql语句的使用。