刚升研究生,导师要我们研究机器学习算法,看到了贝叶斯算法,刚入手看了蛮长时间的,算是有些收获了,故拿出来分享。
有些内容是转载其他作者的,链接:https://www.jianshu.com/p/f6a3f3200689
贝叶斯分类器的工作原理###
还是需要了解一定的理论知识的,别担心,这部分很快就过去。我会直接结合要解决的问题来讲解。
基本上,用贝叶斯分类是要解决一个这样的问题:已知一本书有这些tag:tag1,tag2,tag3......它属于“人文”分类的概率是多少?属于“非人文”分类的概率呢?
假设p1表示在这种情况下,它属于“人文”的概率,p2表示这种情况下,它属于“非人文”的概率。
如果p1>p2,那么这本书就属于“人文”,反过来就是“非人文”。我们不考虑p1=p2的情况。
很简单,不是么?
所以,问题就变成了,如何通过tag1,tag2,tag3...来计算p1和p2?毕竟,只要知道了这两个值,我们的最终问题就解决了。
条件概率###
其实,这是一个条件概率的问题。所谓条件概率,就是求:在已知b发生的情况下,a发生的概率。我们写做:p(a|b)。
结合我们的实际问题,那就是在tag1,tag2,tag3...已经发生的情况下(也就是这本书的tag就是tag1,tag2,tag3...),这本书属于“人文”和“非人文”的概率。我们写做:
p(cate1|tag1,tag2,tag3...) 意思是在tag1,tag2,tag3...发生的情况下,这本书属于cate1的概率(cate1=“人文”)
p(cate2|tag1,tag2,tag3...) 意思是在tag1,tag2,tag3...发生的情况下,这本书属于cate2的概率(cate2=“非人文”)
这里的p(cate1|tag1,tag2,tag3...)其实就是上面说的p1,我们这里用更为专业的方法来写。
条件概率怎么求呢?这就是贝叶斯公式:
p(a|b) = p(b|a) * p(a) / p(b)
这个意思就是:想要求p(a|b),而你又知道p(b|a),p(a)和p(b)的值,那你就可以通过p(b|a)*p(a)/p(b)来求得p(a|b)。
换成我们要解决的实际问题,等于:
p(cate1|tag1,tag2,tag3...) = p(tag1,tag2,tag3...|cate1) * p(cate1) / p(tag1,tag2,tag3...)
翻译为人话,那就是你想求p(cate1|tag1,tag2,tag3...),而你现在知道:
- p(tag1,tag2,tag3...|cate1)的值,也就是你知道在一本书已经被分类为“人文”的情况下,tag1,tag2,tag3...一起出现的概率
- p(cate1),也就是所有被标记为“人文”分类的书,(在训练集中)在所有书(“人文”和“非人文”)中出现的概率
- p(tag1,tag2,tag3...),也就是tag1,tag2,tag3...(在训练集)所有tag中出现的概率
也就是说,我们只要挨个求出上述3项,我们就可以求出p(cate1|tag1,tag2,tag3...)了。同样,p(cate2|tag1,tag2,tag3...)也可以求出。
这里有个值得注意的技巧,上述3项中,其实第3项不需要我们计算。因为我们的目的是比较p(cate1|tag1,tag2,tag3...)与p(cate2|tag1,tag2,tag3...)的大小,不是为了得到实际的值,由于上述公式里的分母p(tag1,tag2,tag3...)是一样的,所以,我们只需要比较分子的大小就可以了。也就是比较:
p(tag1,tag2,tag3...|cate1) * p(cate1),
与p(tag1,tag2,tag3...|cate2) * p(cate2)的大小
这样可以省去我们一些计算。
朴素贝叶斯###
那么,如何计算p(tag1,tag2,tag3...|cate1)呢?这里要用到朴素贝叶斯的概念,就是说,我们认为,在一本书中的标签里,每个标签都是相互独立的,与对方是否出现没有关系。也就是说“计算机”和“经典”出现的概率互不相关,不会因为“计算机”出现了就导致“经典”出现的概率高。
既然是相互独立,那么,p(tag1,tag2,tag3...|cate1)就等于:
p(tag1|cate1) x p(tag2|cate1) x p(tag3|cate1) x ...
p(tag1,tag2,tag3...|cate2)就等于:
p(tag1|cate2) x p(tag2|cate2) x p(tag3|cate2) x ...
也就是说,我们可以计算每一个tag,分别在“人文”和“非人文”书籍的所有tag中出现的概率,然后将它们乘起来,就得到我们想要的。
举例分析###
我们现在有一本书《计算机科学导论》,它的标签是“计算机”“科学”“理论”“经典”“导论”,我们想知道在这几个标签出现的情况下,《计算机科学导论》分别属于“人文”和“非人文”的概率。
那么,我们已经有了什么呢?幸运的是,我们目前手头有10本书,已知其中6本是“人文”,4本是“非人文”。这10本书,经过排重,一共有70个不同的标签,“计算机”,“科学”,“理论”,“导论”也在其中。
基于此,我们可以得出,p(cate1)=6/10=0.6,p(cate2)=1-0.6=0.4。也就是说“人文”书在所有书中的概率是0.6,“非人文”是0.4。
接下来就是p(tag1,tag2,tag3...|cate1)和p(tag1,tag2,tag3...|cate2)了。也就是,我们要算出,在“人文”类里的所有书中,“计算机”“科学”“理论”“经典”“导论”这几个tag在“人文”书的所有tag里出现的概率。同样,我们还要算出,在“非人文”类里的所有书中,上述这几个tag在所有“非人文”书中的所有tag里出现的概率。计算的方法,就是将每个tag在“人文”和“非人文”中出现的概率,相乘,然后再分别乘以0.6和0.4。
然后比较一下大小就可以了。也就是比较p(cate1) x p(tag1,tag2,tag3...|cate1)与p(cate2) x p(tag1,tag2,tag3...|cate2)的大小。
二,朴素贝叶斯完成文档分类
朴素贝叶斯的一个非常重要的应用就是文档分类。在文档分类中,整个文档(比如一封电子邮件)是实例,那么邮件中的单词就可以定义为特征。说到这里,我们有两种定义文档特征的方法。一种是词集模型,另外一种是词袋模型。顾名思义,词集模型就是对于一篇文档中出现的每个词,我们不考虑其出现的次数,而只考虑其在文档中是否出现,并将此作为特征;假设我们已经得到了所有文档中出现的词汇列表,那么根据每个词是否出现,就可以将文档转为一个与词汇列表等长的向量。而词袋模型,就是在词集模型的基础上,还要考虑单词在文档中出现的次数,从而考虑文档中某些单词出现多次所包含的信息。
好了,讲了关于文档分类的特征描述之后,我们就可以开始编代码,实现具体的文本分类了
1 拆分文本,准备数据
要从文本中获取特征,显然我们需要先拆分文本,这里的文本指的是来自文本的词条,每个词条是字符的任意组合。词条可以为单词,当然也可以是URL,IP地址或者其他任意字符串。将文本按照词条进行拆分,根据词条是否在词汇列表中出现,将文档组成成词条向量,向量的每个值为1或者0,其中1表示出现,0表示未出现。
接下来,以在线社区的留言为例。对于每一条留言进行预测分类,类别两种,侮辱性和非侮辱性,预测完成后,根据预测结果考虑屏蔽侮辱性言论,从而不影响社区发展。
词表到向量的转换函数

#---------------------------从文本中构建词条向量------------------------- #1 要从文本中获取特征,需要先拆分文本,这里特征是指来自文本的词条,每个词 #条是字符的任意组合。词条可以理解为单词,当然也可以是非单词词条,比如URL #IP地址或者其他任意字符串 # 将文本拆分成词条向量后,将每一个文本片段表示为一个词条向量,值为1表示出现 #在文档中,值为0表示词条未出现 #导入numpy from numpy import * def loadDataSet(): #词条切分后的文档集合,列表每一行代表一个文档 postingList=[['my','dog','has','flea',\ 'problems','help','please'], ['maybe','not','take','him',\ 'to','dog','park','stupid'], ['my','dalmation','is','so','cute', 'I','love','him'], ['stop','posting','stupid','worthless','garbage'], ['my','licks','ate','my','steak','how',\ 'to','stop','him'], ['quit','buying','worthless','dog','food','stupid']] #由人工标注的每篇文档的类标签 classVec=[0,1,0,1,0,1] return postingList,classVec #统计所有文档中出现的词条列表 def createVocabList(dataSet): #新建一个存放词条的集合 vocabSet=set([]) #遍历文档集合中的每一篇文档 for document in dataSet: #将文档列表转为集合的形式,保证每个词条的唯一性 #然后与vocabSet取并集,向vocabSet中添加没有出现 #的新的词条 vocabSet=vocabSet|set(document) #再将集合转化为列表,便于接下来的处理 return list(vocabSet) #根据词条列表中的词条是否在文档中出现(出现1,未出现0),将文档转化为词条向量 def setOfWords2Vec(vocabSet,inputSet): #新建一个长度为vocabSet的列表,并且各维度元素初始化为0 returnVec=[0]*len(vocabSet) #遍历文档中的每一个词条 for word in inputSet: #如果词条在词条列表中出现 if word in vocabSet: #通过列表获取当前word的索引(下标) #将词条向量中的对应下标的项由0改为1 returnVec[vocabSet.index(word)]=1 else: print('the word: %s is not in my vocabulary! '%'word') #返回inputet转化后的词条向量 return returnVec
需要说明的是,上面函数creatVocabList得到的是所有文档中出现的词汇列表,列表中没有重复的单词,每个词是唯一的。
2 由词向量计算朴素贝叶斯用到的概率值
这里,如果我们将之前的点(x,y)换成词条向量w(各维度的值由特征是否出现的0或1组成),在这里词条向量的维度和词汇表长度相同。
p(ci|w)=p(w|ci)*p(ci)/p(w)
我们将使用该公式计算文档词条向量属于各个类的概率,然后比较概率的大小,从而预测出分类结果。
具体地,首先,可以通过统计各个类别的文档数目除以总得文档数目,计算出相应的p(ci);然后,基于条件独立性假设,将w展开为一个个的独立特征,那么就可以将上述公式写为p(w|ci)=p(w0|ci)*p(w1|ci)*...p(wN|ci),这样就很容易计算,从而极大地简化了计算过程。
函数的伪代码为:
计算每个类别文档的数目
计算每个类别占总文档数目的比例
对每一篇文档:
对每一个类别:
如果词条出现在文档中->增加该词条的计数值#统计每个类别中出现的词条的次数
增加所有词条的计数值#统计每个类别的文档中出现的词条总数
对每个类别:
将各个词条出现的次数除以类别中出现的总词条数目得到条件概率
返回每个类别各个词条的条件概率和每个类别所占的比例
代码如下:
#训练算法,从词向量计算概率p(w0|ci)...及p(ci) #@trainMatrix:由每篇文档的词条向量组成的文档矩阵 #@trainCategory:每篇文档的类标签组成的向量 def trainNB0(trainMatrix,trainCategory): #获取文档矩阵中文档的数目 numTrainDocs=len(trainMatrix) #获取词条向量的长度 numWords=len(trainMatrix[0]) #所有文档中属于类1所占的比例p(c=1) pAbusive=sum(trainCategory)/float(numTrainDocs) #创建一个长度为词条向量等长的列表 p0Num=zeros(numWords);p1Num=zeros(numWords) p0Denom=0.0;p1Denom=0.0 #遍历每一篇文档的词条向量 for i in range(numTrainDocs): #如果该词条向量对应的标签为1 if trainCategory[i]==1: #统计所有类别为1的词条向量中各个词条出现的次数 p1Num+=trainMatrix[i] #统计类别为1的词条向量中出现的所有词条的总数 #即统计类1所有文档中出现单词的数目 p1Denom+=sum(trainMatrix[i]) else: #统计所有类别为0的词条向量中各个词条出现的次数 p0Num+=trainMatrix[i] #统计类别为0的词条向量中出现的所有词条的总数 #即统计类0所有文档中出现单词的数目 p0Denom+=sum(trainMatrix[i]) #利用NumPy数组计算p(wi|c1) p1Vect=p1Num/p1Denom #为避免下溢出问题,后面会改为log() #利用NumPy数组计算p(wi|c0) p0Vect=p0Num/p0Denom #为避免下溢出问题,后面会改为log() return p0Vect,p1Vect,pAbusive
3 针对算法的部分改进
1)计算概率时,需要计算多个概率的乘积以获得文档属于某个类别的概率,即计算p(w0|ci)*p(w1|ci)*...p(wN|ci),然后当其中任意一项的值为0,那么最后的乘积也为0.为降低这种影响,采用拉普拉斯平滑,在分子上添加a(一般为1),分母上添加ka(k表示类别总数),即在这里将所有词的出现数初始化为1,并将分母初始化为2*1=2
#p0Num=ones(numWords);p1Num=ones(numWords) #p0Denom=2.0;p1Denom=2.0
2)解决下溢出问题
正如上面所述,由于有太多很小的数相乘。计算概率时,由于大部分因子都非常小,最后相乘的结果四舍五入为0,造成下溢出或者得不到准确的结果,所以,我们可以对成绩取自然对数,即求解对数似然概率。这样,可以避免下溢出或者浮点数舍入导致的错误。同时采用自然对数处理不会有任何损失。
#p0Vect=log(p0Num/p0Denom);p1Vect=log(p1Num/p1Denom)
下面是朴素贝叶斯分类函数的代码:
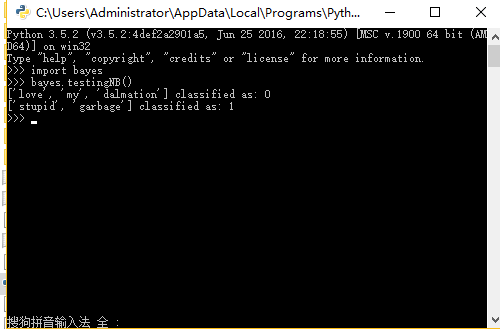
#朴素贝叶斯分类函数 #@vec2Classify:待测试分类的词条向量 #@p0Vec:类别0所有文档中各个词条出现的频数p(wi|c0) #@p0Vec:类别1所有文档中各个词条出现的频数p(wi|c1) #@pClass1:类别为1的文档占文档总数比例 def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1): #根据朴素贝叶斯分类函数分别计算待分类文档属于类1和类0的概率 p1=sum(vec2Classify*p1Vec)+log(pClass1) p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1) if p1>p0: return 1 else: return 0 #分类测试整体函数 def testingNB(): #由数据集获取文档矩阵和类标签向量 listOPosts,listClasses=loadDataSet() #统计所有文档中出现的词条,存入词条列表 myVocabList=createVocabList(listOPosts) #创建新的列表 trainMat=[] for postinDoc in listOPosts: #将每篇文档利用words2Vec函数转为词条向量,存入文档矩阵中 trainMat.append(setOfWords2Vec(myVocabList,postinDoc))\ #将文档矩阵和类标签向量转为NumPy的数组形式,方便接下来的概率计算 #调用训练函数,得到相应概率值 p0V,p1V,pAb=trainNB0(array(trainMat),array(listClasses)) #测试文档 testEntry=['love','my','dalmation'] #将测试文档转为词条向量,并转为NumPy数组的形式 thisDoc=array(setOfWords2Vec(myVocabList,testEntry)) #利用贝叶斯分类函数对测试文档进行分类并打印 print(testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb)) #第二个测试文档 testEntry1=['stupid','garbage'] #同样转为词条向量,并转为NumPy数组的形式 thisDoc1=array(setOfWords2Vec(myVocabList,testEntry1)) print(testEntry1,'classified as:',classifyNB(thisDoc1,p0V,p1V,pAb))
这里需要补充一点,上面也提到了关于如何选取文档特征的方法,上面用到的是词集模型,即对于一篇文档,将文档中是否出现某一词条作为特征,即特征只能为0不出现或者1出现;然后,一篇文档中词条的出现次数也可能具有重要的信息,于是我们可以采用词袋模型,在词袋向量中每个词可以出现多次,这样,在将文档转为向量时,每当遇到一个单词时,它会增加词向量中的对应值
具体将文档转为词袋向量的代码为:
def bagOfWords2VecMN(vocabList,inputSet): #词袋向量 returnVec=[0]*len(vocabList) for word in inputSet: if word in vocabList: #某词每出现一次,次数加1 returnVec[vocabList.index(word)]+=1 return returnVec
程序运行结果:
三,实例:朴素贝叶斯的另一个应用--过滤垃圾邮件
1 切分数据
对于一个文本字符串,可以使用python的split()方法对文本进行切割,比如字符串'hello, Mr.lee.',分割结果为['hell0,','Mr.lee.'] 这样,标点符合也会被当成词的一部分,因为此种切割方法是基于词与词之间的空格作为分隔符的
此时,我们可以使用正则表达式来切分句子,其中分割符是除单词和数字之外的其他任意字符串,即
import re
re.compile('\\W*')
这样就得到了一系列词组成的词表,但是里面的空字符串还是需要去掉,此时我们可以通过字符的长度,去掉长度等于0的字符。并且,由于我们是统计某一词是否出现,不考虑其大小写,所有还可以将所有词转为小写字符,即lower(),相应的,转为大写字符为upper()
此外,需要注意的是,由于是URL,因而可能会出现en和py这样的单词。当对URL进行切分时,会得到很多的词,因此在实现时也会过滤掉长度小于3的词。当然,也可以根据自己的实际需要来增加相应的文本解析函数。
2 具体代码如下:
#贝叶斯算法实例:过滤垃圾邮件 #处理数据长字符串 #1 对长字符串进行分割,分隔符为除单词和数字之外的任意符号串 #2 将分割后的字符串中所有的大些字母变成小写lower(),并且只 #保留单词长度大于3的单词 def testParse(bigString): import re listOfTokens=re.split(r'\W*',bigString) return [tok.lower() for tok in listOPosts if len(tok)>2] def spamTest(): #新建三个列表 docList=[];classList=[];fullTest=[] #i 由1到26 for i in range(1,26): #打开并读取指定目录下的本文中的长字符串,并进行处理返回 wordList=testParse(open('email/spam/%d.txt' %i).read()) #将得到的字符串列表添加到docList docList.append(wordList) #将字符串列表中的元素添加到fullTest fullTest.extend(wordList) #类列表添加标签1 classList.append(1) #打开并取得另外一个类别为0的文件,然后进行处理 wordList=testParse(open('email/ham/&d.txt' %i).read()) docList.append(wordList) fullTest.extend(wordList) classList.append(0) #将所有邮件中出现的字符串构建成字符串列表 vocabList=createVocabList(docList) #构建一个大小为50的整数列表和一个空列表 trainingSet=range(50);testSet=[] #随机选取1~50中的10个数,作为索引,构建测试集 for i in range(10): #随机选取1~50中的一个整型数 randIndex=int(random.uniform(0,len(trainingSet))) #将选出的数的列表索引值添加到testSet列表中 testSet.append(trainingSet[randIndex]) #从整数列表中删除选出的数,防止下次再次选出 #同时将剩下的作为训练集 del(trainingSet[randIndex]) #新建两个列表 trainMat=[];trainClasses=[] #遍历训练集中的吗每个字符串列表 for docIndex in trainingSet: #将字符串列表转为词条向量,然后添加到训练矩阵中 trainMat.append(setOfWords2Vec(vocabList,fullTest[docIndex])) #将该邮件的类标签存入训练类标签列表中 trainClasses.append(classList[docIndex]) #计算贝叶斯函数需要的概率值并返回 p0V,p1V,pSpam=trainNB0(array(trainMat),array(trainClasses)) errorCount=0 #遍历测试集中的字符串列表 for docIndex in testSet: #同样将测试集中的字符串列表转为词条向量 wordVector=setOfWords2Vec(vocabList,docList[docIndex]) #对测试集中字符串向量进行预测分类,分类结果不等于实际结果 if classifyNB(array(wordVector),p0V,p1V,pSpam)!=classList[docIndex]: errorCount+=1 print('the error rate is:',float(errorCount)/len(testSet))
代码中,采用随机选择的方法从数据集中选择训练集,剩余的作为测试集。这种方法的好处是,可以进行多次随机选择,得到不同的训练集和测试集,从而得到多次不同的错误率,我们可以通过多次的迭代,求取平均错误率,这样就能得到更准确的错误率。这种方法称为留存交叉验证